 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Foundation Models for 3D Scene Understanding: Instance-Aware Self-Supervised Learning for Point Clouds
Mar 26, 2026Recent advances in self-supervised learning (SSL) for point clouds have substantially improved 3D scene understanding without human annotations. Existing approaches emphasize semantic awareness by enforcing feature consistency across augmented views or by masked scene modeling. However, the resulting representations transfer poorly to instance localization, and often require full finetuning for strong performance. Instance awareness is a fundamental component of 3D perception, thus bridging this gap is crucial for progressing toward true 3D foundation models that support all downstream tasks on 3D data. In this work, we introduce PointINS, an instance-oriented self-supervised framework that enriches point cloud representations through geometry-aware learning. PointINS employs an orthogonal offset branch to jointly learn high-level semantic understanding and geometric reasoning, yielding instance awareness. We identify two consistent properties essential for robust instance localization and formulate them as complementary regularization strategies, Offset Distribution Regularization (ODR), which aligns predicted offsets with empirically observed geometric priors, and Spatial Clustering Regularization (SCR), which enforces local coherence by regularizing offsets with pseudo-instance masks. Through extensive experiments across five datasets, PointINS achieves on average +3.5% mAP improvement for indoor instance segmentation and +4.1% PQ gain for outdoor panoptic segmentation, paving the way for scalable 3D foundation models.
SparseLaneSTP: Leveraging Spatio-Temporal Priors with Sparse Transformers for 3D Lane Detection
Jan 08, 20263D lane detection has emerged as a critical challenge in autonomous driving, encompassing identification and localization of lane markings and the 3D road surface. Conventional 3D methods detect lanes from dense birds-eye-viewed (BEV) features, though erroneous transformations often result in a poor feature representation misaligned with the true 3D road surface. While recent sparse lane detectors have surpassed dense BEV approaches, they completely disregard valuable lane-specific priors. Furthermore, existing methods fail to utilize historic lane observations, which yield the potential to resolve ambiguities in situations of poor visibility. To address these challenges, we present SparseLaneSTP, a novel method that integrates both geometric properties of the lane structure and temporal information into a sparse lane transformer. It introduces a new lane-specific spatio-temporal attention mechanism, a continuous lane representation tailored for sparse architectures as well as temporal regularization. Identifying weaknesses of existing 3D lane datasets, we also introduce a precise and consistent 3D lane dataset using a simple yet effective auto-labeling strategy. Our experimental section proves the benefits of our contributions and demonstrates state-of-the-art performance across all detection and error metrics on existing 3D lane detection benchmarks as well as on our novel dataset.
PseudoMapTrainer: Learning Online Mapping without HD Maps
Aug 26, 2025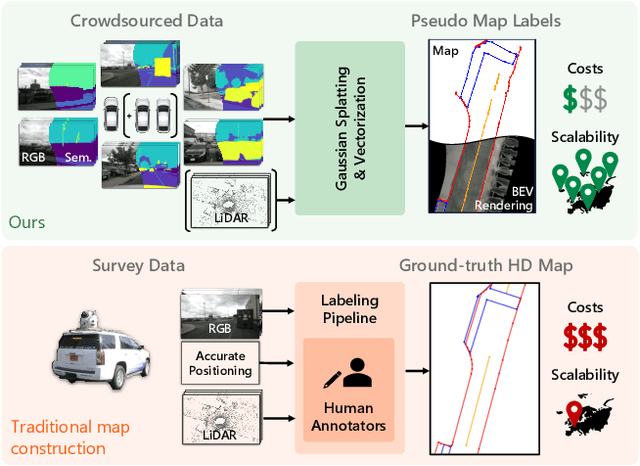
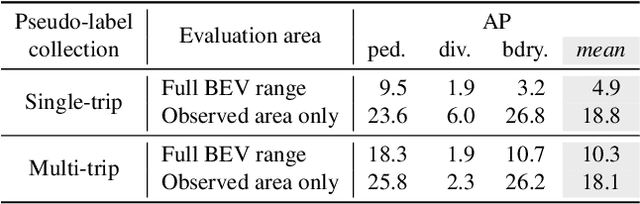
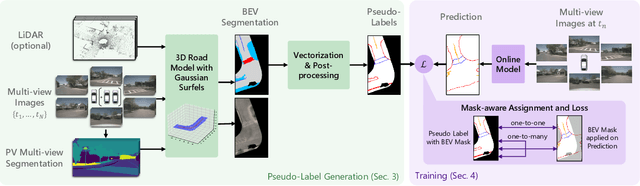
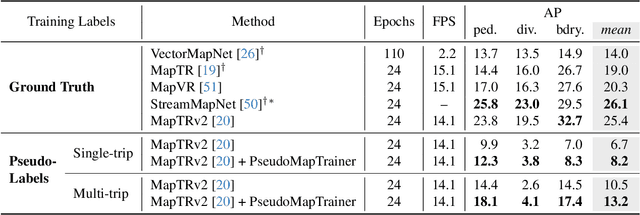
