 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Crash Once v2: Perceptually Consistent Strong Features for One-Stage Domain Adaptive Detection of Space Terrain
Jan 23, 2025



The in-situ detection of planetary, lunar, and small-body surface terrain is crucial for autonomous spacecraft applications, where learning-based computer vision methods are increasingly employed to enable intelligence without prior information or human intervention. However, many of these methods remain computationally expensive for spacecraft processors and prevent real-time operation. Training of such algorithms is additionally complex due to the scarcity of labeled data and reliance on supervised learning approaches. Unsupervised Domain Adaptation (UDA) offers a promising solution by facilitating model training with disparate data sources such as simulations or synthetic scenes, although UDA is difficult to apply to celestial environments where challenging feature spaces are paramount. To alleviate such issues, You Only Crash Once (YOCOv1) has studied the integration of Visual Similarity-based Alignment (VSA) into lightweight one-stage object detection architectures to improve space terrain UDA. Although proven effective, the approach faces notable limitations, including performance degradations in multi-class and high-altitude scenarios. Building upon the foundation of YOCOv1, we propose novel additions to the VSA scheme that enhance terrain detection capabilities under UDA, and our approach is evaluated across both simulated and real-world data. Our second YOCO rendition, YOCOv2, is capable of achieving state-of-the-art UDA performance on surface terrain detection, where we showcase improvements upwards of 31% compared with YOCOv1 and terrestrial state-of-the-art. We demonstrate the practical utility of YOCOv2 with spacecraft flight hardware performance benchmarking and qualitative evaluation of NASA mission data.
MARs: Multi-view Attention Regularizations for Patch-based Feature Recognition of Space Terrain
Oct 07, 2024The visual detection and tracking of surface terrain is required for spacecraft to safely land on or navigate within close proximity to celestial objects. Current approaches rely on template matching with pre-gathered patch-based features, which are expensive to obtain and a limiting factor in perceptual capability. While recent literature has focused on in-situ detection methods to enhance navigation and operational autonomy, robust description is still needed. In this work, we explore metric learning as the lightweight feature description mechanism and find that current solutions fail to address inter-class similarity and multi-view observational geometry. We attribute this to the view-unaware attention mechanism and introduce Multi-view Attention Regularizations (MARs) to constrain the channel and spatial attention across multiple feature views, regularizing the what and where of attention focus. We thoroughly analyze many modern metric learning losses with and without MARs and demonstrate improved terrain-feature recognition performance by upwards of 85%. We additionally introduce the Luna-1 dataset, consisting of Moon crater landmarks and reference navigation frames from NASA mission data to support future research in this difficult task. Luna-1 and source code are publicly available at https://droneslab.github.io/mars/.
You Only Crash Once: Improved Object Detection for Real-Time, Sim-to-Real Hazardous Terrain Detection and Classification for Autonomous Planetary Landings
Mar 08, 2023
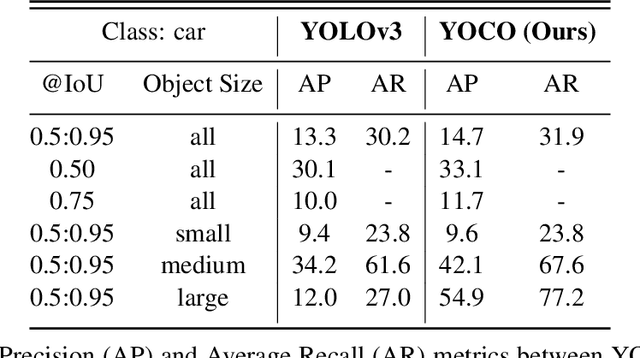

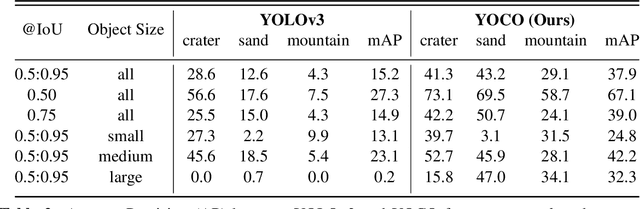
The detection of hazardous terrain during the planetary landing of spacecraft plays a critical role in assuring vehicle safety and mission success. A cheap and effective way of detecting hazardous terrain is through the use of visual cameras, which ensure operational ability from atmospheric entry through touchdown. Plagued by resource constraints and limited computational power, traditional techniques for visual hazardous terrain detection focus on template matching and registration to pre-built hazard maps. Although successful on previous missions, this approach is restricted to the specificity of the templates and limited by the fidelity of the underlying hazard map, which both require extensive pre-flight cost and effort to obtain and develop. Terrestrial systems that perform a similar task in applications such as autonomous driving utilize state-of-the-art deep learning techniques to successfully localize and classify navigation hazards. Advancements in spacecraft co-processors aimed at accelerating deep learning inference enable the application of these methods in space for the first time. In this work, we introduce You Only Crash Once (YOCO), a deep learning-based visual hazardous terrain detection and classification technique for autonomous spacecraft planetary landings. Through the use of unsupervised domain adaptation we tailor YOCO for training by simulation, removing the need for real-world annotated data and expensive mission surveying phases. We further improve the transfer of representative terrain knowledge between simulation and the real world through visual similarity clustering. We demonstrate the utility of YOCO through a series of terrestrial and extraterrestrial simulation-to-real experiments and show substantial improvements toward the ability to both detect and accurately classify instances of planetary terrain.