 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Crash Once: Improved Object Detection for Real-Time, Sim-to-Real Hazardous Terrain Detection and Classification for Autonomous Planetary Landings
Mar 08, 2023
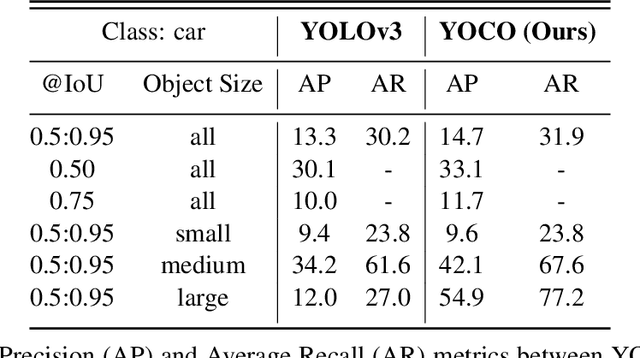

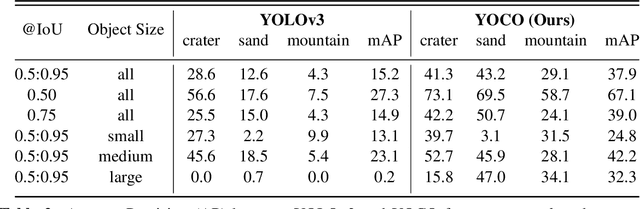
The detection of hazardous terrain during the planetary landing of spacecraft plays a critical role in assuring vehicle safety and mission success. A cheap and effective way of detecting hazardous terrain is through the use of visual cameras, which ensure operational ability from atmospheric entry through touchdown. Plagued by resource constraints and limited computational power, traditional techniques for visual hazardous terrain detection focus on template matching and registration to pre-built hazard maps. Although successful on previous missions, this approach is restricted to the specificity of the templates and limited by the fidelity of the underlying hazard map, which both require extensive pre-flight cost and effort to obtain and develop. Terrestrial systems that perform a similar task in applications such as autonomous driving utilize state-of-the-art deep learning techniques to successfully localize and classify navigation hazards. Advancements in spacecraft co-processors aimed at accelerating deep learning inference enable the application of these methods in space for the first time. In this work, we introduce You Only Crash Once (YOCO), a deep learning-based visual hazardous terrain detection and classification technique for autonomous spacecraft planetary landings. Through the use of unsupervised domain adaptation we tailor YOCO for training by simulation, removing the need for real-world annotated data and expensive mission surveying phases. We further improve the transfer of representative terrain knowledge between simulation and the real world through visual similarity clustering. We demonstrate the utility of YOCO through a series of terrestrial and extraterrestrial simulation-to-real experiments and show substantial improvements toward the ability to both detect and accurately classify instances of planetary terrain.
Total Least Squares for Optimal Pose Estimation
Jun 22, 2021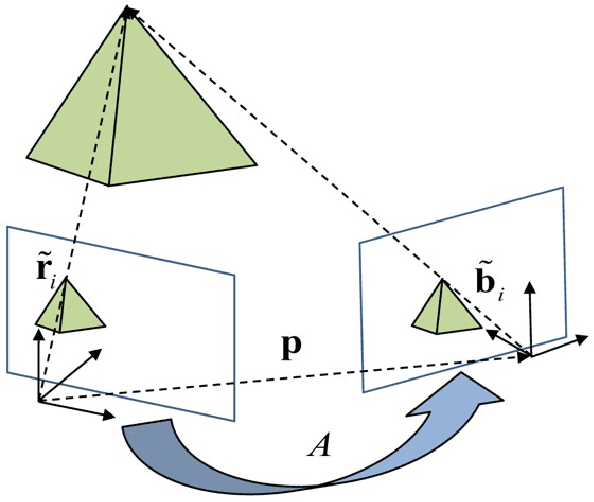
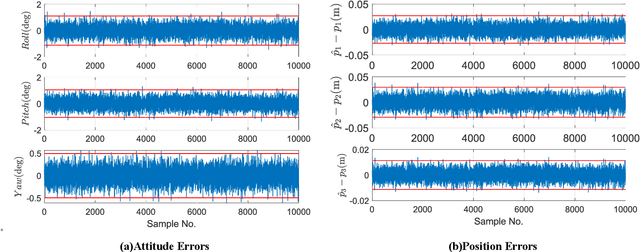
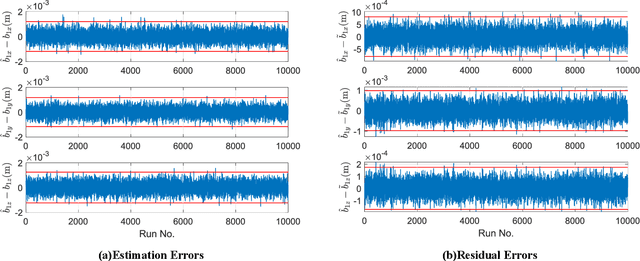
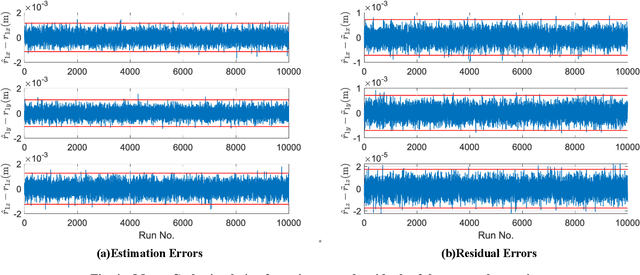
This work provides a theoretical framework for the pose estimation problem using total least squares for vector observations from landmark features. First, the optimization framework is formulated for the pose estimation problem with observation vectors extracted from point cloud features. Then, error-covariance expressions are derived. The attitude and position solutions obtained via the derived optimization framework are proven to reach the bounds defined by the Cram\'er-Rao lower bound under the small angle approximation of attitude errors. The measurement data for the simulation of this problem is provided through a series of vector observation scans, and a fully populated observation noise-covariance matrix is assumed as the weight in the cost function to cover for the most general case of the sensor uncertainty. Here, previous derivations are expanded for the pose estimation problem to include more generic cases of correlations in the errors than previously cases involving an isotropic noise assumption. The proposed solution is simulated in a Monte-Carlo framework with 10,000 samples to validate the error-covariance analysis.