 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attack on Graph Neural Networks
Paper and Code
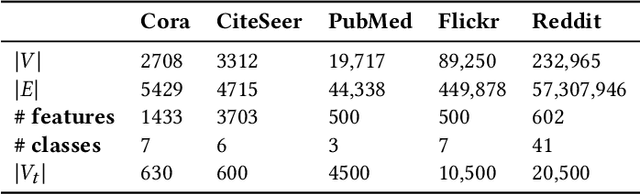
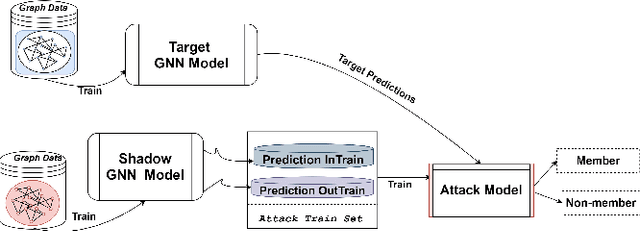
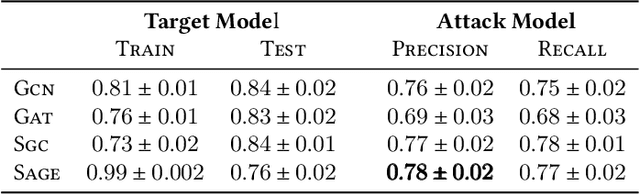
Graph Neural Networks (GNNs), which generalize traditional deep neural networks or graph data, have achieved state of the art performance on several graph analytical tasks like node classification, link prediction or graph classification. We focus on how trained GNN models could leak information about the \emph{member} nodes that they were trained on. In particular, we focus on answering the question: given a graph, can we determine which nodes were used for training the GNN model? We operate in the inductive settings for node classification, which means that none of the nodes in the test set (or the \emph{non-member} nodes) were seen during the training. We propose a simple attack model which is able to distinguish between the member and non-member nodes while just having a black-box access to the model. We experimentally compare the privacy risks of four representative GNN models. Our results show that all the studied GNN models are vulnerable to privacy leakage. While in traditional machine learning models, overfitting is considered the main cause of such leakage, we show that in GNNs the additional structural information is the major contributing factor.