 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduced Training by Pruning and Freezing Parts of a Deep Neural Network, a Survey
May 17, 2022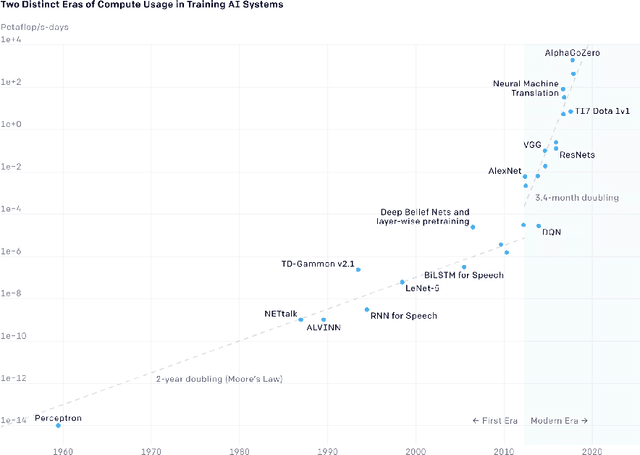
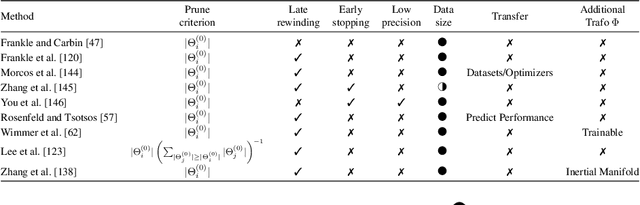
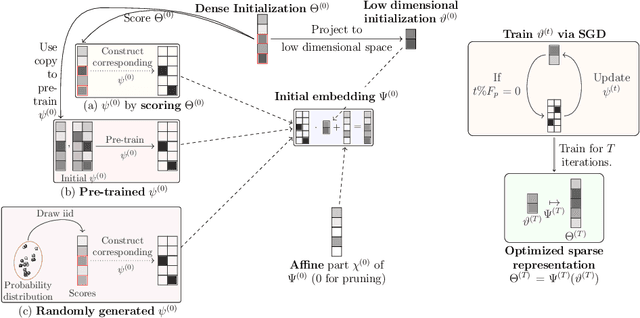

State-of-the-art deep learning models have a parameter count that reaches into the billions. Training, storing and transferring such models is energy and time consuming, thus costly. A big part of these costs is caused by training the network. Model compression lowers storage and transfer costs, and can further make training more efficient by decreasing the number of computations in the forward and/or backward pass. Thus, compressing networks also at training time while maintaining a high performance is an important research topic. This work is a survey on methods which reduce the number of trained weights in deep learning models throughout the training. Most of the introduced methods set network parameters to zero which is called pruning. The presented pruning approaches are categorized into pruning at initialization, lottery tickets and dynamic sparse training. Moreover, we discuss methods that freeze parts of a network at its random initialization. By freezing weights, the number of trainable parameters is shrunken which reduces gradient computations and the dimensionality of the model's optimization space. In this survey we first propose dimensionality reduced training as an underlying mathematical model that covers pruning and freezing during training. Afterwards, we present and discuss different dimensionality reduced training methods.
Interspace Pruning: Using Adaptive Filter Representations to Improve Training of Sparse CNNs
Mar 15, 2022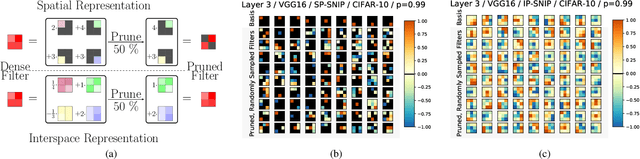

