 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreezeNet: Full Performance by Reduced Storage Costs
Paper and Code
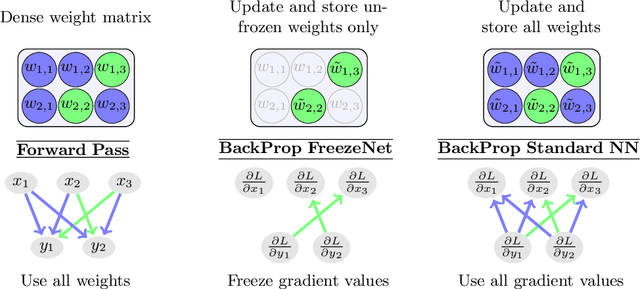


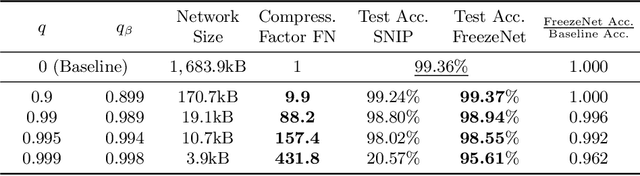
Pruning generates sparse networks by setting parameters to zero. In this work we improve one-shot pruning methods, applied before training, without adding any additional storage costs while preserving the sparse gradient computations. The main difference to pruning is that we do not sparsify the network's weights but learn just a few key parameters and keep the other ones fixed at their random initialized value. This mechanism is called freezing the parameters. Those frozen weights can be stored efficiently with a single 32bit random seed number. The parameters to be frozen are determined one-shot by a single for- and backward pass applied before training starts. We call the introduced method FreezeNet. In our experiments we show that FreezeNets achieve good results, especially for extreme freezing rates. Freezing weights preserves the gradient flow throughout the network and consequently, FreezeNets train better and have an increased capacity compared to their pruned counterparts. On the classification tasks MNIST and CIFAR-10/100 we outperform SNIP, in this setting the best reported one-shot pruning method, applied before training. On MNIST, FreezeNet achieves 99.2% performance of the baseline LeNet-5-Caffe architecture, while compressing the number of trained and stored parameters by a factor of x 157.