 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIT: Detecting Uncertainty, Out-Of-Distribution and Adversarial Samples using Gradients and Invariance Transformations
Jul 05, 2023Deep neural networks tend to make overconfident predictions and often require additional detectors for misclassifications, particularly for safety-critical applications. Existing detection methods usually only focus on adversarial attacks or out-of-distribution samples as reasons for false predictions. However, generalization errors occur due to diverse reasons often related to poorly learning relevant invariances. We therefore propose GIT, a holistic approach for the detection of generalization errors that combines the usage of gradient information and invariance transformations. The invariance transformations are designed to shift misclassified samples back into the generalization area of the neural network, while the gradient information measures the contradiction between the initial prediction and the corresponding inherent computations of the neural network using the transformed sample. Our experiments demonstrate the superior performance of GIT compared to the state-of-the-art on a variety of network architectures, problem setups and perturbation types.
* Accepted at IJCNN 2023
A Survey on Assessing the Generalization Envelope of Deep Neural Networks at Inference Time for Image Classification
Aug 24, 2020

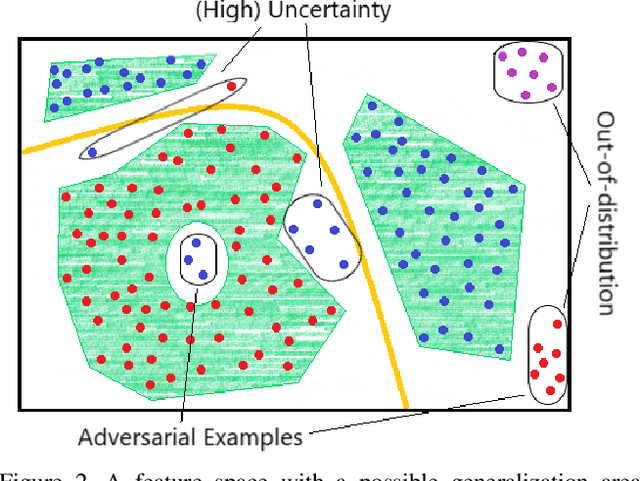
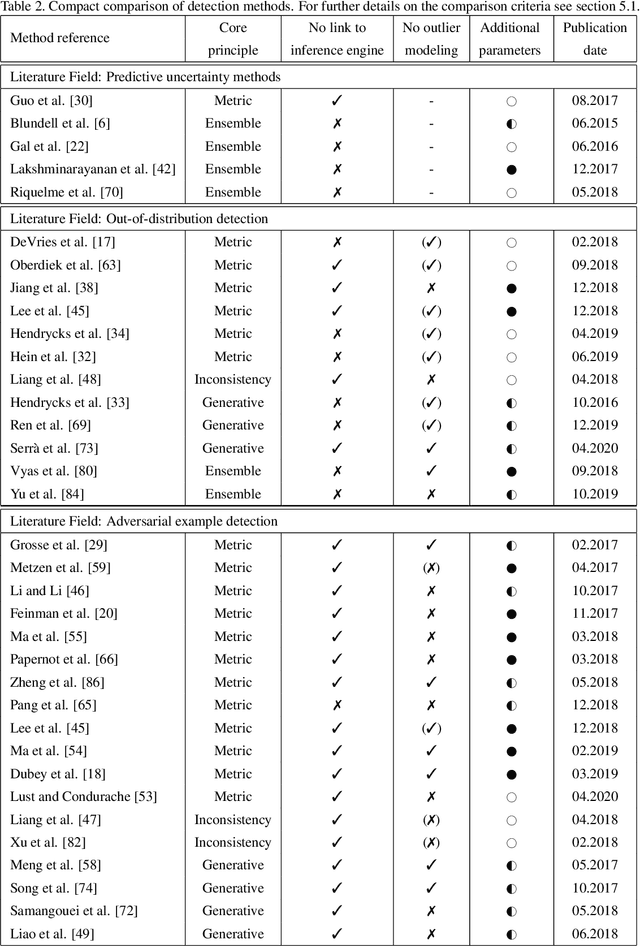
Deep Neural Networks (DNNs) achieve state-of-the-art performance on numerous applications. However, it is difficult to tell beforehand if a DNN receiving an input will deliver the correct output since their decision criteria are usually nontransparent. A DNN delivers the correct output if the input is within the area enclosed by its generalization envelope. In this case, the information contained in the input sample is processed reasonably by the network. It is of large practical importance to assess at inference time if a DNN generalizes correctly. Currently, the approaches to achieve this goal are investigated in different problem set-ups rather independently from one another, leading to three main research and literature fields: predictive uncertainty, out-of-distribution detection and adversarial example detection. This survey connects the three fields within the larger framework of investigating the generalization performance of machine learning methods and in particular DNNs. We underline the common ground, point at the most promising approaches and give a structured overview of the methods that provide at inference time means to establish if the current input is within the generalization envelope of a DNN.
GraN: An Efficient Gradient-Norm Based Detector for Adversarial and Misclassified Examples
Apr 20, 2020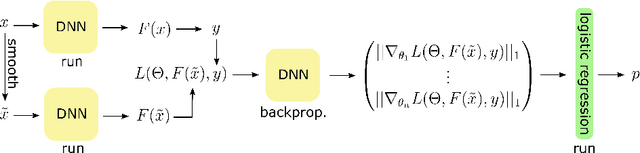
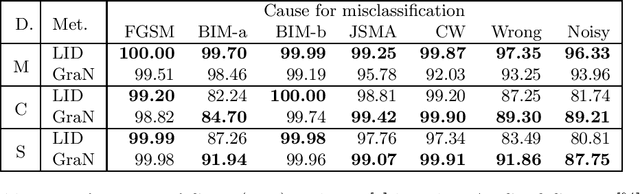
Deep neural networks (DNNs) are vulnerable to adversarial examples and other data perturbations. Especially in safety critical applications of DNNs, it is therefore crucial to detect misclassified samples. The current state-of-the-art detection methods require either significantly more runtime or more parameters than the original network itself. This paper therefore proposes GraN, a time- and parameter-efficient method that is easily adaptable to any DNN. GraN is based on the layer-wise norm of the DNN's gradient regarding the loss of the current input-output combination, which can be computed via backpropagation. GraN achieves state-of-the-art performance on numerous problem set-ups.