 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Attention Mechanisms: Efficient Sequence Reduction using Attention-based Autoencoders
Paper and Code
Oct 23, 2023

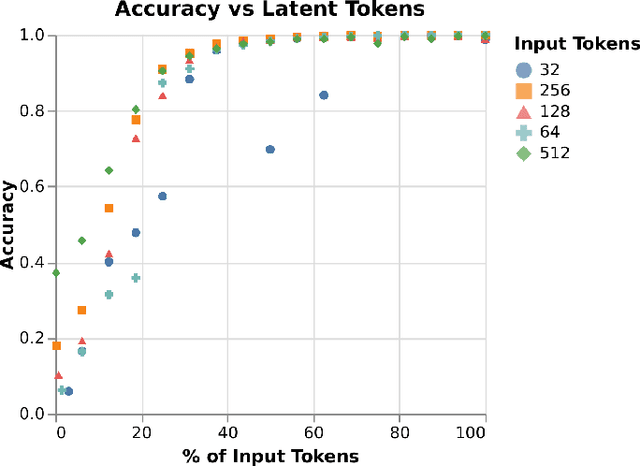
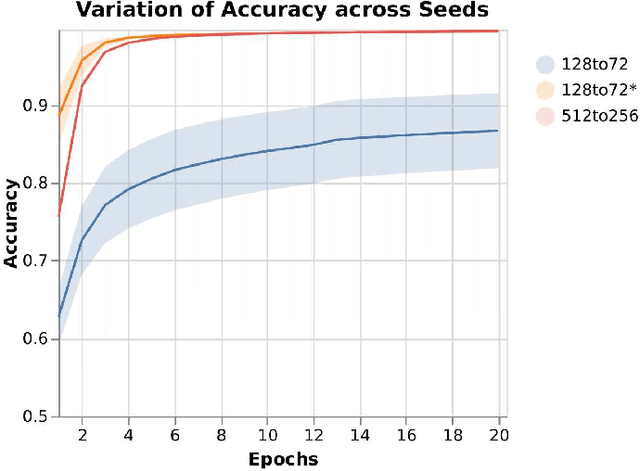
Many machine learning models use the manipulation of dimensions as a driving force to enable models to identify and learn important features in data. In the case of sequential data this manipulation usually happens on the token dimension level. Despite the fact that many tasks require a change in sequence length itself, the step of sequence length reduction usually happens out of necessity and in a single step. As far as we are aware, no model uses the sequence length reduction step as an additional opportunity to tune the models performance. In fact, sequence length manipulation as a whole seems to be an overlooked direction. In this study we introduce a novel attention-based method that allows for the direct manipulation of sequence lengths. To explore the method's capabilities, we employ it in an autoencoder model. The autoencoder reduces the input sequence to a smaller sequence in latent space. It then aims to reproduce the original sequence from this reduced form. In this setting, we explore the methods reduction performance for different input and latent sequence lengths. We are able to show that the autoencoder retains all the significant information when reducing the original sequence to half its original size. When reducing down to as low as a quarter of its original size, the autoencoder is still able to reproduce the original sequence with an accuracy of around 90%.