Online mapping models show remarkable results in predicting vectorized maps from multi-view camera images only. However, all existing approaches still rely on ground-truth high-definition maps during training, which are expensive to obtain and often not geographically diverse enough for reliable generalization. In this work, we propose PseudoMapTrainer, a novel approach to online mapping that uses pseudo-labels generated from unlabeled sensor data. We derive those pseudo-labels by reconstructing the road surface from multi-camera imagery using Gaussian splatting and semantics of a pre-trained 2D segmentation network. In addition, we introduce a mask-aware assignment algorithm and loss function to handle partially masked pseudo-labels, allowing for the first time the training of online mapping models without any ground-truth maps. Furthermore, our pseudo-labels can be effectively used to pre-train an online model in a semi-supervised manner to leverage large-scale unlabeled crowdsourced data. The code is available at github.com/boschresearch/PseudoMapTrainer.
Variance-Based Pruning for Accelerating and Compressing Trained Networks
Jul 17, 2025Increasingly expensive training of ever larger models such as Vision Transfomers motivate reusing the vast library of already trained state-of-the-art networks. However, their latency, high computational costs and memory demands pose significant challenges for deployment, especially on resource-constrained hardware. While structured pruning methods can reduce these factors, they often require costly retraining, sometimes for up to hundreds of epochs, or even training from scratch to recover the lost accuracy resulting from the structural modifications. Maintaining the provided performance of trained models after structured pruning and thereby avoiding extensive retraining remains a challenge. To solve this, we introduce Variance-Based Pruning, a simple and structured one-shot pruning technique for efficiently compressing networks, with minimal finetuning. Our approach first gathers activation statistics, which are used to select neurons for pruning. Simultaneously the mean activations are integrated back into the model to preserve a high degree of performance. On ImageNet-1k recognition tasks, we demonstrate that directly after pruning DeiT-Base retains over 70% of its original performance and requires only 10 epochs of fine-tuning to regain 99% of the original accuracy while simultaneously reducing MACs by 35% and model size by 36%, thus speeding up the model by 1.44x.
Efficient Data Driven Mixture-of-Expert Extraction from Trained Networks
May 21, 2025Vision Transformers have emerged as the state-of-the-art models in various Computer Vision tasks, but their high computational and resource demands pose significant challenges. While Mixture-of-Experts (MoE) can make these models more efficient, they often require costly retraining or even training from scratch. Recent developments aim to reduce these computational costs by leveraging pretrained networks. These have been shown to produce sparse activation patterns in the Multi-Layer Perceptrons (MLPs) of the encoder blocks, allowing for conditional activation of only relevant subnetworks for each sample. Building on this idea, we propose a new method to construct MoE variants from pretrained models. Our approach extracts expert subnetworks from the model's MLP layers post-training in two phases. First, we cluster output activations to identify distinct activation patterns. In the second phase, we use these clusters to extract the corresponding subnetworks responsible for producing them. On ImageNet-1k recognition tasks, we demonstrate that these extracted experts can perform surprisingly well out of the box and require only minimal fine-tuning to regain 98% of the original performance, all while reducing MACs and model size, by up to 36% and 32% respectively.
