 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudoMapTrainer: Learning Online Mapping without HD Maps
Aug 26, 2025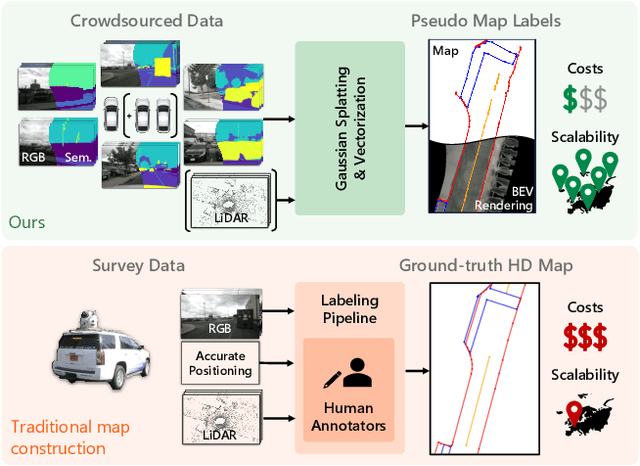
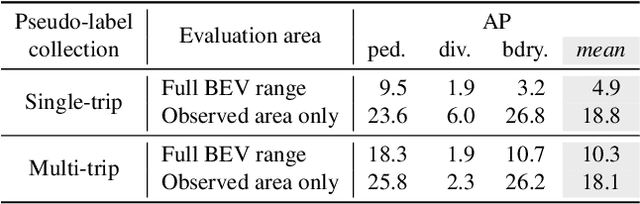
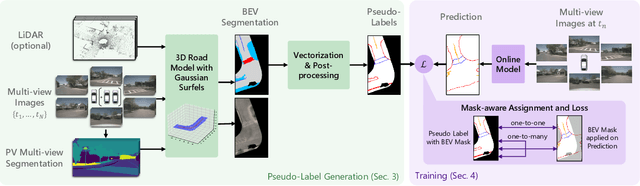
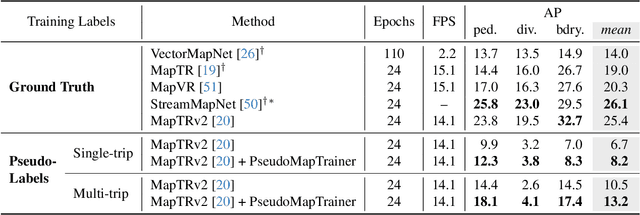
Online mapping models show remarkable results in predicting vectorized maps from multi-view camera images only. However, all existing approaches still rely on ground-truth high-definition maps during training, which are expensive to obtain and often not geographically diverse enough for reliable generalization. In this work, we propose PseudoMapTrainer, a novel approach to online mapping that uses pseudo-labels generated from unlabeled sensor data. We derive those pseudo-labels by reconstructing the road surface from multi-camera imagery using Gaussian splatting and semantics of a pre-trained 2D segmentation network. In addition, we introduce a mask-aware assignment algorithm and loss function to handle partially masked pseudo-labels, allowing for the first time the training of online mapping models without any ground-truth maps. Furthermore, our pseudo-labels can be effectively used to pre-train an online model in a semi-supervised manner to leverage large-scale unlabeled crowdsourced data. The code is available at github.com/boschresearch/PseudoMapTrainer.
