 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectness isnt Efficiency: Runtime Memory Divergence in LLM-Generated Code
Jan 03, 2026Large language models (LLMs) can generate programs that pass unit tests, but passing tests does not guarantee reliable runtime behavior. We find that different correct solutions to the same task can show very different memory and performance patterns, which can lead to hidden operational risks. We present a framework to measure execution-time memory stability across multiple correct generations. At the solution level, we introduce Dynamic Mean Pairwise Distance (DMPD), which uses Dynamic Time Warping to compare the shapes of memory-usage traces after converting them into Monotonic Peak Profiles (MPPs) to reduce transient noise. Aggregating DMPD across tasks yields a model-level Model Instability Score (MIS). Experiments on BigOBench and CodeContests show substantial runtime divergence among correct solutions. Instability often increases with higher sampling temperature even when pass@1 improves. We also observe correlations between our stability measures and software engineering indicators such as cognitive and cyclomatic complexity, suggesting links between operational behavior and maintainability. Our results support stability-aware selection among passing candidates in CI/CD to reduce operational risk without sacrificing correctness. Artifacts are available.
Dynamic Stability of LLM-Generated Code
Nov 07, 2025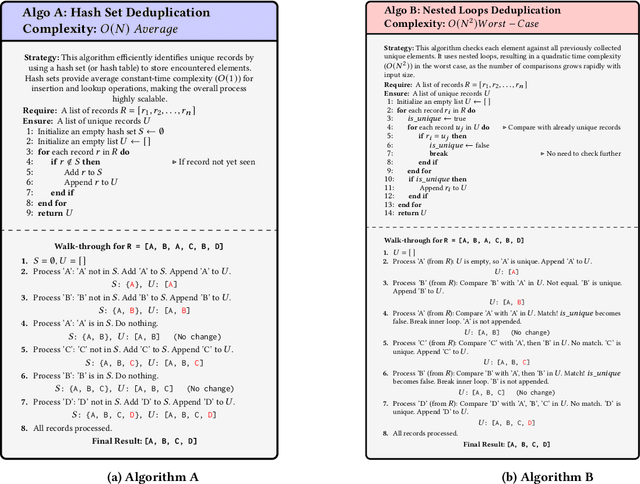
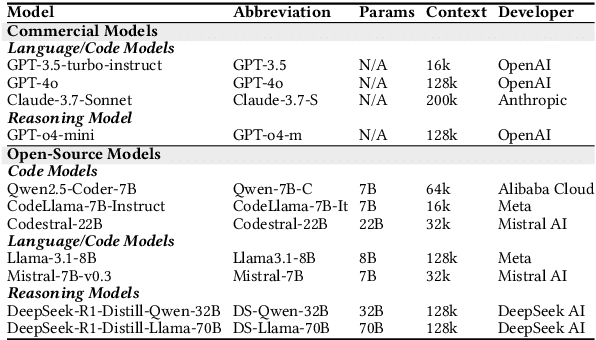
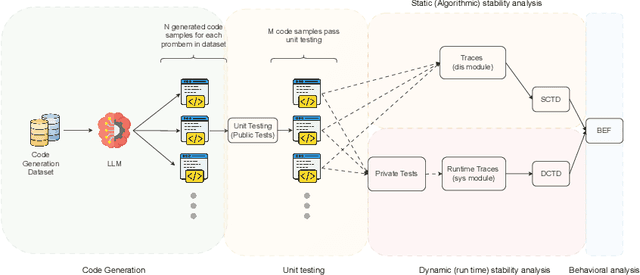
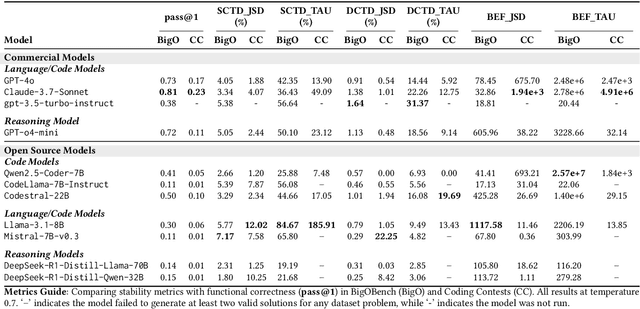
Current evaluations of LLMs for code generation emphasize functional correctness, overlooking the fact that functionally correct solutions can differ significantly in algorithmic complexity. For instance, an $(O(n^2))$ versus $(O(n \log n))$ sorting algorithm may yield similar output but incur vastly different performance costs in production. This discrepancy reveals a critical limitation in current evaluation methods: they fail to capture the behavioral and performance diversity among correct solutions. To address this, we introduce a principled framework for evaluating the dynamic stability of generated code. We propose two metrics derived from opcode distributions: Static Canonical Trace Divergence (SCTD), which captures algorithmic structure diversity across generated solutions, and Dynamic Canonical Trace Divergence (DCTD), which quantifies runtime behavioral variance. Their ratio, the Behavioral Expression Factor (BEF), serves as a diagnostic signal: it indicates critical runtime instability when BEF $\ll$ 1 and functional redundancy when BEF $\gg$ 1. Empirical results on BigOBench and CodeContests show that state-of-the-art LLMs exhibit significant algorithmic variance even among functionally correct outputs. Notably, increasing sampling temperature improves pass@1 rates but degrades stability, revealing an unrecognized trade-off: searching for correct solutions in diverse output spaces introduces a "penalty of instability" between correctness and behavioral consistency. Our findings call for stability-aware objectives in code generation and new benchmarks with asymptotic test cases for robust, real-world LLM evaluation.
