 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Integration of Prediction and Planning in Deep Learning-Based Automated Driving Systems: A Review
Aug 10, 2023
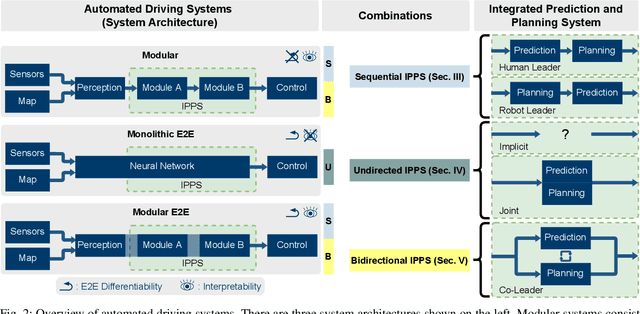
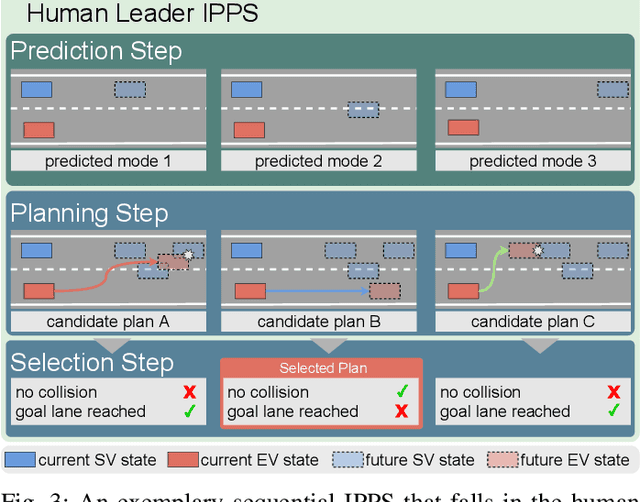
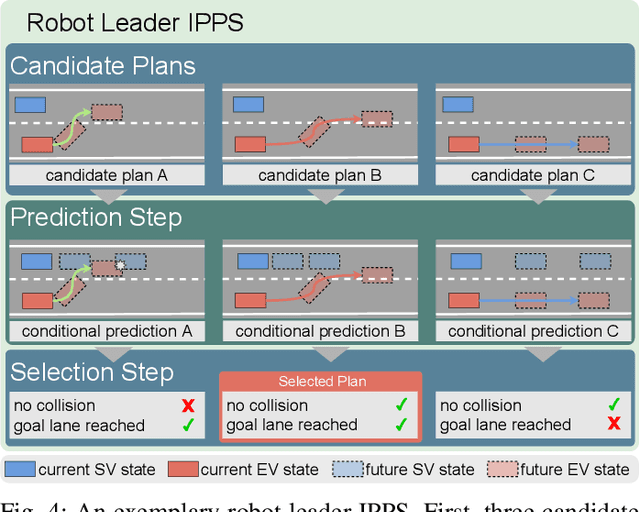
Automated driving has the potential to revolutionize personal, public, and freight mobility. Besides the enormous challenge of perception, i.e. accurately perceiving the environment using available sensor data, automated driving comprises planning a safe, comfortable, and efficient motion trajectory. To promote safety and progress, many works rely on modules that predict the future motion of surrounding traffic. Modular automated driving systems commonly handle prediction and planning as sequential separate tasks. While this accounts for the influence of surrounding traffic on the ego-vehicle, it fails to anticipate the reactions of traffic participants to the ego-vehicle's behavior. Recent works suggest that integrating prediction and planning in an interdependent joint step is necessary to achieve safe, efficient, and comfortable driving. While various models implement such integrated systems, a comprehensive overview and theoretical understanding of different principles are lacking. We systematically review state-of-the-art deep learning-based prediction, planning, and integrated prediction and planning models. Different facets of the integration ranging from model architecture and model design to behavioral aspects are considered and related to each other. Moreover, we discuss the implications, strengths, and limitations of different integration methods. By pointing out research gaps, describing relevant future challenges, and highlighting trends in the research field, we identify promising directions for future research.
