 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Based Pruning for Accelerating and Compressing Trained Networks
Jul 17, 2025Increasingly expensive training of ever larger models such as Vision Transfomers motivate reusing the vast library of already trained state-of-the-art networks. However, their latency, high computational costs and memory demands pose significant challenges for deployment, especially on resource-constrained hardware. While structured pruning methods can reduce these factors, they often require costly retraining, sometimes for up to hundreds of epochs, or even training from scratch to recover the lost accuracy resulting from the structural modifications. Maintaining the provided performance of trained models after structured pruning and thereby avoiding extensive retraining remains a challenge. To solve this, we introduce Variance-Based Pruning, a simple and structured one-shot pruning technique for efficiently compressing networks, with minimal finetuning. Our approach first gathers activation statistics, which are used to select neurons for pruning. Simultaneously the mean activations are integrated back into the model to preserve a high degree of performance. On ImageNet-1k recognition tasks, we demonstrate that directly after pruning DeiT-Base retains over 70% of its original performance and requires only 10 epochs of fine-tuning to regain 99% of the original accuracy while simultaneously reducing MACs by 35% and model size by 36%, thus speeding up the model by 1.44x.
Efficient Data Driven Mixture-of-Expert Extraction from Trained Networks
May 21, 2025Vision Transformers have emerged as the state-of-the-art models in various Computer Vision tasks, but their high computational and resource demands pose significant challenges. While Mixture-of-Experts (MoE) can make these models more efficient, they often require costly retraining or even training from scratch. Recent developments aim to reduce these computational costs by leveraging pretrained networks. These have been shown to produce sparse activation patterns in the Multi-Layer Perceptrons (MLPs) of the encoder blocks, allowing for conditional activation of only relevant subnetworks for each sample. Building on this idea, we propose a new method to construct MoE variants from pretrained models. Our approach extracts expert subnetworks from the model's MLP layers post-training in two phases. First, we cluster output activations to identify distinct activation patterns. In the second phase, we use these clusters to extract the corresponding subnetworks responsible for producing them. On ImageNet-1k recognition tasks, we demonstrate that these extracted experts can perform surprisingly well out of the box and require only minimal fine-tuning to regain 98% of the original performance, all while reducing MACs and model size, by up to 36% and 32% respectively.
PROM: Prioritize Reduction of Multiplications Over Lower Bit-Widths for Efficient CNNs
May 06, 2025Convolutional neural networks (CNNs) are crucial for computer vision tasks on resource-constrained devices. Quantization effectively compresses these models, reducing storage size and energy cost. However, in modern depthwise-separable architectures, the computational cost is distributed unevenly across its components, with pointwise operations being the most expensive. By applying a general quantization scheme to this imbalanced cost distribution, existing quantization approaches fail to fully exploit potential efficiency gains. To this end, we introduce PROM, a straightforward approach for quantizing modern depthwise-separable convolutional networks by selectively using two distinct bit-widths. Specifically, pointwise convolutions are quantized to ternary weights, while the remaining modules use 8-bit weights, which is achieved through a simple quantization-aware training procedure. Additionally, by quantizing activations to 8-bit, our method transforms pointwise convolutions with ternary weights into int8 additions, which enjoy broad support across hardware platforms and effectively eliminates the need for expensive multiplications. Applying PROM to MobileNetV2 reduces the model's energy cost by more than an order of magnitude (23.9x) and its storage size by 2.7x compared to the float16 baseline while retaining similar classification performance on ImageNet. Our method advances the Pareto frontier for energy consumption vs. top-1 accuracy for quantized convolutional models on ImageNet. PROM addresses the challenges of quantizing depthwise-separable convolutional networks to both ternary and 8-bit weights, offering a simple way to reduce energy cost and storage size.
