 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does Generative Recommendation Generalize?
Mar 20, 2026A widely held hypothesis for why generative recommendation (GR) models outperform conventional item ID-based models is that they generalize better. However, there is few systematic way to verify this hypothesis beyond a superficial comparison of overall performance. To address this gap, we categorize each data instance based on the specific capability required for a correct prediction: either memorization (reusing item transition patterns observed during training) or generalization (composing known patterns to predict unseen item transitions). Extensive experiments show that GR models perform better on instances that require generalization, whereas item ID-based models perform better when memorization is more important. To explain this divergence, we shift the analysis from the item level to the token level and show that what appears to be item-level generalization often reduces to token-level memorization for GR models. Finally, we show that the two paradigms are complementary. We propose a simple memorization-aware indicator that adaptively combines them on a per-instance basis, leading to improved overall recommendation performance.
Inductive Generative Recommendation via Retrieval-based Speculation
Oct 03, 2024Generative recommendation (GR) is an emerging paradigm that tokenizes items into discrete tokens and learns to autoregressively generate the next tokens as predictions. Although effective, GR models operate in a transductive setting, meaning they can only generate items seen during training without applying heuristic re-ranking strategies. In this paper, we propose SpecGR, a plug-and-play framework that enables GR models to recommend new items in an inductive setting. SpecGR uses a drafter model with inductive capability to propose candidate items, which may include both existing items and new items. The GR model then acts as a verifier, accepting or rejecting candidates while retaining its strong ranking capabilities. We further introduce the guided re-drafting technique to make the proposed candidates more aligned with the outputs of generative recommendation models, improving the verification efficiency. We consider two variants for drafting: (1) using an auxiliary drafter model for better flexibility, or (2) leveraging the GR model's own encoder for parameter-efficient self-drafting. Extensive experiments on three real-world datasets demonstrate that SpecGR exhibits both strong inductive recommendation ability and the best overall performance among the compared methods. Our code is available at: https://github.com/Jamesding000/SpecGR.
Multiple Kronecker RLS fusion-based link propagation for drug-side effect prediction
Jun 27, 2024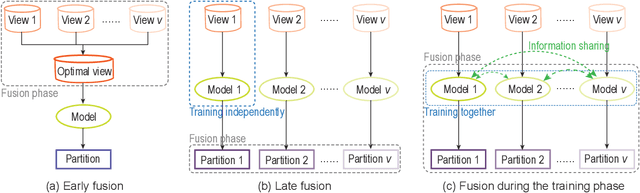
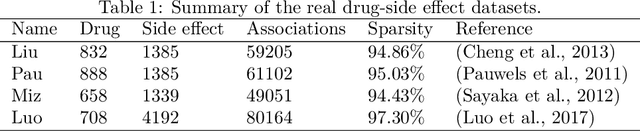
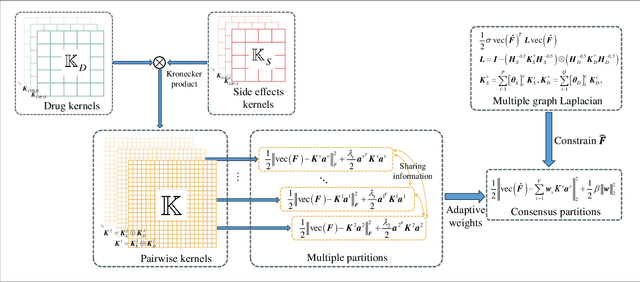
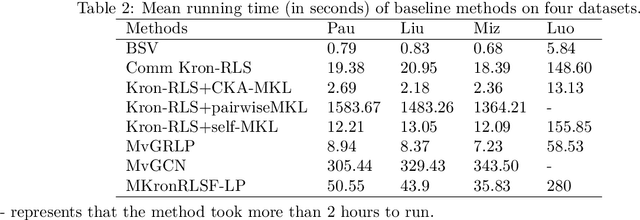
Drug-side effect prediction has become an essential area of research in the field of pharmacology. As the use of medications continues to rise, so does the importance of understanding and mitigating the potential risks associated with them. At present, researchers have turned to data-driven methods to predict drug-side effects. Drug-side effect prediction is a link prediction problem, and the related data can be described from various perspectives. To process these kinds of data, a multi-view method, called Multiple Kronecker RLS fusion-based link propagation (MKronRLSF-LP), is proposed. MKronRLSF-LP extends the Kron-RLS by finding the consensus partitions and multiple graph Laplacian constraints in the multi-view setting. Both of these multi-view settings contribute to a higher quality result. Extensive experiments have been conducted on drug-side effect datasets, and our empirical results provide evidence that our approach is effective and robust.
SBSM-Pro: Support Bio-sequence Machine for Proteins
Aug 20, 2023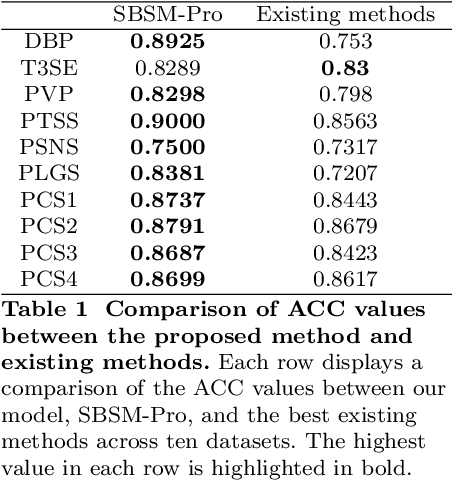



Proteins play a pivotal role in biological systems. The use of machine learning algorithms for protein classification can assist and even guide biological experiments, offering crucial insights for biotechnological applications. We propose a support bio-sequence machine for proteins, a model specifically designed for biological sequence classification. This model starts with raw sequences and groups amino acids based on their physicochemical properties. It incorporates sequence alignment to measure the similarities between proteins and uses a novel MKL approach to integrate various types of information, utilizing support vector machines for classification prediction. The results indicate that our model demonstrates commendable performance across 10 datasets in terms of the identification of protein function and posttranslational modification. This research not only showcases state-of-the-art work in protein classification but also paves the way for new directions in this domain, representing a beneficial endeavour in the development of platforms tailored for biological sequence classification. SBSM-Pro is available for access at http://lab.malab.cn/soft/SBSM-Pro/.