COPS: Controlled Pruning Before Training Starts
Jul 27, 2021
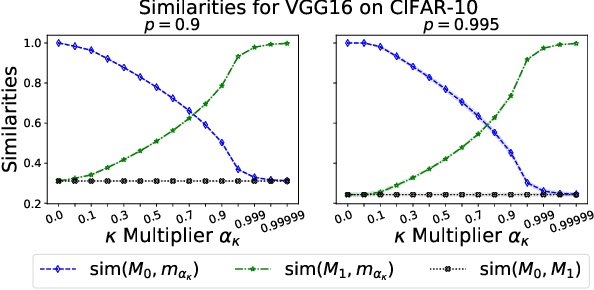
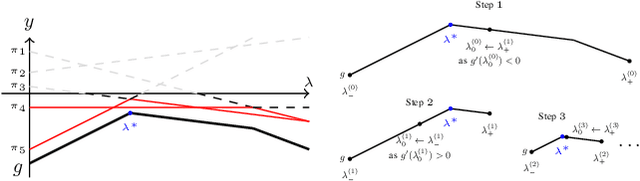

State-of-the-art deep neural network (DNN) pruning techniques, applied one-shot before training starts, evaluate sparse architectures with the help of a single criterion -- called pruning score. Pruning weights based on a solitary score works well for some architectures and pruning rates but may also fail for other ones. As a common baseline for pruning scores, we introduce the notion of a generalized synaptic score (GSS). In this work we do not concentrate on a single pruning criterion, but provide a framework for combining arbitrary GSSs to create more powerful pruning strategies. These COmbined Pruning Scores (COPS) are obtained by solving a constrained optimization problem. Optimizing for more than one score prevents the sparse network to overly specialize on an individual task, thus COntrols Pruning before training Starts. The combinatorial optimization problem given by COPS is relaxed on a linear program (LP). This LP is solved analytically and determines a solution for COPS. Furthermore, an algorithm to compute it for two scores numerically is proposed and evaluated. Solving COPS in such a way has lower complexity than the best general LP solver. In our experiments we compared pruning with COPS against state-of-the-art methods for different network architectures and image classification tasks and obtained improved results.
FreezeNet: Full Performance by Reduced Storage Costs
Nov 28, 2020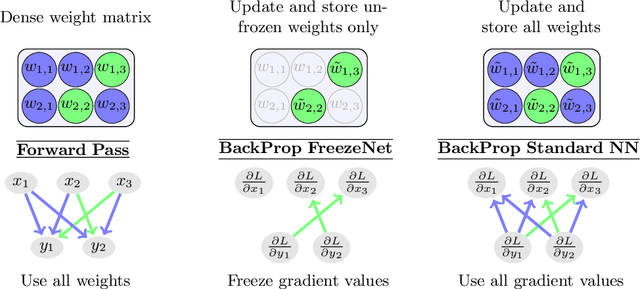


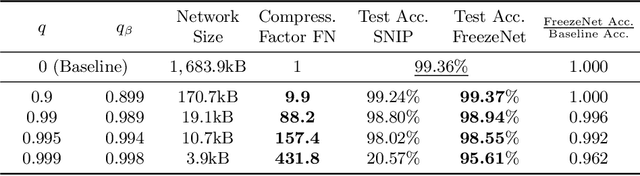
Pruning generates sparse networks by setting parameters to zero. In this work we improve one-shot pruning methods, applied before training, without adding any additional storage costs while preserving the sparse gradient computations. The main difference to pruning is that we do not sparsify the network's weights but learn just a few key parameters and keep the other ones fixed at their random initialized value. This mechanism is called freezing the parameters. Those frozen weights can be stored efficiently with a single 32bit random seed number. The parameters to be frozen are determined one-shot by a single for- and backward pass applied before training starts. We call the introduced method FreezeNet. In our experiments we show that FreezeNets achieve good results, especially for extreme freezing rates. Freezing weights preserves the gradient flow throughout the network and consequently, FreezeNets train better and have an increased capacity compared to their pruned counterparts. On the classification tasks MNIST and CIFAR-10/100 we outperform SNIP, in this setting the best reported one-shot pruning method, applied before training. On MNIST, FreezeNet achieves 99.2% performance of the baseline LeNet-5-Caffe architecture, while compressing the number of trained and stored parameters by a factor of x 157.