Adversarial Attacks and Defenses on Graph-aware Large Language Models (LLMs)
Aug 06, 2025Large Language Models (LLMs) are increasingly integrated with graph-structured data for tasks like node classification, a domain traditionally dominated by Graph Neural Networks (GNNs). While this integration leverages rich relational information to improve task performance, their robustness against adversarial attacks remains unexplored. We take the first step to explore the vulnerabilities of graph-aware LLMs by leveraging existing adversarial attack methods tailored for graph-based models, including those for poisoning (training-time attacks) and evasion (test-time attacks), on two representative models, LLAGA (Chen et al. 2024) and GRAPHPROMPTER (Liu et al. 2024). Additionally, we discover a new attack surface for LLAGA where an attacker can inject malicious nodes as placeholders into the node sequence template to severely degrade its performance. Our systematic analysis reveals that certain design choices in graph encoding can enhance attack success, with specific findings that: (1) the node sequence template in LLAGA increases its vulnerability; (2) the GNN encoder used in GRAPHPROMPTER demonstrates greater robustness; and (3) both approaches remain susceptible to imperceptible feature perturbation attacks. Finally, we propose an end-to-end defense framework GALGUARD, that combines an LLM-based feature correction module to mitigate feature-level perturbations and adapted GNN defenses to protect against structural attacks.
SCOOTER: A Human Evaluation Framework for Unrestricted Adversarial Examples
Jul 10, 2025Unrestricted adversarial attacks aim to fool computer vision models without being constrained by $\ell_p$-norm bounds to remain imperceptible to humans, for example, by changing an object's color. This allows attackers to circumvent traditional, norm-bounded defense strategies such as adversarial training or certified defense strategies. However, due to their unrestricted nature, there are also no guarantees of norm-based imperceptibility, necessitating human evaluations to verify just how authentic these adversarial examples look. While some related work assesses this vital quality of adversarial attacks, none provide statistically significant insights. This issue necessitates a unified framework that supports and streamlines such an assessment for evaluating and comparing unrestricted attacks. To close this gap, we introduce SCOOTER - an open-source, statistically powered framework for evaluating unrestricted adversarial examples. Our contributions are: $(i)$ best-practice guidelines for crowd-study power, compensation, and Likert equivalence bounds to measure imperceptibility; $(ii)$ the first large-scale human vs. model comparison across 346 human participants showing that three color-space attacks and three diffusion-based attacks fail to produce imperceptible images. Furthermore, we found that GPT-4o can serve as a preliminary test for imperceptibility, but it only consistently detects adversarial examples for four out of six tested attacks; $(iii)$ open-source software tools, including a browser-based task template to collect annotations and analysis scripts in Python and R; $(iv)$ an ImageNet-derived benchmark dataset containing 3K real images, 7K adversarial examples, and over 34K human ratings. Our findings demonstrate that automated vision systems do not align with human perception, reinforcing the need for a ground-truth SCOOTER benchmark.
Does Black-box Attribute Inference Attacks on Graph Neural Networks Constitute Privacy Risk?