Unsupervised Point Cloud Registration with Self-Distillation
Sep 11, 2024
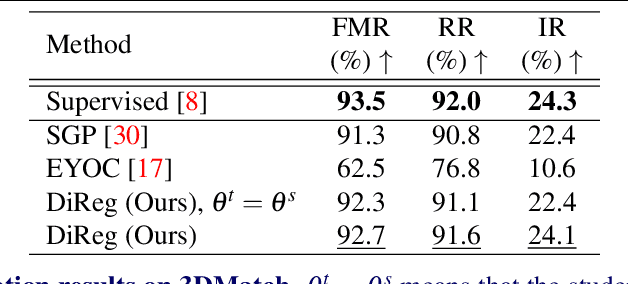
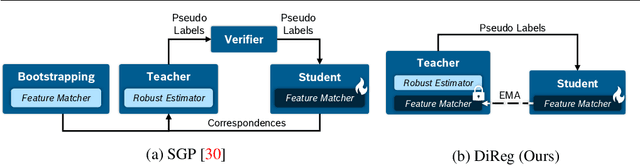
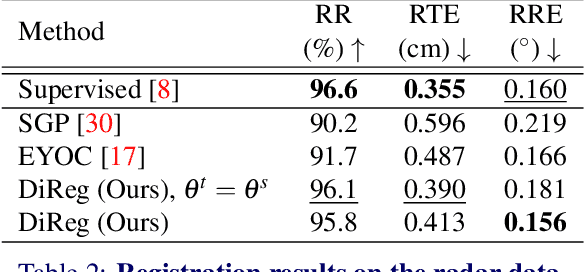
Rigid point cloud registration is a fundamental problem and highly relevant in robotics and autonomous driving. Nowadays deep learning methods can be trained to match a pair of point clouds, given the transformation between them. However, this training is often not scalable due to the high cost of collecting ground truth poses. Therefore, we present a self-distillation approach to learn point cloud registration in an unsupervised fashion. Here, each sample is passed to a teacher network and an augmented view is passed to a student network. The teacher includes a trainable feature extractor and a learning-free robust solver such as RANSAC. The solver forces consistency among correspondences and optimizes for the unsupervised inlier ratio, eliminating the need for ground truth labels. Our approach simplifies the training procedure by removing the need for initial hand-crafted features or consecutive point cloud frames as seen in related methods. We show that our method not only surpasses them on the RGB-D benchmark 3DMatch but also generalizes well to automotive radar, where classical features adopted by others fail. The code is available at https://github.com/boschresearch/direg .
Private Graph Extraction via Feature Explanations
Jun 29, 2022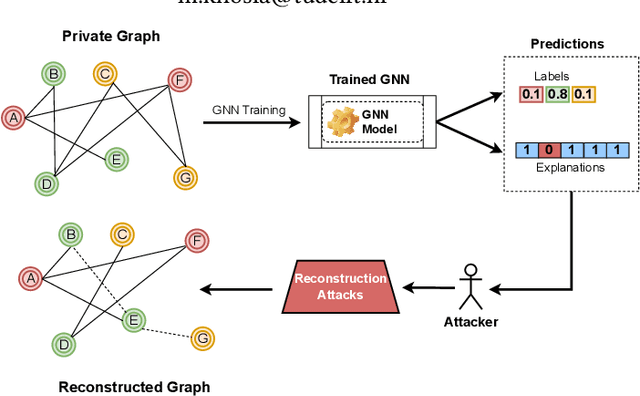

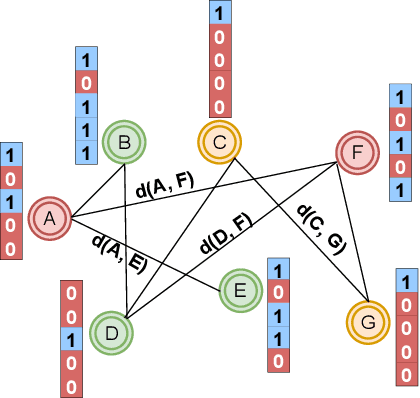
Privacy and interpretability are two of the important ingredients for achieving trustworthy machine learning. We study the interplay of these two aspects in graph machine learning through graph reconstruction attacks. The goal of the adversary here is to reconstruct the graph structure of the training data given access to model explanations. Based on the different kinds of auxiliary information available to the adversary, we propose several graph reconstruction attacks. We show that additional knowledge of post-hoc feature explanations substantially increases the success rate of these attacks. Further, we investigate in detail the differences between attack performance with respect to three different classes of explanation methods for graph neural networks: gradient-based, perturbation-based, and surrogate model-based methods. While gradient-based explanations reveal the most in terms of the graph structure, we find that these explanations do not always score high in utility. For the other two classes of explanations, privacy leakage increases with an increase in explanation utility. Finally, we propose a defense based on a randomized response mechanism for releasing the explanations which substantially reduces the attack success rate. Our anonymized code is available.
