 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Is All You Need: Continuous Spatiotemporal Neural Representations of Earth Observation Data
Apr 09, 2026In this work, we present LIANet (Location Is All You Need Network), a coordinate-based neural representation that models multi-temporal spaceborne Earth observation (EO) data for a given region of interest as a continuous spatiotemporal neural field. Given only spatial and temporal coordinates, LIANet reconstructs the corresponding satellite imagery. Once pretrained, this neural representation can be adapted to various EO downstream tasks, such as semantic segmentation or pixel-wise regression, importantly, without requiring access to the original satellite data. LIANet intends to serve as a user-friendly alternative to Geospatial Foundation Models (GFMs) by eliminating the overhead of data access and preprocessing for end-users and enabling fine-tuning solely based on labels. We demonstrate the pretraining of LIANet across target areas of varying sizes and show that fine-tuning it for downstream tasks achieves competitive performance compared to training from scratch or using established GFMs. The source code and datasets are publicly available at https://github.com/mojganmadadi/LIANet/tree/v1.0.1.
Lossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025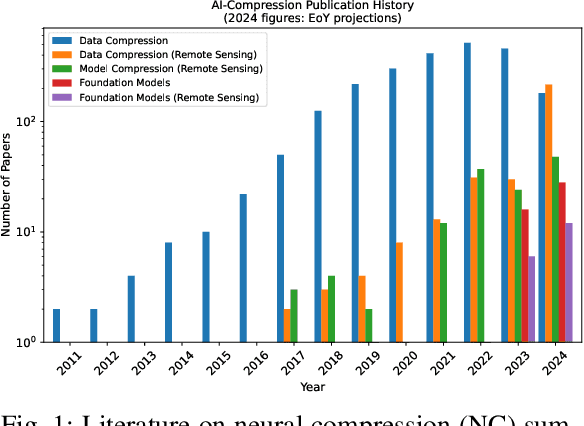
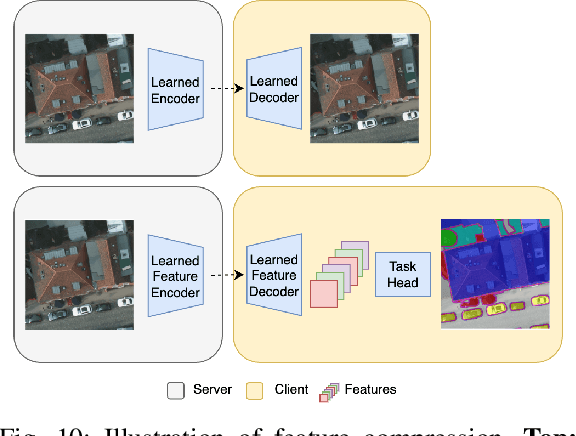
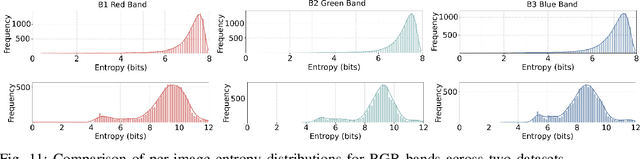
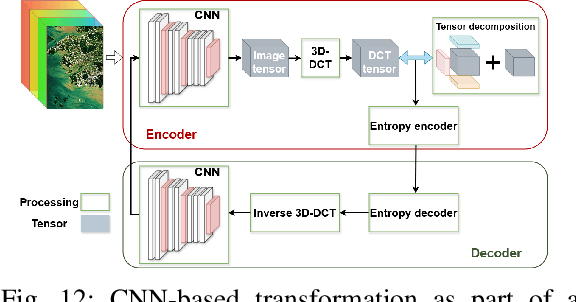
Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Multispectral to Hyperspectral using Pretrained Foundational model
Feb 26, 2025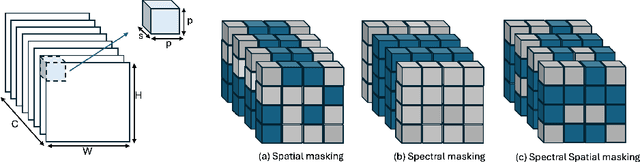
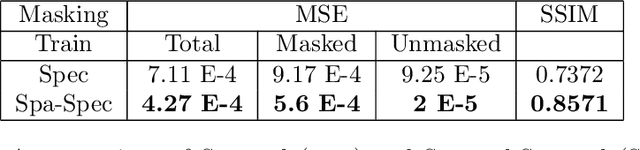
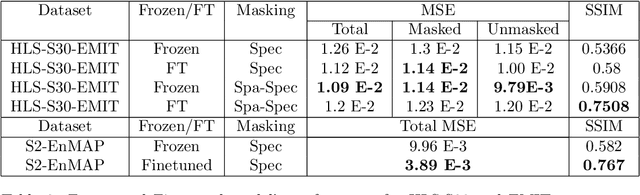
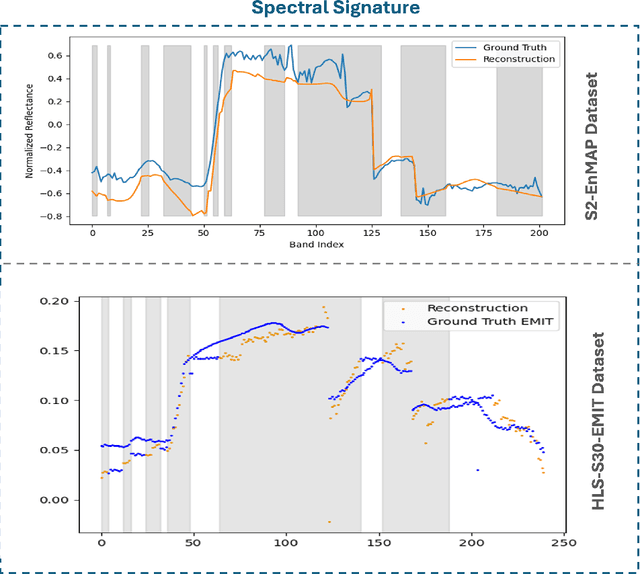
Hyperspectral imaging provides detailed spectral information, offering significant potential for monitoring greenhouse gases like CH4 and NO2. However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging delivers broader spatial and temporal coverage but lacks the spectral granularity required for precise GHG detection. To address these challenges, this study proposes Spectral and Spatial-Spectral transformer models that reconstruct hyperspectral data from multispectral inputs. The models in this paper are pretrained on EnMAP and EMIT datasets and fine-tuned on spatio-temporally aligned (Sentinel-2, EnMAP) and (HLS-S30, EMIT) image pairs respectively. Our model has the potential to enhance atmospheric monitoring by combining the strengths of hyperspectral and multispectral imaging systems.
SpectralEarth: Training Hyperspectral Foundation Models at Scale
Aug 15, 2024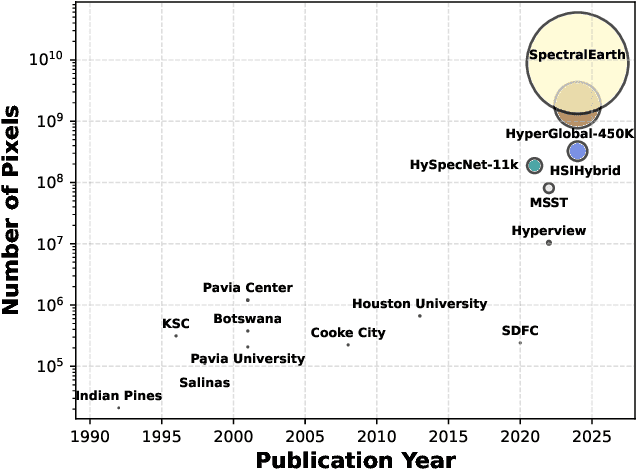
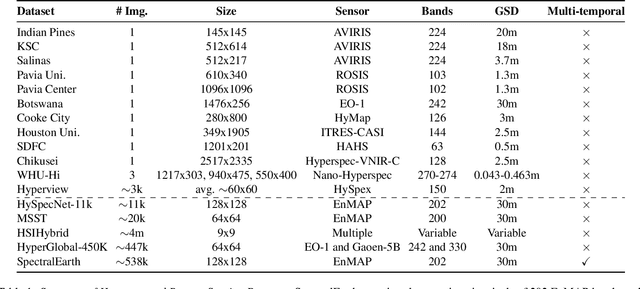

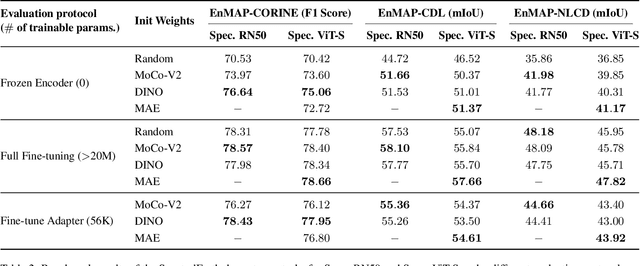
