 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Lens of the Telescope: Online Relevance Estimation over Large Retrieval Sets
Apr 12, 2025Advanced relevance models, such as those that use large language models (LLMs), provide highly accurate relevance estimations. However, their computational costs make them infeasible for processing large document corpora. To address this, retrieval systems often employ a telescoping approach, where computationally efficient but less precise lexical and semantic retrievers filter potential candidates for further ranking. However, this approach heavily depends on the quality of early-stage retrieval, which can potentially exclude relevant documents early in the process. In this work, we propose a novel paradigm for re-ranking called online relevance estimation that continuously updates relevance estimates for a query throughout the ranking process. Instead of re-ranking a fixed set of top-k documents in a single step, online relevance estimation iteratively re-scores smaller subsets of the most promising documents while adjusting relevance scores for the remaining pool based on the estimations from the final model using an online bandit-based algorithm. This dynamic process mitigates the recall limitations of telescoping systems by re-prioritizing documents initially deemed less relevant by earlier stages -- including those completely excluded by earlier-stage retrievers. We validate our approach on TREC benchmarks under two scenarios: hybrid retrieval and adaptive retrieval. Experimental results demonstrate that our method is sample-efficient and significantly improves recall, highlighting the effectiveness of our online relevance estimation framework for modern search systems.
Guiding Retrieval using LLM-based Listwise Rankers
Jan 15, 2025Large Language Models (LLMs) have shown strong promise as rerankers, especially in ``listwise'' settings where an LLM is prompted to rerank several search results at once. However, this ``cascading'' retrieve-and-rerank approach is limited by the bounded recall problem: relevant documents not retrieved initially are permanently excluded from the final ranking. Adaptive retrieval techniques address this problem, but do not work with listwise rerankers because they assume a document's score is computed independently from other documents. In this paper, we propose an adaptation of an existing adaptive retrieval method that supports the listwise setting and helps guide the retrieval process itself (thereby overcoming the bounded recall problem for LLM rerankers). Specifically, our proposed algorithm merges results both from the initial ranking and feedback documents provided by the most relevant documents seen up to that point. Through extensive experiments across diverse LLM rerankers, first stage retrievers, and feedback sources, we demonstrate that our method can improve nDCG@10 by up to 13.23% and recall by 28.02%--all while keeping the total number of LLM inferences constant and overheads due to the adaptive process minimal. The work opens the door to leveraging LLM-based search in settings where the initial pool of results is limited, e.g., by legacy systems, or by the cost of deploying a semantic first-stage.
Quam: Adaptive Retrieval through Query Affinity Modelling
Oct 26, 2024



Building relevance models to rank documents based on user information needs is a central task in information retrieval and the NLP community. Beyond the direct ad-hoc search setting, many knowledge-intense tasks are powered by a first-stage retrieval stage for context selection, followed by a more involved task-specific model. However, most first-stage ranking stages are inherently limited by the recall of the initial ranking documents. Recently, adaptive re-ranking techniques have been proposed to overcome this issue by continually selecting documents from the whole corpus, rather than only considering an initial pool of documents. However, so far these approaches have been limited to heuristic design choices, particularly in terms of the criteria for document selection. In this work, we propose a unifying view of the nascent area of adaptive retrieval by proposing, Quam, a \textit{query-affinity model} that exploits the relevance-aware document similarity graph to improve recall, especially for low re-ranking budgets. Our extensive experimental evidence shows that our proposed approach, Quam improves the recall performance by up to 26\% over the standard re-ranking baselines. Further, the query affinity modelling and relevance-aware document graph modules can be injected into any adaptive retrieval approach. The experimental results show the existing adaptive retrieval approach improves recall by up to 12\%. The code of our work is available at \url{https://github.com/Mandeep-Rathee/quam}.
Private Graph Extraction via Feature Explanations
Jun 29, 2022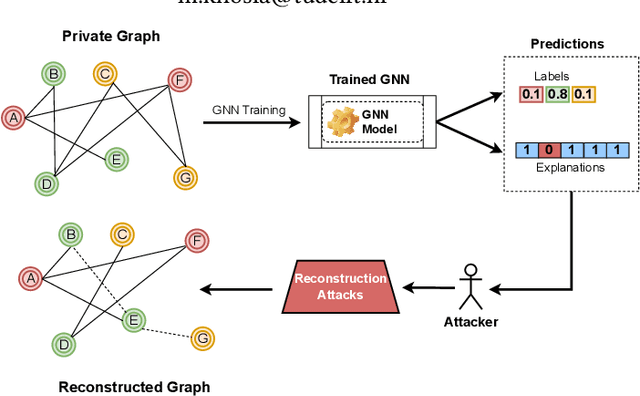

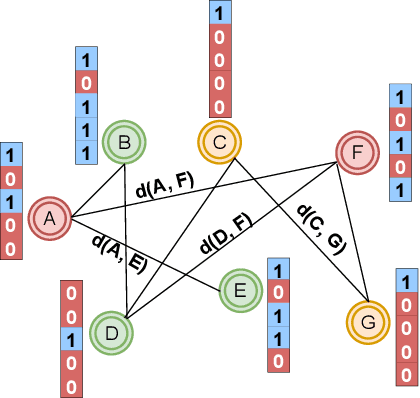
Privacy and interpretability are two of the important ingredients for achieving trustworthy machine learning. We study the interplay of these two aspects in graph machine learning through graph reconstruction attacks. The goal of the adversary here is to reconstruct the graph structure of the training data given access to model explanations. Based on the different kinds of auxiliary information available to the adversary, we propose several graph reconstruction attacks. We show that additional knowledge of post-hoc feature explanations substantially increases the success rate of these attacks. Further, we investigate in detail the differences between attack performance with respect to three different classes of explanation methods for graph neural networks: gradient-based, perturbation-based, and surrogate model-based methods. While gradient-based explanations reveal the most in terms of the graph structure, we find that these explanations do not always score high in utility. For the other two classes of explanations, privacy leakage increases with an increase in explanation utility. Finally, we propose a defense based on a randomized response mechanism for releasing the explanations which substantially reduces the attack success rate. Our anonymized code is available.
