 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze-and-Remember Block
Oct 01, 2024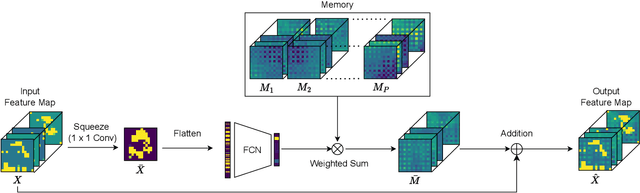
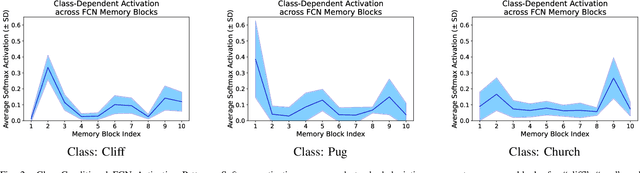
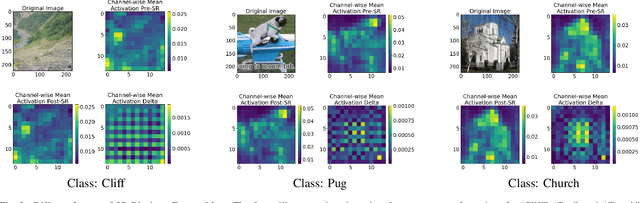
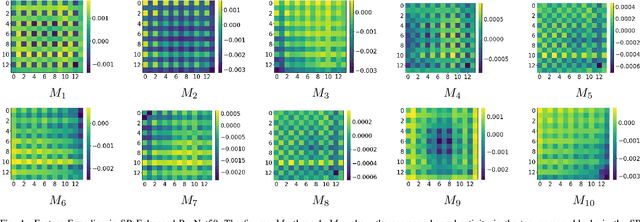
Convolutional Neural Networks (CNNs) are important for many machine learning tasks. They are built with different types of layers: convolutional layers that detect features, dropout layers that help to avoid over-reliance on any single neuron, and residual layers that allow the reuse of features. However, CNNs lack a dynamic feature retention mechanism similar to the human brain's memory, limiting their ability to use learned information in new contexts. To bridge this gap, we introduce the "Squeeze-and-Remember" (SR) block, a novel architectural unit that gives CNNs dynamic memory-like functionalities. The SR block selectively memorizes important features during training, and then adaptively re-applies these features during inference. This improves the network's ability to make contextually informed predictions. Empirical results on ImageNet and Cityscapes datasets demonstrate the SR block's efficacy: integration into ResNet50 improved top-1 validation accuracy on ImageNet by 0.52% over dropout2d alone, and its application in DeepLab v3 increased mean Intersection over Union in Cityscapes by 0.20%. These improvements are achieved with minimal computational overhead. This show the SR block's potential to enhance the capabilities of CNNs in image processing tasks.
Spectral Wavelet Dropout: Regularization in the Wavelet Domain
Sep 27, 2024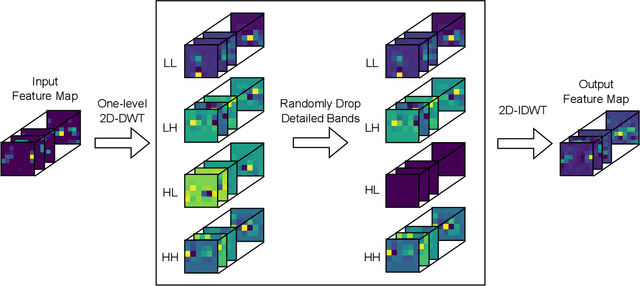
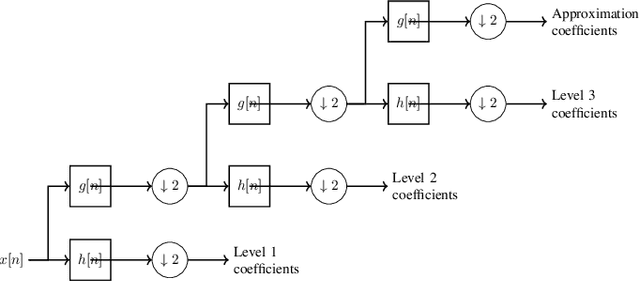


Regularization techniques help prevent overfitting and therefore improve the ability of convolutional neural networks (CNNs) to generalize. One reason for overfitting is the complex co-adaptations among different parts of the network, which make the CNN dependent on their joint response rather than encouraging each part to learn a useful feature representation independently. Frequency domain manipulation is a powerful strategy for modifying data that has temporal and spatial coherence by utilizing frequency decomposition. This work introduces Spectral Wavelet Dropout (SWD), a novel regularization method that includes two variants: 1D-SWD and 2D-SWD. These variants improve CNN generalization by randomly dropping detailed frequency bands in the discrete wavelet decomposition of feature maps. Our approach distinguishes itself from the pre-existing Spectral "Fourier" Dropout (2D-SFD), which eliminates coefficients in the Fourier domain. Notably, SWD requires only a single hyperparameter, unlike the two required by SFD. We also extend the literature by implementing a one-dimensional version of Spectral "Fourier" Dropout (1D-SFD), setting the stage for a comprehensive comparison. Our evaluation shows that both 1D and 2D SWD variants have competitive performance on CIFAR-10/100 benchmarks relative to both 1D-SFD and 2D-SFD. Specifically, 1D-SWD has a significantly lower computational complexity compared to 1D/2D-SFD. In the Pascal VOC Object Detection benchmark, SWD variants surpass 1D-SFD and 2D-SFD in performance and demonstrate lower computational complexity during training.
CNN Mixture-of-Depths
Sep 25, 2024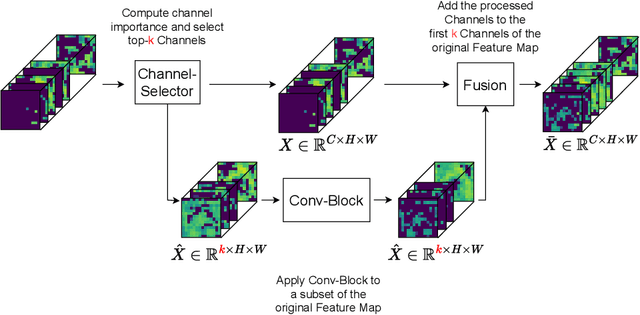