BAGEL: A Benchmark for Assessing Graph Neural Network Explanations
Jun 28, 2022The problem of interpreting the decisions of machine learning is a well-researched and important. We are interested in a specific type of machine learning model that deals with graph data called graph neural networks. Evaluating interpretability approaches for graph neural networks (GNN) specifically are known to be challenging due to the lack of a commonly accepted benchmark. Given a GNN model, several interpretability approaches exist to explain GNN models with diverse (sometimes conflicting) evaluation methodologies. In this paper, we propose a benchmark for evaluating the explainability approaches for GNNs called Bagel. In Bagel, we firstly propose four diverse GNN explanation evaluation regimes -- 1) faithfulness, 2) sparsity, 3) correctness. and 4) plausibility. We reconcile multiple evaluation metrics in the existing literature and cover diverse notions for a holistic evaluation. Our graph datasets range from citation networks, document graphs, to graphs from molecules and proteins. We conduct an extensive empirical study on four GNN models and nine post-hoc explanation approaches for node and graph classification tasks. We open both the benchmarks and reference implementations and make them available at https://github.com/Mandeep-Rathee/Bagel-benchmark.
Releasing Graph Neural Networks with Differential Privacy Guarantees
Sep 18, 2021
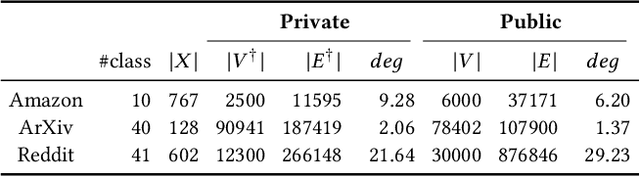
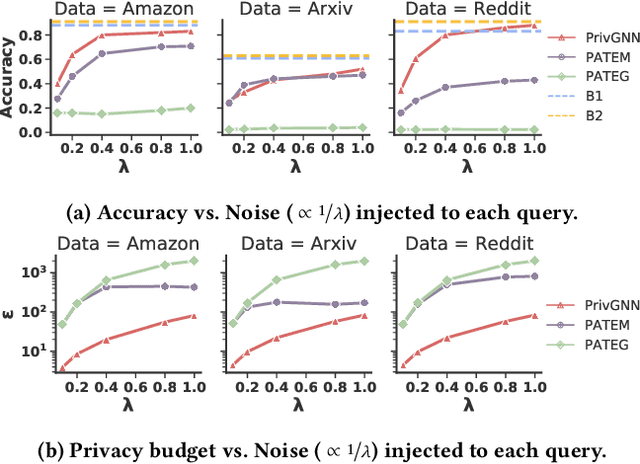
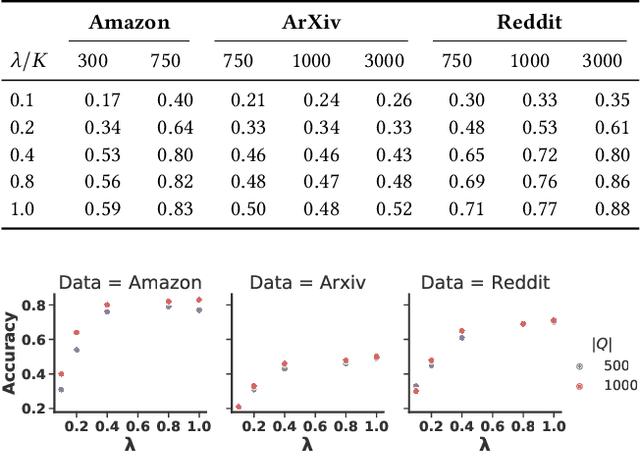
With the increasing popularity of Graph Neural Networks (GNNs) in several sensitive applications like healthcare and medicine, concerns have been raised over the privacy aspects of trained GNNs. More notably, GNNs are vulnerable to privacy attacks, such as membership inference attacks, even if only blackbox access to the trained model is granted. To build defenses, differential privacy has emerged as a mechanism to disguise the sensitive data in training datasets. Following the strategy of Private Aggregation of Teacher Ensembles (PATE), recent methods leverage a large ensemble of teacher models. These teachers are trained on disjoint subsets of private data and are employed to transfer knowledge to a student model, which is then released with privacy guarantees. However, splitting graph data into many disjoint training sets may destroy the structural information and adversely affect accuracy. We propose a new graph-specific scheme of releasing a student GNN, which avoids splitting private training data altogether. The student GNN is trained using public data, partly labeled privately using the teacher GNN models trained exclusively for each query node. We theoretically analyze our approach in the R\`{e}nyi differential privacy framework and provide privacy guarantees. Besides, we show the solid experimental performance of our method compared to several baselines, including the PATE baseline adapted for graph-structured data. Our anonymized code is available.