Jun 01, 2023



Graph neural networks (GNNs) have shown promising results on real-life datasets and applications, including healthcare, finance, and education. However, recent studies have shown that GNNs are highly vulnerable to attacks such as membership inference attack and link reconstruction attack. Surprisingly, attribute inference attacks has received little attention. In this paper, we initiate the first investigation into attribute inference attack where an attacker aims to infer the sensitive user attributes based on her public or non-sensitive attributes. We ask the question whether black-box attribute inference attack constitutes a significant privacy risk for graph-structured data and their corresponding GNN model. We take a systematic approach to launch the attacks by varying the adversarial knowledge and assumptions. Our findings reveal that when an attacker has black-box access to the target model, GNNs generally do not reveal significantly more information compared to missing value estimation techniques. Code is available.
Private Graph Extraction via Feature Explanations
Jun 29, 2022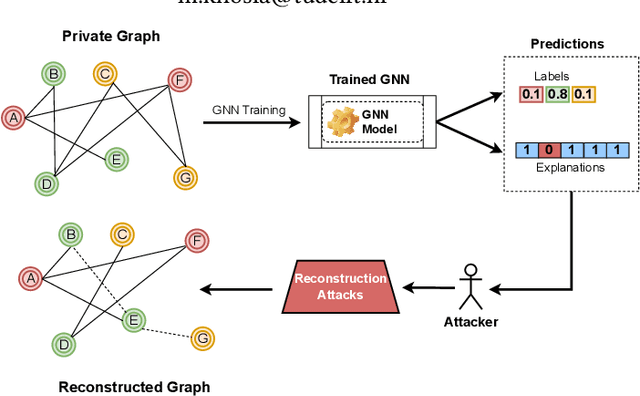

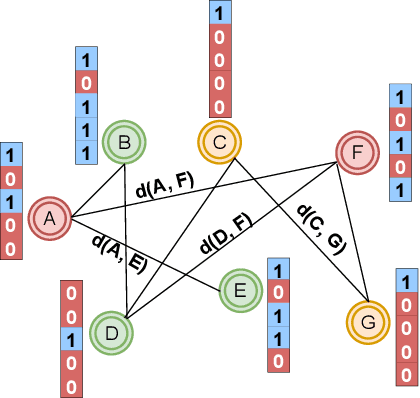
Privacy and interpretability are two of the important ingredients for achieving trustworthy machine learning. We study the interplay of these two aspects in graph machine learning through graph reconstruction attacks. The goal of the adversary here is to reconstruct the graph structure of the training data given access to model explanations. Based on the different kinds of auxiliary information available to the adversary, we propose several graph reconstruction attacks. We show that additional knowledge of post-hoc feature explanations substantially increases the success rate of these attacks. Further, we investigate in detail the differences between attack performance with respect to three different classes of explanation methods for graph neural networks: gradient-based, perturbation-based, and surrogate model-based methods. While gradient-based explanations reveal the most in terms of the graph structure, we find that these explanations do not always score high in utility. For the other two classes of explanations, privacy leakage increases with an increase in explanation utility. Finally, we propose a defense based on a randomized response mechanism for releasing the explanations which substantially reduces the attack success rate. Our anonymized code is available.
Releasing Graph Neural Networks with Differential Privacy Guarantees
Sep 18, 2021
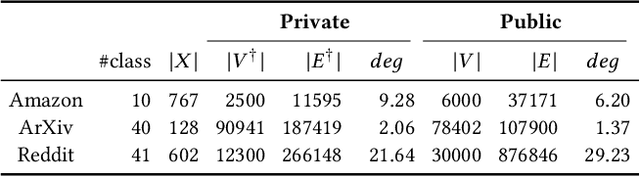
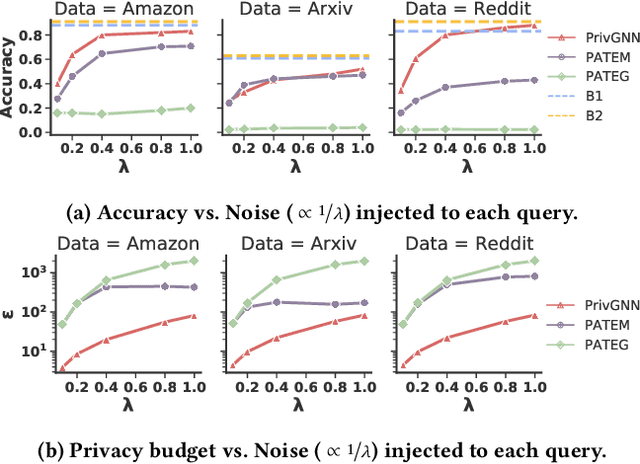
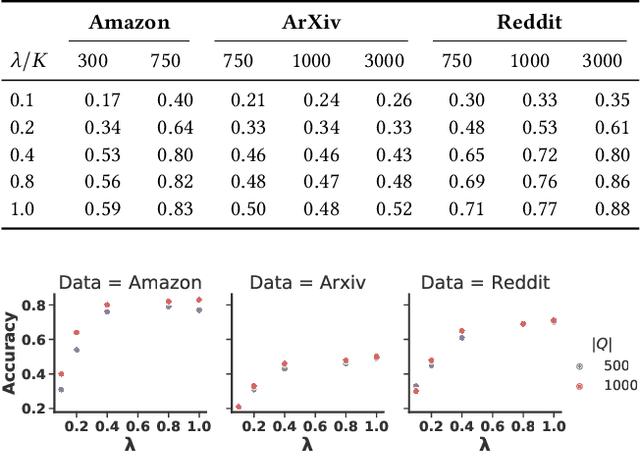
