 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss and Reward Weighing for increased learning in Distributed Reinforcement Learning
Paper and Code
Apr 25, 2023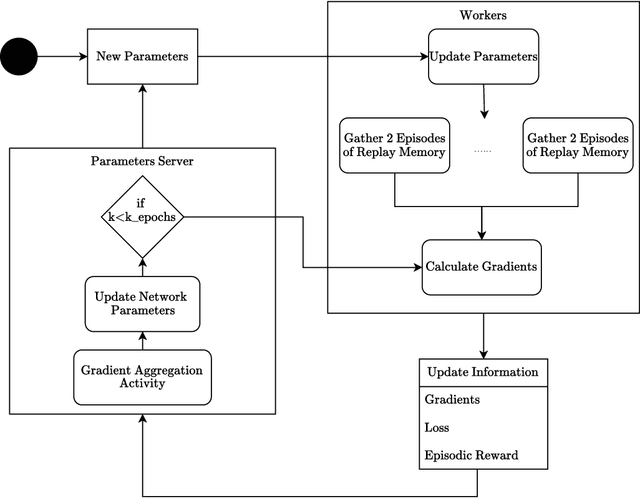



This paper introduces two learning schemes for distributed agents in Reinforcement Learning (RL) environments, namely Reward-Weighted (R-Weighted) and Loss-Weighted (L-Weighted) gradient merger. The R/L weighted methods replace standard practices for training multiple agents, such as summing or averaging the gradients. The core of our methods is to scale the gradient of each actor based on how high the reward (for R-Weighted) or the loss (for L-Weighted) is compared to the other actors. During training, each agent operates in differently initialized versions of the same environment, which gives different gradients from different actors. In essence, the R-Weights and L-Weights of each agent inform the other agents of its potential, which again reports which environment should be prioritized for learning. This approach of distributed learning is possible because environments that yield higher rewards, or low losses, have more critical information than environments that yield lower rewards or higher losses. We empirically demonstrate that the R-Weighted methods work superior to the state-of-the-art in multiple RL environments.