An Adaptive Clustering Approach for Accident Prediction
Aug 27, 2021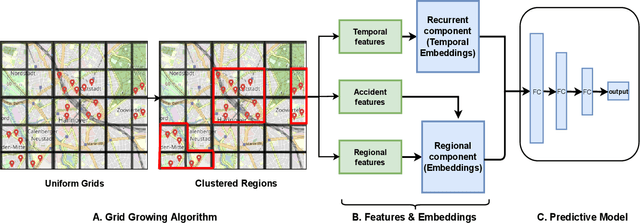
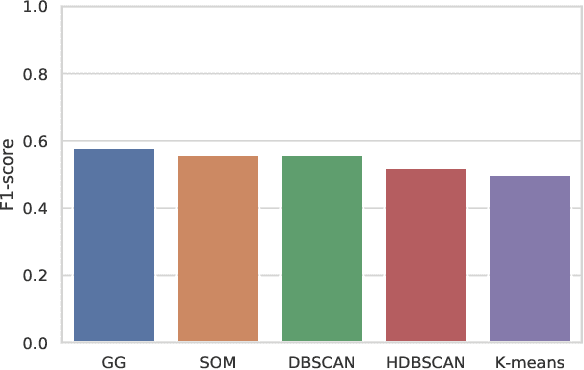
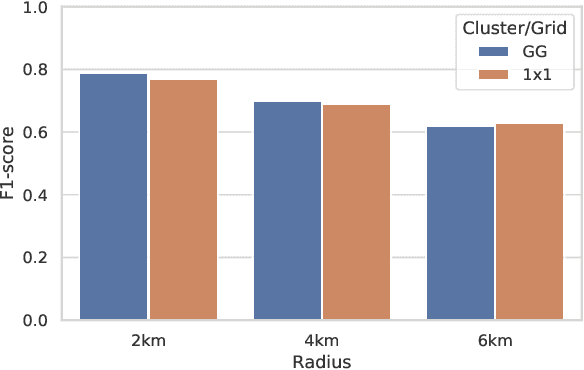

Traffic accident prediction is a crucial task in the mobility domain. State-of-the-art accident prediction approaches are based on static and uniform grid-based geospatial aggregations, limiting their capability for fine-grained predictions. This property becomes particularly problematic in more complex regions such as city centers. In such regions, a grid cell can contain subregions with different properties; furthermore, an actual accident-prone region can be split across grid cells arbitrarily. This paper proposes Adaptive Clustering Accident Prediction (ACAP) - a novel accident prediction method based on a grid growing algorithm. ACAP applies adaptive clustering to the observed geospatial accident distribution and performs embeddings of temporal, accident-related, and regional features to increase prediction accuracy. We demonstrate the effectiveness of the proposed ACAP method using open real-world accident datasets from three cities in Germany. We demonstrate that ACAP improves the accident prediction performance for complex regions by 2-3 percent points in F1-score by adapting the geospatial aggregation to the distribution of the underlying spatio-temporal events. Our grid growing approach outperforms the clustering-based baselines by four percent points in terms of F1-score on average.