With the increasing popularity of Graph Neural Networks (GNNs) in several sensitive applications like healthcare and medicine, concerns have been raised over the privacy aspects of trained GNNs. More notably, GNNs are vulnerable to privacy attacks, such as membership inference attacks, even if only blackbox access to the trained model is granted. To build defenses, differential privacy has emerged as a mechanism to disguise the sensitive data in training datasets. Following the strategy of Private Aggregation of Teacher Ensembles (PATE), recent methods leverage a large ensemble of teacher models. These teachers are trained on disjoint subsets of private data and are employed to transfer knowledge to a student model, which is then released with privacy guarantees. However, splitting graph data into many disjoint training sets may destroy the structural information and adversely affect accuracy. We propose a new graph-specific scheme of releasing a student GNN, which avoids splitting private training data altogether. The student GNN is trained using public data, partly labeled privately using the teacher GNN models trained exclusively for each query node. We theoretically analyze our approach in the R\`{e}nyi differential privacy framework and provide privacy guarantees. Besides, we show the solid experimental performance of our method compared to several baselines, including the PATE baseline adapted for graph-structured data. Our anonymized code is available.
Achieving differential privacy for $k$-nearest neighbors based outlier detection by data partitioning
Apr 16, 2021


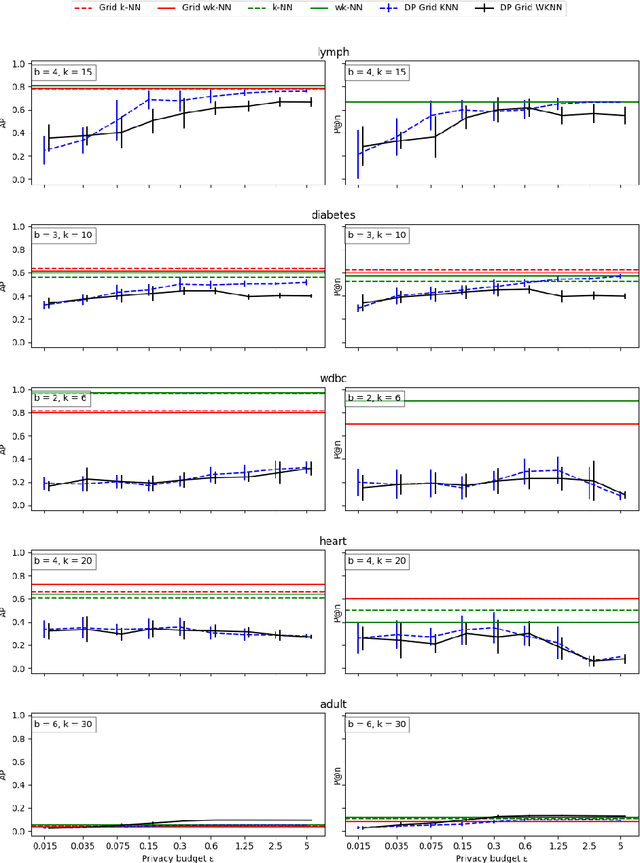
When applying outlier detection in settings where data is sensitive, mechanisms which guarantee the privacy of the underlying data are needed. The $k$-nearest neighbors ($k$-NN) algorithm is a simple and one of the most effective methods for outlier detection. So far, there have been no attempts made to develop a differentially private ($\epsilon$-DP) approach for $k$-NN based outlier detection. Existing approaches often relax the notion of $\epsilon$-DP and employ other methods than $k$-NN. We propose a method for $k$-NN based outlier detection by separating the procedure into a fitting step on reference inlier data and then apply the outlier classifier to new data. We achieve $\epsilon$-DP for both the fitting algorithm and the outlier classifier with respect to the reference data by partitioning the dataset into a uniform grid, which yields low global sensitivity. Our approach yields nearly optimal performance on real-world data with varying dimensions when compared to the non-private versions of $k$-NN.
