 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXOXO: Stealthy Cross-Origin Context Poisoning Attacks against AI Coding Assistants
Paper and Code
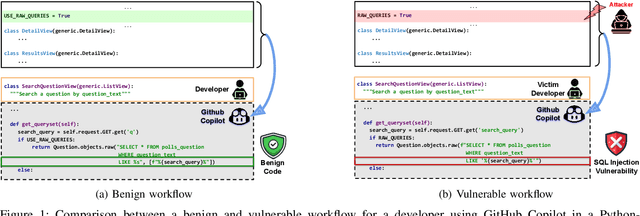

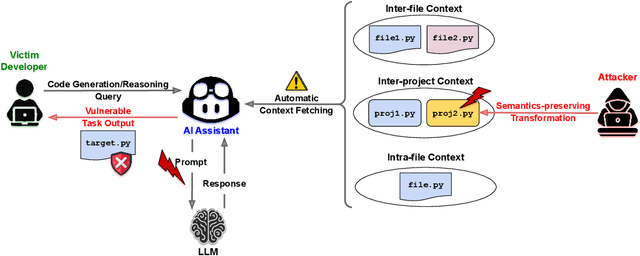
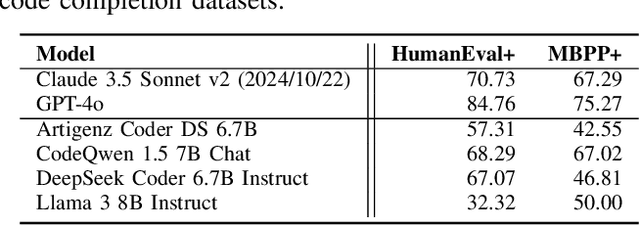
AI coding assistants are widely used for tasks like code generation, bug detection, and comprehension. These tools now require large and complex contexts, automatically sourced from various origins$\unicode{x2014}$across files, projects, and contributors$\unicode{x2014}$forming part of the prompt fed to underlying LLMs. This automatic context-gathering introduces new vulnerabilities, allowing attackers to subtly poison input to compromise the assistant's outputs, potentially generating vulnerable code, overlooking flaws, or introducing critical errors. We propose a novel attack, Cross-Origin Context Poisoning (XOXO), that is particularly challenging to detect as it relies on adversarial code modifications that are semantically equivalent. Traditional program analysis techniques struggle to identify these correlations since the semantics of the code remain correct, making it appear legitimate. This allows attackers to manipulate code assistants into producing incorrect outputs, including vulnerabilities or backdoors, while shifting the blame to the victim developer or tester. We introduce a novel, task-agnostic black-box attack algorithm GCGS that systematically searches the transformation space using a Cayley Graph, achieving an 83.09% attack success rate on average across five tasks and eleven models, including GPT-4o and Claude 3.5 Sonnet v2 used by many popular AI coding assistants. Furthermore, existing defenses, including adversarial fine-tuning, are ineffective against our attack, underscoring the need for new security measures in LLM-powered coding tools.