* 7 pages, 4 figures
Learnt Sparsification for Interpretable Graph Neural Networks
Jun 23, 2021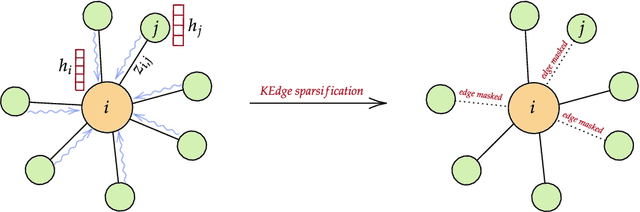
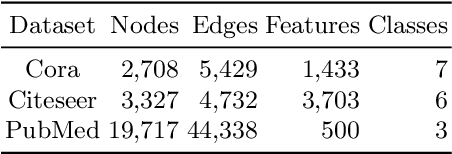
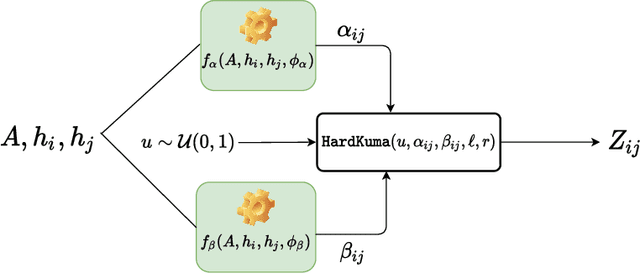
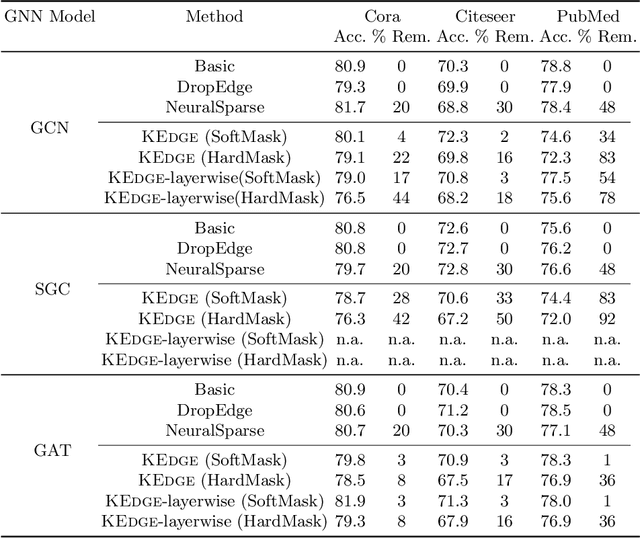
Graph neural networks (GNNs) have achieved great success on various tasks and fields that require relational modeling. GNNs aggregate node features using the graph structure as inductive biases resulting in flexible and powerful models. However, GNNs remain hard to interpret as the interplay between node features and graph structure is only implicitly learned. In this paper, we propose a novel method called Kedge for explicitly sparsifying the underlying graph by removing unnecessary neighbors. Our key idea is based on a tractable method for sparsification using the Hard Kumaraswamy distribution that can be used in conjugation with any GNN model. Kedge learns edge masks in a modular fashion trained with any GNN allowing for gradient based optimization in an end-to-end fashion. We demonstrate through extensive experiments that our model Kedge can prune a large proportion of the edges with only a minor effect on the test accuracy. Specifically, in the PubMed dataset, Kedge learns to drop more than 80% of the edges with an accuracy drop of merely 2% showing that graph structure has only a small contribution in comparison to node features. Finally, we also show that Kedge effectively counters the over-smoothing phenomena in deep GNNs by maintaining good task performance with increasing GNN layers.
Zorro: Valid, Sparse, and Stable Explanations in Graph Neural Networks
May 18, 2021
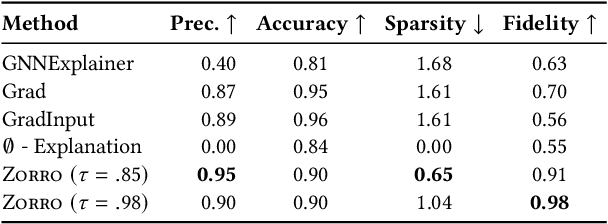
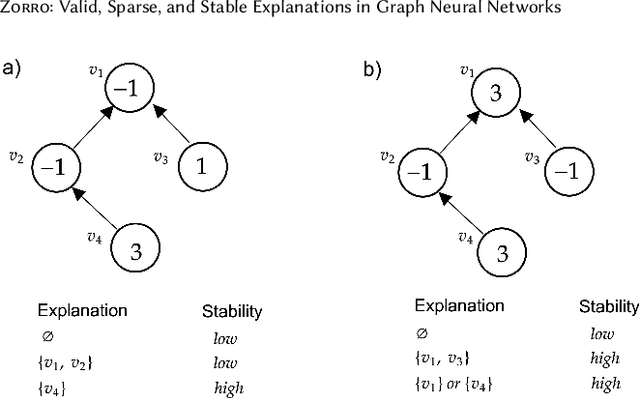
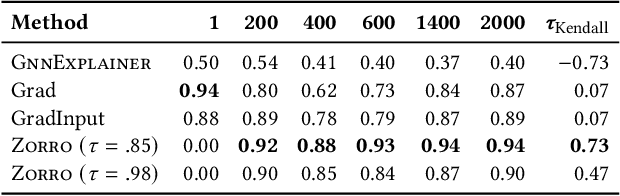