A Review of Anonymization for Healthcare Data
Apr 13, 2021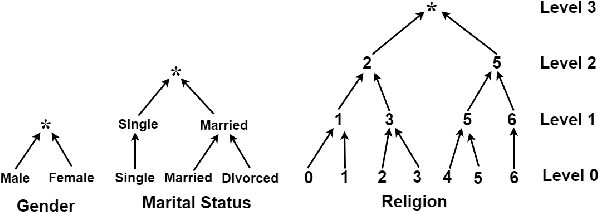
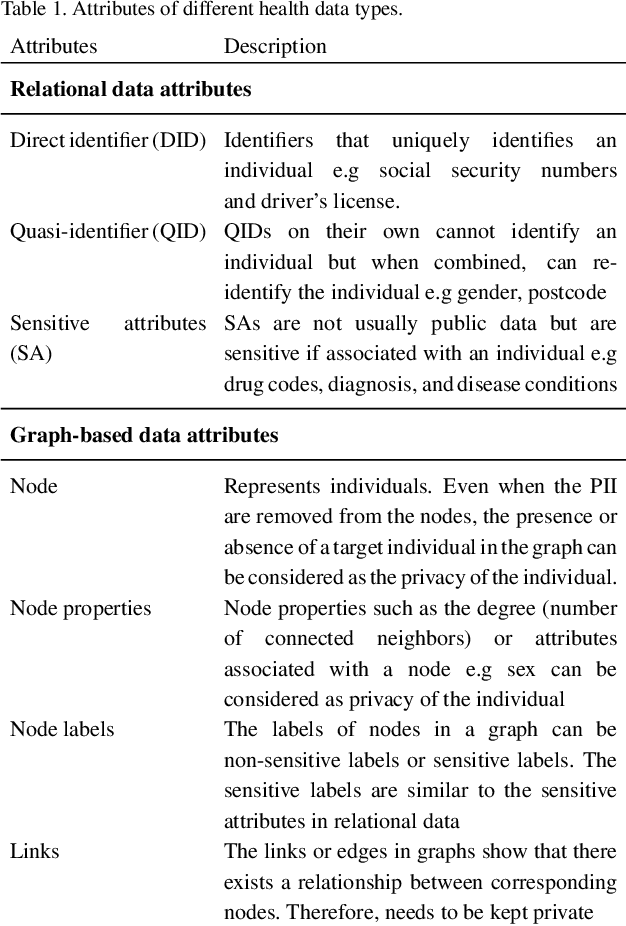
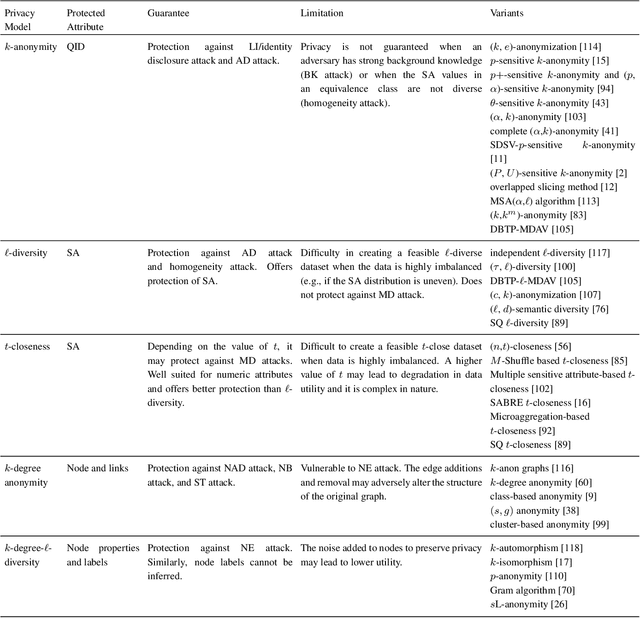
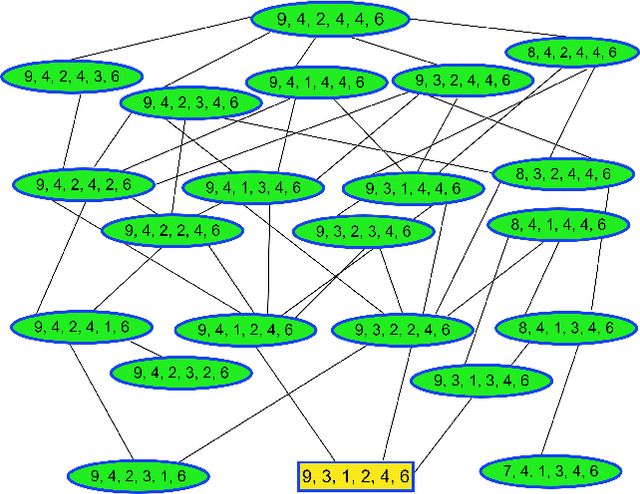
Mining health data can lead to faster medical decisions, improvement in the quality of treatment, disease prevention, reduced cost, and it drives innovative solutions within the healthcare sector. However, health data is highly sensitive and subject to regulations such as the General Data Protection Regulation (GDPR), which aims to ensure patient's privacy. Anonymization or removal of patient identifiable information, though the most conventional way, is the first important step to adhere to the regulations and incorporate privacy concerns. In this paper, we review the existing anonymization techniques and their applicability to various types (relational and graph-based) of health data. Besides, we provide an overview of possible attacks on anonymized data. We illustrate via a reconstruction attack that anonymization though necessary, is not sufficient to address patient privacy and discuss methods for protecting against such attacks. Finally, we discuss tools that can be used to achieve anonymization.
Membership Inference Attack on Graph Neural Networks
Jan 17, 2021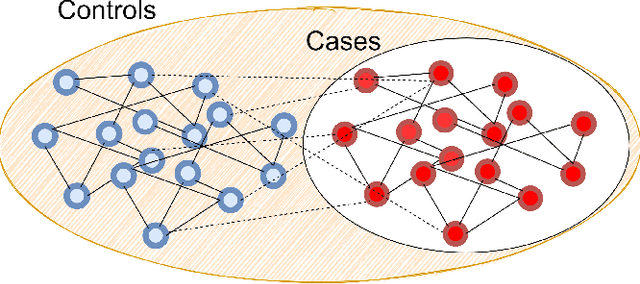
