 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Horizon Time Series Forecasting of non-parametric CDFs with Deep Lattice Networks
Nov 14, 2025Probabilistic forecasting is not only a way to add more information to a prediction of the future, but it also builds on weaknesses in point prediction. Sudden changes in a time series can still be captured by a cumulative distribution function (CDF), while a point prediction is likely to miss it entirely. The modeling of CDFs within forecasts has historically been limited to parametric approaches, but due to recent advances, this no longer has to be the case. We aim to advance the fields of probabilistic forecasting and monotonic networks by connecting them and propose an approach that permits the forecasting of implicit, complete, and nonparametric CDFs. For this purpose, we propose an adaptation to deep lattice networks (DLN) for monotonically constrained simultaneous/implicit quantile regression in time series forecasting. Quantile regression usually produces quantile crossovers, which need to be prevented to achieve a legitimate CDF. By leveraging long short term memory units (LSTM) as the embedding layer, and spreading quantile inputs to all sub-lattices of a DLN with an extended output size, we can produce a multi-horizon forecast of an implicit CDF due to the monotonic constraintability of DLNs that prevent quantile crossovers. We compare and evaluate our approach's performance to relevant state of the art within the context of a highly relevant application of time series forecasting: Day-ahead, hourly forecasts of solar irradiance observations. Our experiments show that the adaptation of a DLN performs just as well or even better than an unconstrained approach. Further comparison of the adapted DLN against a scalable monotonic neural network shows that our approach performs better. With this adaptation of DLNs, we intend to create more interest and crossover investigations in techniques of monotonic neural networks and probabilistic forecasting.
It is all Connected: A New Graph Formulation for Spatio-Temporal Forecasting
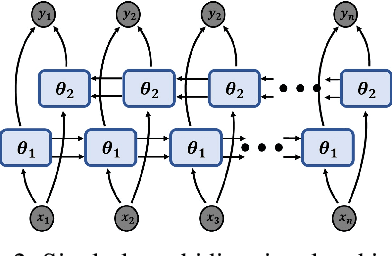
Mar 23, 2023With an ever-increasing number of sensors in modern society, spatio-temporal time series forecasting has become a de facto tool to make informed decisions about the future. Most spatio-temporal forecasting models typically comprise distinct components that learn spatial and temporal dependencies. A common methodology employs some Graph Neural Network (GNN) to capture relations between spatial locations, while another network, such as a recurrent neural network (RNN), learns temporal correlations. By representing every recorded sample as its own node in a graph, rather than all measurements for a particular location as a single node, temporal and spatial information is encoded in a similar manner. In this setting, GNNs can now directly learn both temporal and spatial dependencies, jointly, while also alleviating the need for additional temporal networks. Furthermore, the framework does not require aligned measurements along the temporal dimension, meaning that it also naturally facilitates irregular time series, different sampling frequencies or missing data, without the need for data imputation. To evaluate the proposed methodology, we consider wind speed forecasting as a case study, where our proposed framework outperformed other spatio-temporal models using GNNs with either Transformer or LSTM networks as temporal update functions.