Squeeze-and-Remember Block
Oct 01, 2024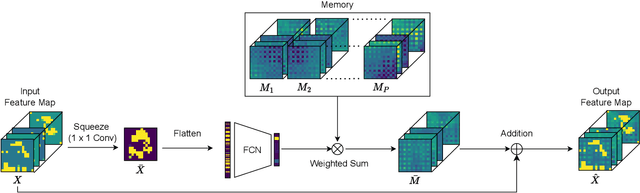
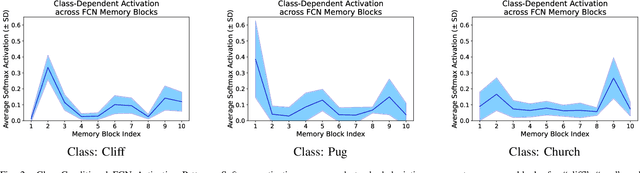
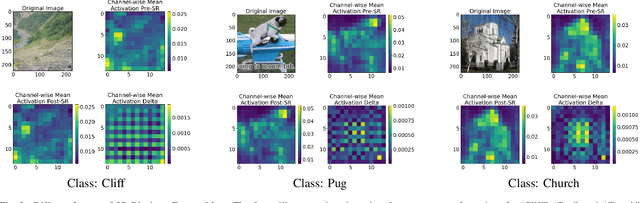
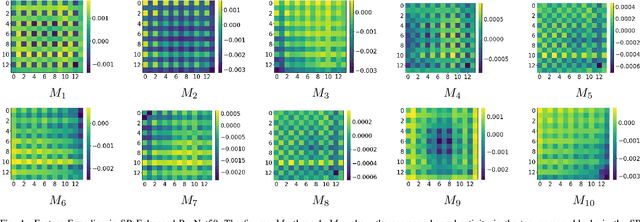
Convolutional Neural Networks (CNNs) are important for many machine learning tasks. They are built with different types of layers: convolutional layers that detect features, dropout layers that help to avoid over-reliance on any single neuron, and residual layers that allow the reuse of features. However, CNNs lack a dynamic feature retention mechanism similar to the human brain's memory, limiting their ability to use learned information in new contexts. To bridge this gap, we introduce the "Squeeze-and-Remember" (SR) block, a novel architectural unit that gives CNNs dynamic memory-like functionalities. The SR block selectively memorizes important features during training, and then adaptively re-applies these features during inference. This improves the network's ability to make contextually informed predictions. Empirical results on ImageNet and Cityscapes datasets demonstrate the SR block's efficacy: integration into ResNet50 improved top-1 validation accuracy on ImageNet by 0.52% over dropout2d alone, and its application in DeepLab v3 increased mean Intersection over Union in Cityscapes by 0.20%. These improvements are achieved with minimal computational overhead. This show the SR block's potential to enhance the capabilities of CNNs in image processing tasks.
Spectral Wavelet Dropout: Regularization in the Wavelet Domain
Sep 27, 2024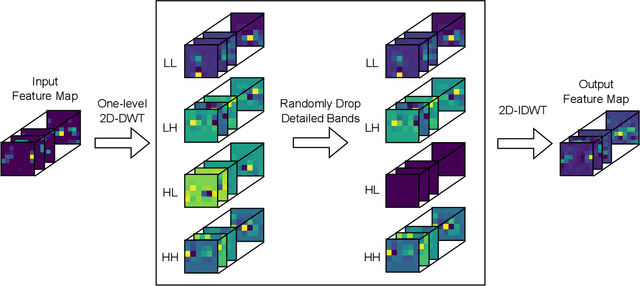
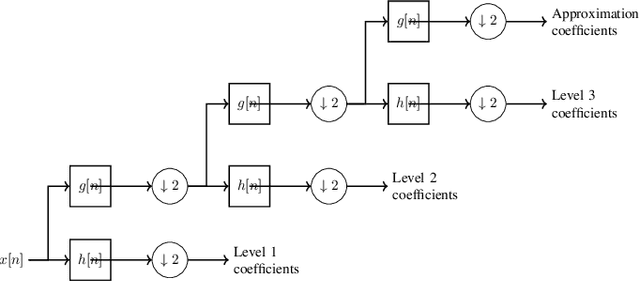


Regularization techniques help prevent overfitting and therefore improve the ability of convolutional neural networks (CNNs) to generalize. One reason for overfitting is the complex co-adaptations among different parts of the network, which make the CNN dependent on their joint response rather than encouraging each part to learn a useful feature representation independently. Frequency domain manipulation is a powerful strategy for modifying data that has temporal and spatial coherence by utilizing frequency decomposition. This work introduces Spectral Wavelet Dropout (SWD), a novel regularization method that includes two variants: 1D-SWD and 2D-SWD. These variants improve CNN generalization by randomly dropping detailed frequency bands in the discrete wavelet decomposition of feature maps. Our approach distinguishes itself from the pre-existing Spectral "Fourier" Dropout (2D-SFD), which eliminates coefficients in the Fourier domain. Notably, SWD requires only a single hyperparameter, unlike the two required by SFD. We also extend the literature by implementing a one-dimensional version of Spectral "Fourier" Dropout (1D-SFD), setting the stage for a comprehensive comparison. Our evaluation shows that both 1D and 2D SWD variants have competitive performance on CIFAR-10/100 benchmarks relative to both 1D-SFD and 2D-SFD. Specifically, 1D-SWD has a significantly lower computational complexity compared to 1D/2D-SFD. In the Pascal VOC Object Detection benchmark, SWD variants surpass 1D-SFD and 2D-SFD in performance and demonstrate lower computational complexity during training.