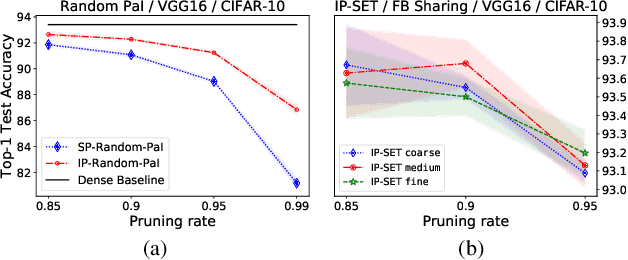
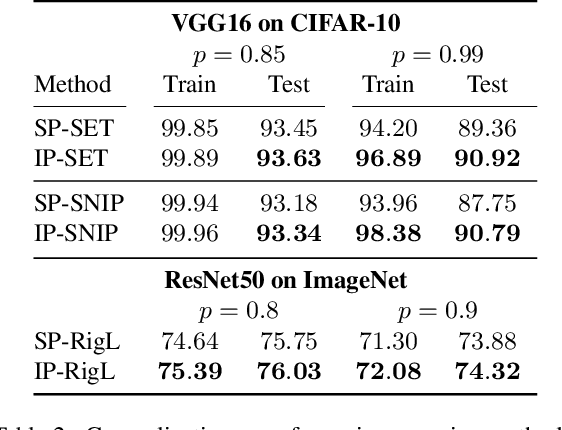
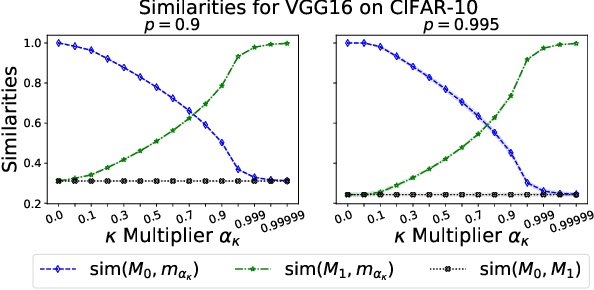
Unstructured pruning is well suited to reduce the memory footprint of convolutional neural networks (CNNs), both at training and inference time. CNNs contain parameters arranged in $K \times K$ filters. Standard unstructured pruning (SP) reduces the memory footprint of CNNs by setting filter elements to zero, thereby specifying a fixed subspace that constrains the filter. Especially if pruning is applied before or during training, this induces a strong bias. To overcome this, we introduce interspace pruning (IP), a general tool to improve existing pruning methods. It uses filters represented in a dynamic interspace by linear combinations of an underlying adaptive filter basis (FB). For IP, FB coefficients are set to zero while un-pruned coefficients and FBs are trained jointly. In this work, we provide mathematical evidence for IP's superior performance and demonstrate that IP outperforms SP on all tested state-of-the-art unstructured pruning methods. Especially in challenging situations, like pruning for ImageNet or pruning to high sparsity, IP greatly exceeds SP with equal runtime and parameter costs. Finally, we show that advances of IP are due to improved trainability and superior generalization ability.
COPS: Controlled Pruning Before Training Starts
Jul 27, 2021
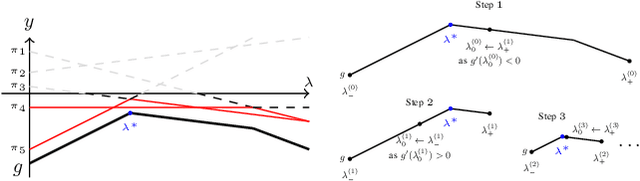

State-of-the-art deep neural network (DNN) pruning techniques, applied one-shot before training starts, evaluate sparse architectures with the help of a single criterion -- called pruning score. Pruning weights based on a solitary score works well for some architectures and pruning rates but may also fail for other ones. As a common baseline for pruning scores, we introduce the notion of a generalized synaptic score (GSS). In this work we do not concentrate on a single pruning criterion, but provide a framework for combining arbitrary GSSs to create more powerful pruning strategies. These COmbined Pruning Scores (COPS) are obtained by solving a constrained optimization problem. Optimizing for more than one score prevents the sparse network to overly specialize on an individual task, thus COntrols Pruning before training Starts. The combinatorial optimization problem given by COPS is relaxed on a linear program (LP). This LP is solved analytically and determines a solution for COPS. Furthermore, an algorithm to compute it for two scores numerically is proposed and evaluated. Solving COPS in such a way has lower complexity than the best general LP solver. In our experiments we compared pruning with COPS against state-of-the-art methods for different network architectures and image classification tasks and obtained improved results.
FreezeNet: Full Performance by Reduced Storage Costs
Nov 28, 2020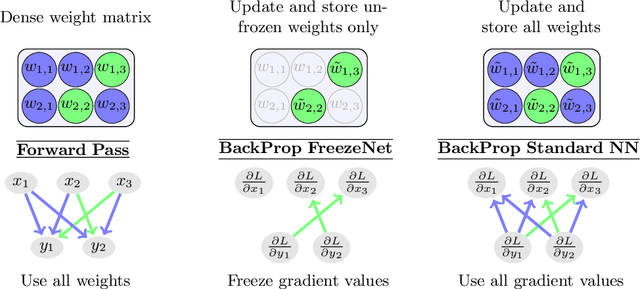


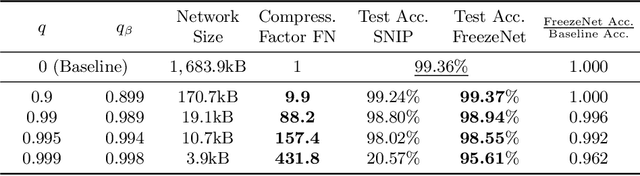
Pruning generates sparse networks by setting parameters to zero. In this work we improve one-shot pruning methods, applied before training, without adding any additional storage costs while preserving the sparse gradient computations. The main difference to pruning is that we do not sparsify the network's weights but learn just a few key parameters and keep the other ones fixed at their random initialized value. This mechanism is called freezing the parameters. Those frozen weights can be stored efficiently with a single 32bit random seed number. The parameters to be frozen are determined one-shot by a single for- and backward pass applied before training starts. We call the introduced method FreezeNet. In our experiments we show that FreezeNets achieve good results, especially for extreme freezing rates. Freezing weights preserves the gradient flow throughout the network and consequently, FreezeNets train better and have an increased capacity compared to their pruned counterparts. On the classification tasks MNIST and CIFAR-10/100 we outperform SNIP, in this setting the best reported one-shot pruning method, applied before training. On MNIST, FreezeNet achieves 99.2% performance of the baseline LeNet-5-Caffe architecture, while compressing the number of trained and stored parameters by a factor of x 157.