Spatio-Temporal Wind Speed Forecasting using Graph Networks and Novel Transformer Architectures
Aug 29, 2022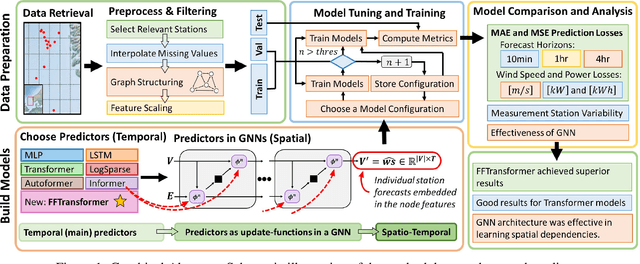
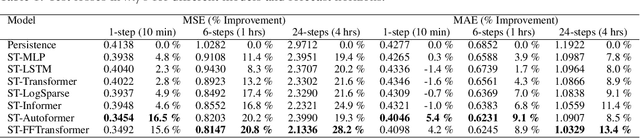
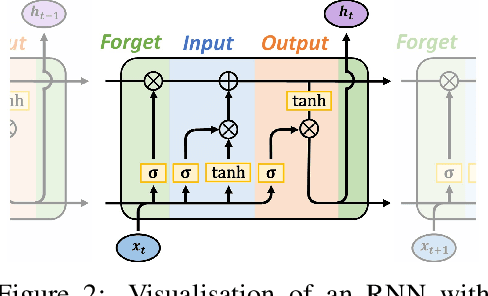
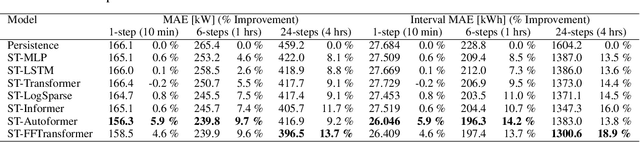
To improve the security and reliability of wind energy production, short-term forecasting has become of utmost importance. This study focuses on multi-step spatio-temporal wind speed forecasting for the Norwegian continental shelf. A graph neural network (GNN) architecture was used to extract spatial dependencies, with different update functions to learn temporal correlations. These update functions were implemented using different neural network architectures. One such architecture, the Transformer, has become increasingly popular for sequence modelling in recent years. Various alterations of the original architecture have been proposed to better facilitate time-series forecasting, of which this study focused on the Informer, LogSparse Transformer and Autoformer. This is the first time the LogSparse Transformer and Autoformer have been applied to wind forecasting and the first time any of these or the Informer have been formulated in a spatio-temporal setting for wind forecasting. By comparing against spatio-temporal Long Short-Term Memory (LSTM) and Multi-Layer Perceptron (MLP) models, the study showed that the models using the altered Transformer architectures as update functions in GNNs were able to outperform these. Furthermore, we propose the Fast Fourier Transformer (FFTransformer), which is a novel Transformer architecture based on signal decomposition and consists of two separate streams that analyse trend and periodic components separately. The FFTransformer and Autoformer were found to achieve superior results for the 10-minute and 1-hour ahead forecasts, with the FFTransformer significantly outperforming all other models for the 4-hour ahead forecasts. Finally, by varying the degree of connectivity for the graph representations, the study explicitly demonstrates how all models were able to leverage spatial dependencies to improve local short-term wind speed forecasting.
Wind Park Power Prediction: Attention-Based Graph Networks and Deep Learning to Capture Wake Losses
Jan 10, 2022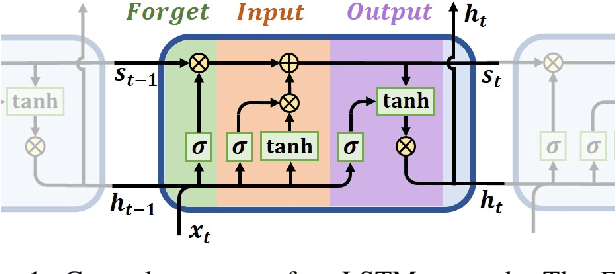
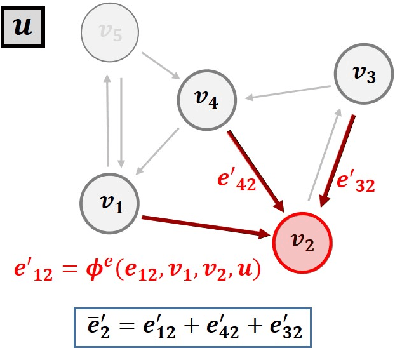
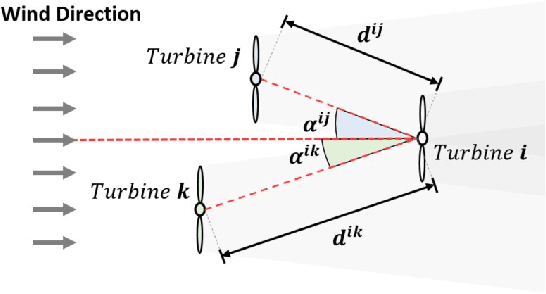
With the increased penetration of wind energy into the power grid, it has become increasingly important to be able to predict the expected power production for larger wind farms. Deep learning (DL) models can learn complex patterns in the data and have found wide success in predicting wake losses and expected power production. This paper proposes a modular framework for attention-based graph neural networks (GNN), where attention can be applied to any desired component of a graph block. The results show that the model significantly outperforms a multilayer perceptron (MLP) and a bidirectional LSTM (BLSTM) model, while delivering performance on-par with a vanilla GNN model. Moreover, we argue that the proposed graph attention architecture can easily adapt to different applications by offering flexibility into the desired attention operations to be used, which might depend on the specific application. Through analysis of the attention weights, it was showed that employing attention-based GNNs can provide insights into what the models learn. In particular, the attention networks seemed to realise turbine dependencies that aligned with some physical intuition about wake losses.