With the ever-increasing popularity and applications of graph neural networks, several proposals have been made to interpret and understand the decisions of a GNN model. Explanations for a GNN model differ in principle from other input settings. It is important to attribute the decision to input features and other related instances connected by the graph structure. We find that the previous explanation generation approaches that maximize the mutual information between the label distribution produced by the GNN model and the explanation to be restrictive. Specifically, existing approaches do not enforce explanations to be predictive, sparse, or robust to input perturbations. In this paper, we lay down some of the fundamental principles that an explanation method for GNNs should follow and introduce a metric fidelity as a measure of the explanation's effectiveness. We propose a novel approach Zorro based on the principles from rate-distortion theory that uses a simple combinatorial procedure to optimize for fidelity. Extensive experiments on real and synthetic datasets reveal that Zorro produces sparser, stable, and more faithful explanations than existing GNN explanation approaches.
Statistical embedding for directed graphs
May 24, 2019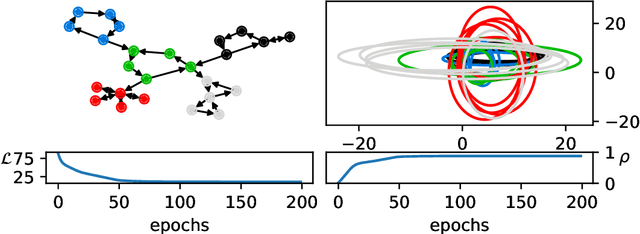
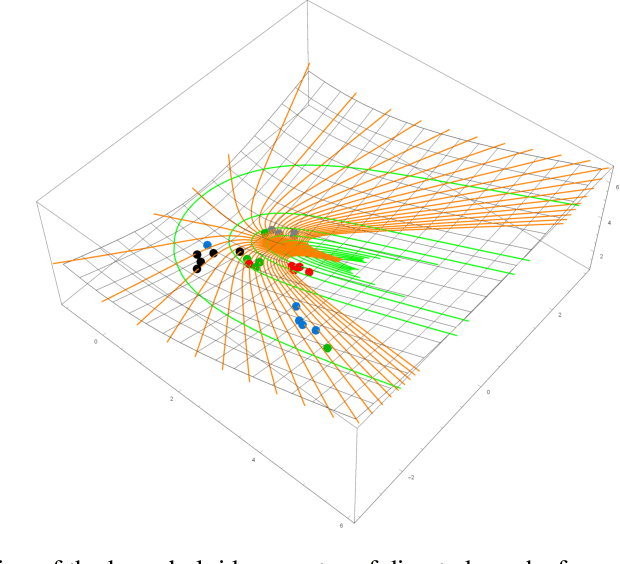
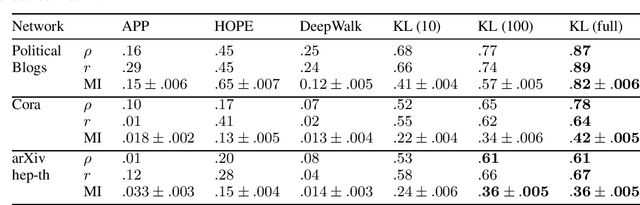
We propose a novel statistical node embedding of directed graphs, which is based on a global minimization of pairwise relative entropy and graph geodesics in a non-linear way. Each node is encoded with a probability density function over a measurable real n-dimensional space. Furthermore, we analyze the connection to the geometrical properties of such embedding and characterize the curvature of the statistical manifolds. Extensive experiments show that our proposed embedding is better preserving the global geodesic information of graphs, as well as outperforming existing embedding models on directed graphs in a variety of evaluation metrics, in an unsupervised setting.