BAGEL: A Benchmark for Assessing Graph Neural Network Explanations
Jun 28, 2022The problem of interpreting the decisions of machine learning is a well-researched and important. We are interested in a specific type of machine learning model that deals with graph data called graph neural networks. Evaluating interpretability approaches for graph neural networks (GNN) specifically are known to be challenging due to the lack of a commonly accepted benchmark. Given a GNN model, several interpretability approaches exist to explain GNN models with diverse (sometimes conflicting) evaluation methodologies. In this paper, we propose a benchmark for evaluating the explainability approaches for GNNs called Bagel. In Bagel, we firstly propose four diverse GNN explanation evaluation regimes -- 1) faithfulness, 2) sparsity, 3) correctness. and 4) plausibility. We reconcile multiple evaluation metrics in the existing literature and cover diverse notions for a holistic evaluation. Our graph datasets range from citation networks, document graphs, to graphs from molecules and proteins. We conduct an extensive empirical study on four GNN models and nine post-hoc explanation approaches for node and graph classification tasks. We open both the benchmarks and reference implementations and make them available at https://github.com/Mandeep-Rathee/Bagel-benchmark.
Learnt Sparsification for Interpretable Graph Neural Networks
Jun 23, 2021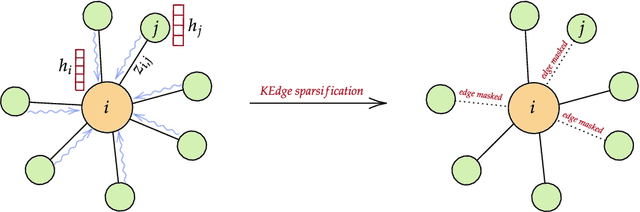
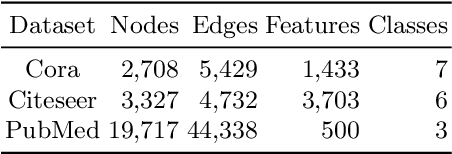
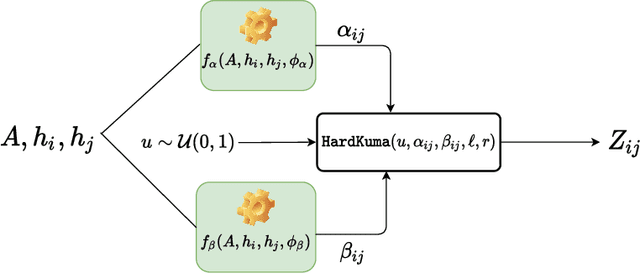
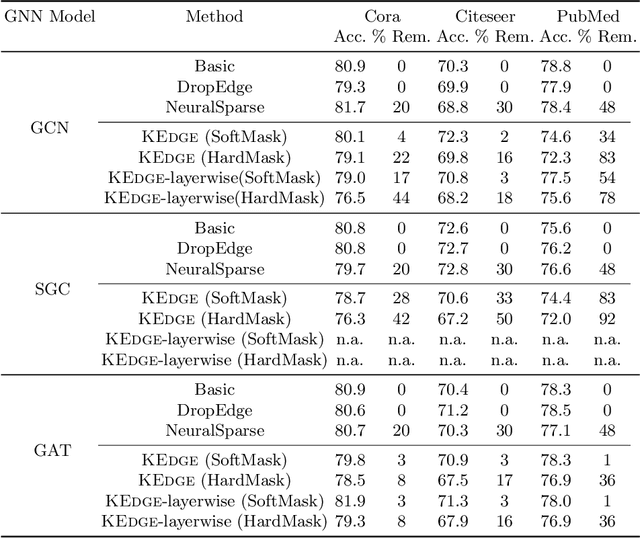
Graph neural networks (GNNs) have achieved great success on various tasks and fields that require relational modeling. GNNs aggregate node features using the graph structure as inductive biases resulting in flexible and powerful models. However, GNNs remain hard to interpret as the interplay between node features and graph structure is only implicitly learned. In this paper, we propose a novel method called Kedge for explicitly sparsifying the underlying graph by removing unnecessary neighbors. Our key idea is based on a tractable method for sparsification using the Hard Kumaraswamy distribution that can be used in conjugation with any GNN model. Kedge learns edge masks in a modular fashion trained with any GNN allowing for gradient based optimization in an end-to-end fashion. We demonstrate through extensive experiments that our model Kedge can prune a large proportion of the edges with only a minor effect on the test accuracy. Specifically, in the PubMed dataset, Kedge learns to drop more than 80% of the edges with an accuracy drop of merely 2% showing that graph structure has only a small contribution in comparison to node features. Finally, we also show that Kedge effectively counters the over-smoothing phenomena in deep GNNs by maintaining good task performance with increasing GNN layers.