CNN Mixture-of-Depths
Sep 25, 2024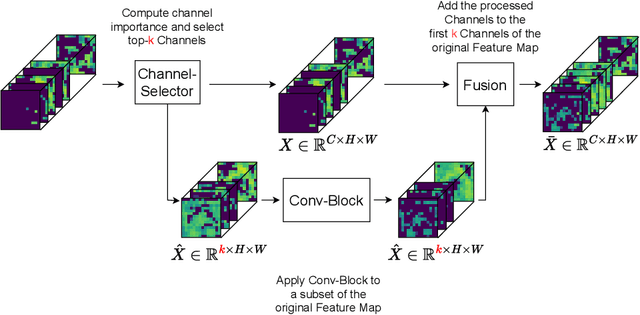

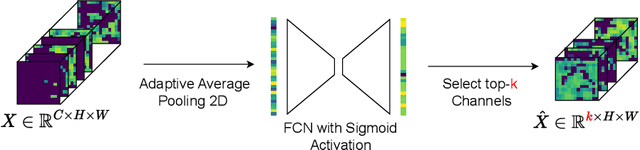

We introduce Mixture-of-Depths (MoD) for Convolutional Neural Networks (CNNs), a novel approach that enhances the computational efficiency of CNNs by selectively processing channels based on their relevance to the current prediction. This method optimizes computational resources by dynamically selecting key channels in feature maps for focused processing within the convolutional blocks (Conv-Blocks), while skipping less relevant channels. Unlike conditional computation methods that require dynamic computation graphs, CNN MoD uses a static computation graph with fixed tensor sizes which improve hardware efficiency. It speeds up the training and inference processes without the need for customized CUDA kernels, unique loss functions, or finetuning. CNN MoD either matches the performance of traditional CNNs with reduced inference times, GMACs, and parameters, or exceeds their performance while maintaining similar inference times, GMACs, and parameters. For example, on ImageNet, ResNet86-MoD exceeds the performance of the standard ResNet50 by 0.45% with a 6% speedup on CPU and 5% on GPU. Moreover, ResNet75-MoD achieves the same performance as ResNet50 with a 25% speedup on CPU and 15% on GPU.
Instant Complexity Reduction in CNNs using Locality-Sensitive Hashing
Sep 29, 2023To reduce the computational cost of convolutional neural networks (CNNs) for usage on resource-constrained devices, structured pruning approaches have shown promising results, drastically reducing floating-point operations (FLOPs) without substantial drops in accuracy. However, most recent methods require fine-tuning or specific training procedures to achieve a reasonable trade-off between retained accuracy and reduction in FLOPs. This introduces additional cost in the form of computational overhead and requires training data to be available. To this end, we propose HASTE (Hashing for Tractable Efficiency), a parameter-free and data-free module that acts as a plug-and-play replacement for any regular convolution module. It instantly reduces the network's test-time inference cost without requiring any training or fine-tuning. We are able to drastically compress latent feature maps without sacrificing much accuracy by using locality-sensitive hashing (LSH) to detect redundancies in the channel dimension. Similar channels are aggregated to reduce the input and filter depth simultaneously, allowing for cheaper convolutions. We demonstrate our approach on the popular vision benchmarks CIFAR-10 and ImageNet. In particular, we are able to instantly drop 46.72% of FLOPs while only losing 1.25% accuracy by just swapping the convolution modules in a ResNet34 on CIFAR-10 for our HASTE module.
Weight Compander: A Simple Weight Reparameterization for Regularization
Jun 29, 2023Regularization is a set of techniques that are used to improve the generalization ability of deep neural networks. In this paper, we introduce weight compander (WC), a novel effective method to improve generalization by reparameterizing each weight in deep neural networks using a nonlinear function. It is a general, intuitive, cheap and easy to implement method, which can be combined with various other regularization techniques. Large weights in deep neural networks are a sign of a more complex network that is overfitted to the training data. Moreover, regularized networks tend to have a greater range of weights around zero with fewer weights centered at zero. We introduce a weight reparameterization function which is applied to each weight and implicitly reduces overfitting by restricting the magnitude of the weights while forcing them away from zero at the same time. This leads to a more democratic decision-making in the network. Firstly, individual weights cannot have too much influence in the prediction process due to the restriction of their magnitude. Secondly, more weights are used in the prediction process, since they are forced away from zero during the training. This promotes the extraction of more features from the input data and increases the level of weight redundancy, which makes the network less sensitive to statistical differences between training and test data. We extend our method to learn the hyperparameters of the introduced weight reparameterization function. This avoids hyperparameter search and gives the network the opportunity to align the weight reparameterization with the training progress. We show experimentally that using weight compander in addition to standard regularization methods improves the performance of neural networks.