PROM: Prioritize Reduction of Multiplications Over Lower Bit-Widths for Efficient CNNs
May 06, 2025Convolutional neural networks (CNNs) are crucial for computer vision tasks on resource-constrained devices. Quantization effectively compresses these models, reducing storage size and energy cost. However, in modern depthwise-separable architectures, the computational cost is distributed unevenly across its components, with pointwise operations being the most expensive. By applying a general quantization scheme to this imbalanced cost distribution, existing quantization approaches fail to fully exploit potential efficiency gains. To this end, we introduce PROM, a straightforward approach for quantizing modern depthwise-separable convolutional networks by selectively using two distinct bit-widths. Specifically, pointwise convolutions are quantized to ternary weights, while the remaining modules use 8-bit weights, which is achieved through a simple quantization-aware training procedure. Additionally, by quantizing activations to 8-bit, our method transforms pointwise convolutions with ternary weights into int8 additions, which enjoy broad support across hardware platforms and effectively eliminates the need for expensive multiplications. Applying PROM to MobileNetV2 reduces the model's energy cost by more than an order of magnitude (23.9x) and its storage size by 2.7x compared to the float16 baseline while retaining similar classification performance on ImageNet. Our method advances the Pareto frontier for energy consumption vs. top-1 accuracy for quantized convolutional models on ImageNet. PROM addresses the challenges of quantizing depthwise-separable convolutional networks to both ternary and 8-bit weights, offering a simple way to reduce energy cost and storage size.
FLARES: Fast and Accurate LiDAR Multi-Range Semantic Segmentation
Feb 13, 20253D scene understanding is a critical yet challenging task in autonomous driving, primarily due to the irregularity and sparsity of LiDAR data, as well as the computational demands of processing large-scale point clouds. Recent methods leverage the range-view representation to improve processing efficiency. To mitigate the performance drop caused by information loss inherent to the "many-to-one" problem, where multiple nearby 3D points are mapped to the same 2D grids and only the closest is retained, prior works tend to choose a higher azimuth resolution for range-view projection. However, this can bring the drawback of reducing the proportion of pixels that carry information and heavier computation within the network. We argue that it is not the optimal solution and show that, in contrast, decreasing the resolution is more advantageous in both efficiency and accuracy. In this work, we present a comprehensive re-design of the workflow for range-view-based LiDAR semantic segmentation. Our approach addresses data representation, augmentation, and post-processing methods for improvements. Through extensive experiments on two public datasets, we demonstrate that our pipeline significantly enhances the performance of various network architectures over their baselines, paving the way for more effective LiDAR-based perception in autonomous systems.
Unsupervised Point Cloud Registration with Self-Distillation
Sep 11, 2024
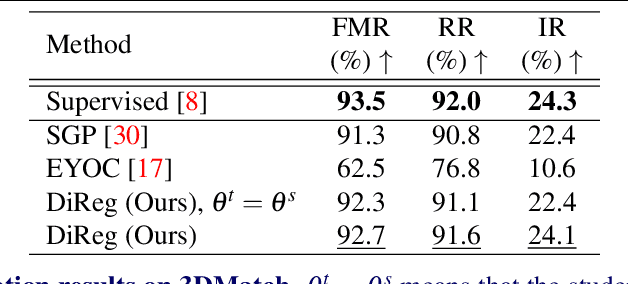
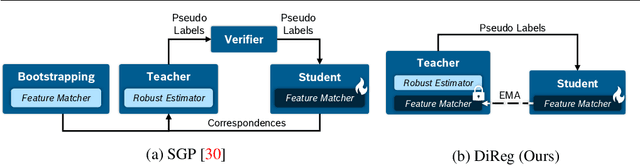
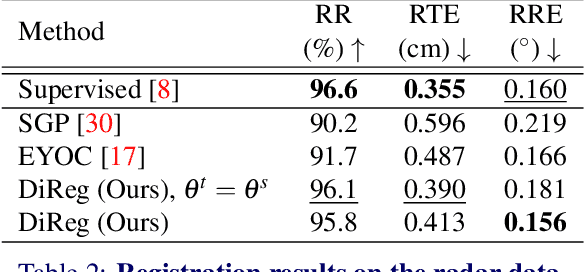
Rigid point cloud registration is a fundamental problem and highly relevant in robotics and autonomous driving. Nowadays deep learning methods can be trained to match a pair of point clouds, given the transformation between them. However, this training is often not scalable due to the high cost of collecting ground truth poses. Therefore, we present a self-distillation approach to learn point cloud registration in an unsupervised fashion. Here, each sample is passed to a teacher network and an augmented view is passed to a student network. The teacher includes a trainable feature extractor and a learning-free robust solver such as RANSAC. The solver forces consistency among correspondences and optimizes for the unsupervised inlier ratio, eliminating the need for ground truth labels. Our approach simplifies the training procedure by removing the need for initial hand-crafted features or consecutive point cloud frames as seen in related methods. We show that our method not only surpasses them on the RGB-D benchmark 3DMatch but also generalizes well to automotive radar, where classical features adopted by others fail. The code is available at https://github.com/boschresearch/direg .