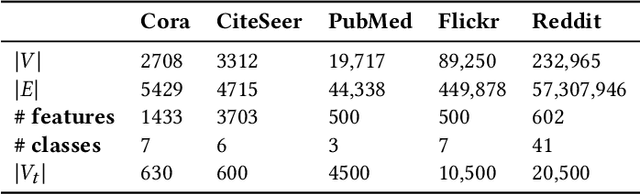
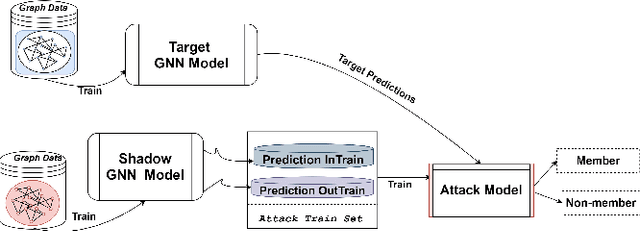
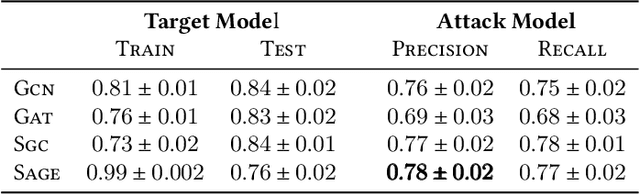
Graph Neural Networks (GNNs), which generalize traditional deep neural networks or graph data, have achieved state of the art performance on several graph analytical tasks like node classification, link prediction or graph classification. We focus on how trained GNN models could leak information about the \emph{member} nodes that they were trained on. In particular, we focus on answering the question: given a graph, can we determine which nodes were used for training the GNN model? We operate in the inductive settings for node classification, which means that none of the nodes in the test set (or the \emph{non-member} nodes) were seen during the training. We propose a simple attack model which is able to distinguish between the member and non-member nodes while just having a black-box access to the model. We experimentally compare the privacy risks of four representative GNN models. Our results show that all the studied GNN models are vulnerable to privacy leakage. While in traditional machine learning models, overfitting is considered the main cause of such leakage, we show that in GNNs the additional structural information is the major contributing factor.