* Accepted by The International Joint Conference on Neural Network (IJCNN) 2023
Spectral Batch Normalization: Normalization in the Frequency Domain
Jun 29, 2023Regularization is a set of techniques that are used to improve the generalization ability of deep neural networks. In this paper, we introduce spectral batch normalization (SBN), a novel effective method to improve generalization by normalizing feature maps in the frequency (spectral) domain. The activations of residual networks without batch normalization (BN) tend to explode exponentially in the depth of the network at initialization. This leads to extremely large feature map norms even though the parameters are relatively small. These explosive dynamics can be very detrimental to learning. BN makes weight decay regularization on the scaling factors $\gamma, \beta$ approximately equivalent to an additive penalty on the norm of the feature maps, which prevents extremely large feature map norms to a certain degree. However, we show experimentally that, despite the approximate additive penalty of BN, feature maps in deep neural networks (DNNs) tend to explode at the beginning of the network and that feature maps of DNNs contain large values during the whole training. This phenomenon also occurs in a weakened form in non-residual networks. SBN addresses large feature maps by normalizing them in the frequency domain. In our experiments, we empirically show that SBN prevents exploding feature maps at initialization and large feature map values during the training. Moreover, the normalization of feature maps in the frequency domain leads to more uniform distributed frequency components. This discourages the DNNs to rely on single frequency components of feature maps. These, together with other effects of SBN, have a regularizing effect on the training of residual and non-residual networks. We show experimentally that using SBN in addition to standard regularization methods improves the performance of DNNs by a relevant margin, e.g. ResNet50 on ImageNet by 0.71%.
* Accepted by The International Joint Conference on Neural Network (IJCNN) 2023
Dimensionality Reduced Training by Pruning and Freezing Parts of a Deep Neural Network, a Survey
May 17, 2022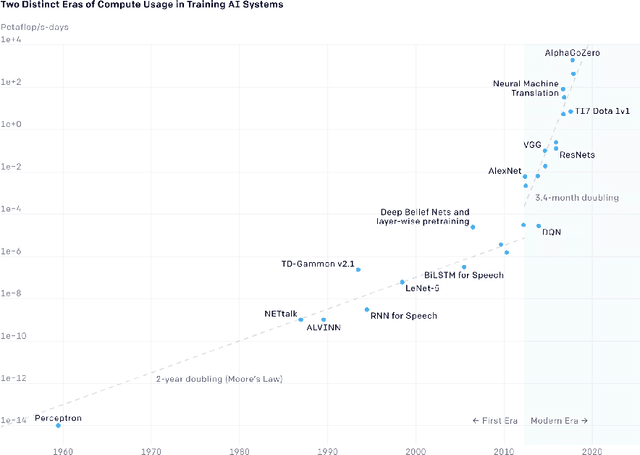
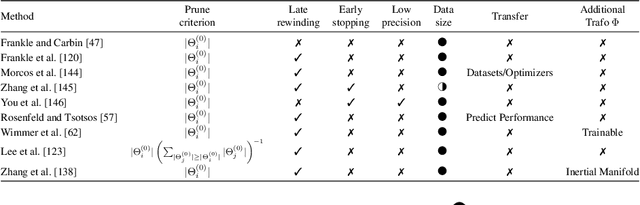
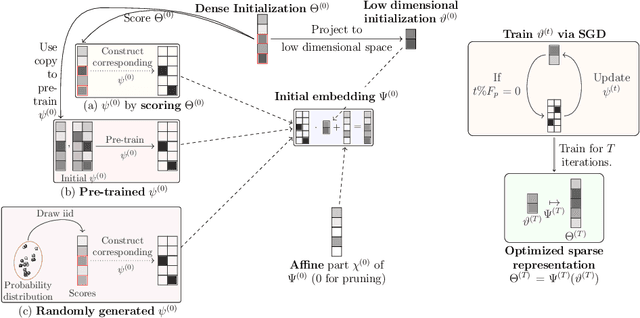

State-of-the-art deep learning models have a parameter count that reaches into the billions. Training, storing and transferring such models is energy and time consuming, thus costly. A big part of these costs is caused by training the network. Model compression lowers storage and transfer costs, and can further make training more efficient by decreasing the number of computations in the forward and/or backward pass. Thus, compressing networks also at training time while maintaining a high performance is an important research topic. This work is a survey on methods which reduce the number of trained weights in deep learning models throughout the training. Most of the introduced methods set network parameters to zero which is called pruning. The presented pruning approaches are categorized into pruning at initialization, lottery tickets and dynamic sparse training. Moreover, we discuss methods that freeze parts of a network at its random initialization. By freezing weights, the number of trainable parameters is shrunken which reduces gradient computations and the dimensionality of the model's optimization space. In this survey we first propose dimensionality reduced training as an underlying mathematical model that covers pruning and freezing during training. Afterwards, we present and discuss different dimensionality reduced training methods.