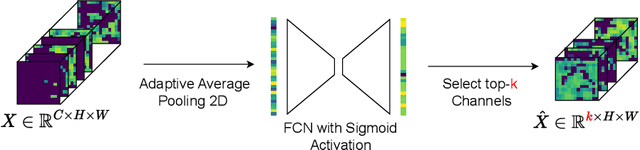

We introduce Mixture-of-Depths (MoD) for Convolutional Neural Networks (CNNs), a novel approach that enhances the computational efficiency of CNNs by selectively processing channels based on their relevance to the current prediction. This method optimizes computational resources by dynamically selecting key channels in feature maps for focused processing within the convolutional blocks (Conv-Blocks), while skipping less relevant channels. Unlike conditional computation methods that require dynamic computation graphs, CNN MoD uses a static computation graph with fixed tensor sizes which improve hardware efficiency. It speeds up the training and inference processes without the need for customized CUDA kernels, unique loss functions, or finetuning. CNN MoD either matches the performance of traditional CNNs with reduced inference times, GMACs, and parameters, or exceeds their performance while maintaining similar inference times, GMACs, and parameters. For example, on ImageNet, ResNet86-MoD exceeds the performance of the standard ResNet50 by 0.45% with a 6% speedup on CPU and 5% on GPU. Moreover, ResNet75-MoD achieves the same performance as ResNet50 with a 25% speedup on CPU and 15% on GPU.
Spectral Batch Normalization: Normalization in the Frequency Domain
Jun 29, 2023Regularization is a set of techniques that are used to improve the generalization ability of deep neural networks. In this paper, we introduce spectral batch normalization (SBN), a novel effective method to improve generalization by normalizing feature maps in the frequency (spectral) domain. The activations of residual networks without batch normalization (BN) tend to explode exponentially in the depth of the network at initialization. This leads to extremely large feature map norms even though the parameters are relatively small. These explosive dynamics can be very detrimental to learning. BN makes weight decay regularization on the scaling factors $\gamma, \beta$ approximately equivalent to an additive penalty on the norm of the feature maps, which prevents extremely large feature map norms to a certain degree. However, we show experimentally that, despite the approximate additive penalty of BN, feature maps in deep neural networks (DNNs) tend to explode at the beginning of the network and that feature maps of DNNs contain large values during the whole training. This phenomenon also occurs in a weakened form in non-residual networks. SBN addresses large feature maps by normalizing them in the frequency domain. In our experiments, we empirically show that SBN prevents exploding feature maps at initialization and large feature map values during the training. Moreover, the normalization of feature maps in the frequency domain leads to more uniform distributed frequency components. This discourages the DNNs to rely on single frequency components of feature maps. These, together with other effects of SBN, have a regularizing effect on the training of residual and non-residual networks. We show experimentally that using SBN in addition to standard regularization methods improves the performance of DNNs by a relevant margin, e.g. ResNet50 on ImageNet by 0.71%.
* Accepted by The International Joint Conference on Neural Network (IJCNN) 2023
Weight Compander: A Simple Weight Reparameterization for Regularization
Jun 29, 2023Regularization is a set of techniques that are used to improve the generalization ability of deep neural networks. In this paper, we introduce weight compander (WC), a novel effective method to improve generalization by reparameterizing each weight in deep neural networks using a nonlinear function. It is a general, intuitive, cheap and easy to implement method, which can be combined with various other regularization techniques. Large weights in deep neural networks are a sign of a more complex network that is overfitted to the training data. Moreover, regularized networks tend to have a greater range of weights around zero with fewer weights centered at zero. We introduce a weight reparameterization function which is applied to each weight and implicitly reduces overfitting by restricting the magnitude of the weights while forcing them away from zero at the same time. This leads to a more democratic decision-making in the network. Firstly, individual weights cannot have too much influence in the prediction process due to the restriction of their magnitude. Secondly, more weights are used in the prediction process, since they are forced away from zero during the training. This promotes the extraction of more features from the input data and increases the level of weight redundancy, which makes the network less sensitive to statistical differences between training and test data. We extend our method to learn the hyperparameters of the introduced weight reparameterization function. This avoids hyperparameter search and gives the network the opportunity to align the weight reparameterization with the training progress. We show experimentally that using weight compander in addition to standard regularization methods improves the performance of neural networks.
* Accepted by The International Joint Conference on Neural Network (IJCNN) 2023