Instant Complexity Reduction in CNNs using Locality-Sensitive Hashing
Sep 29, 2023To reduce the computational cost of convolutional neural networks (CNNs) for usage on resource-constrained devices, structured pruning approaches have shown promising results, drastically reducing floating-point operations (FLOPs) without substantial drops in accuracy. However, most recent methods require fine-tuning or specific training procedures to achieve a reasonable trade-off between retained accuracy and reduction in FLOPs. This introduces additional cost in the form of computational overhead and requires training data to be available. To this end, we propose HASTE (Hashing for Tractable Efficiency), a parameter-free and data-free module that acts as a plug-and-play replacement for any regular convolution module. It instantly reduces the network's test-time inference cost without requiring any training or fine-tuning. We are able to drastically compress latent feature maps without sacrificing much accuracy by using locality-sensitive hashing (LSH) to detect redundancies in the channel dimension. Similar channels are aggregated to reduce the input and filter depth simultaneously, allowing for cheaper convolutions. We demonstrate our approach on the popular vision benchmarks CIFAR-10 and ImageNet. In particular, we are able to instantly drop 46.72% of FLOPs while only losing 1.25% accuracy by just swapping the convolution modules in a ResNet34 on CIFAR-10 for our HASTE module.
Deep Neural Networks with Efficient Guaranteed Invariances
Mar 02, 2023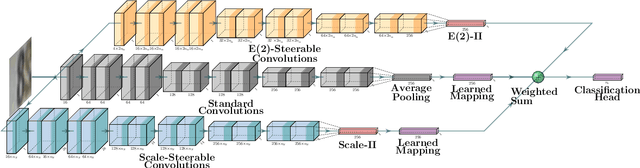
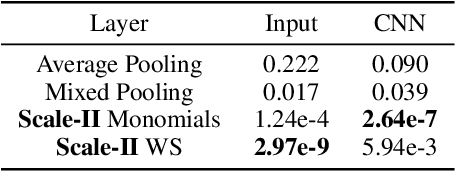
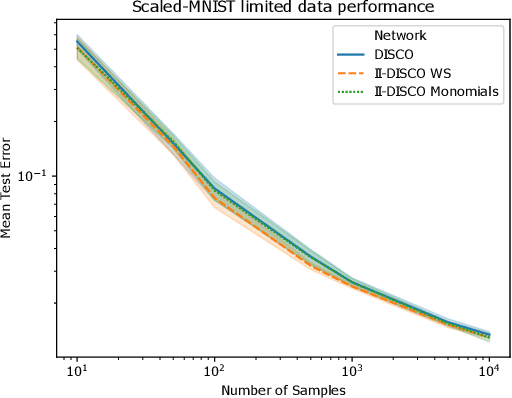

We address the problem of improving the performance and in particular the sample complexity of deep neural networks by enforcing and guaranteeing invariances to symmetry transformations rather than learning them from data. Group-equivariant convolutions are a popular approach to obtain equivariant representations. The desired corresponding invariance is then imposed using pooling operations. For rotations, it has been shown that using invariant integration instead of pooling further improves the sample complexity. In this contribution, we first expand invariant integration beyond rotations to flips and scale transformations. We then address the problem of incorporating multiple desired invariances into a single network. For this purpose, we propose a multi-stream architecture, where each stream is invariant to a different transformation such that the network can simultaneously benefit from multiple invariances. We demonstrate our approach with successful experiments on Scaled-MNIST, SVHN, CIFAR-10 and STL-10.