Foundation models have triggered a paradigm shift in computer vision and are increasingly being adopted in remote sensing, particularly for multispectral imagery. Yet, their potential in hyperspectral imaging (HSI) remains untapped due to the absence of comprehensive and globally representative hyperspectral datasets. To close this gap, we introduce SpectralEarth, a large-scale multi-temporal dataset designed to pretrain hyperspectral foundation models leveraging data from the Environmental Mapping and Analysis Program (EnMAP). SpectralEarth comprises 538,974 image patches covering 415,153 unique locations from more than 11,636 globally distributed EnMAP scenes spanning two years of archive. Additionally, 17.5% of these locations include multiple timestamps, enabling multi-temporal HSI analysis. Utilizing state-of-the-art self-supervised learning (SSL) algorithms, we pretrain a series of foundation models on SpectralEarth. We integrate a spectral adapter into classical vision backbones to accommodate the unique characteristics of HSI. In tandem, we construct four downstream datasets for land-cover and crop-type mapping, providing benchmarks for model evaluation. Experimental results support the versatility of our models, showcasing their generalizability across different tasks and sensors. We also highlight computational efficiency during model fine-tuning. The dataset, models, and source code will be made publicly available.
Multi-Label Guided Soft Contrastive Learning for Efficient Earth Observation Pretraining
May 30, 2024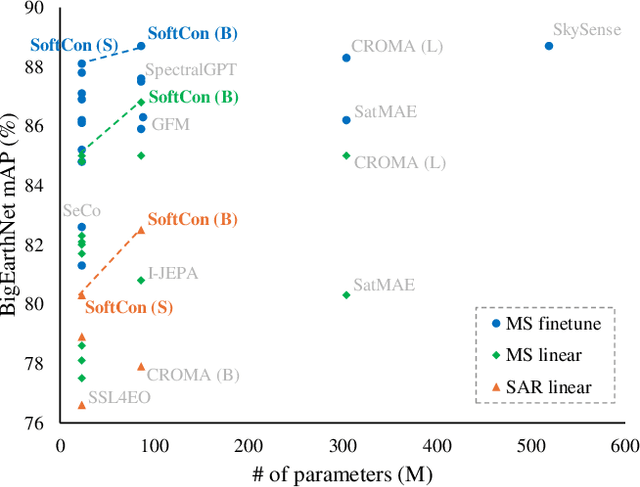
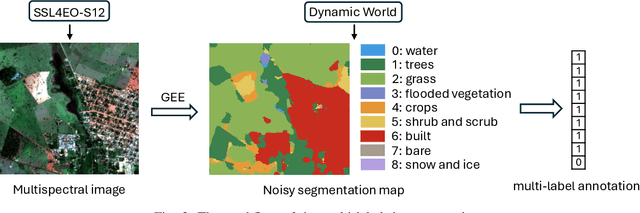
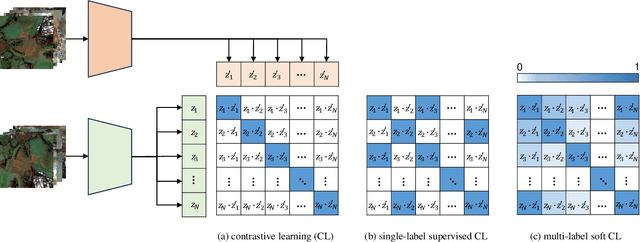
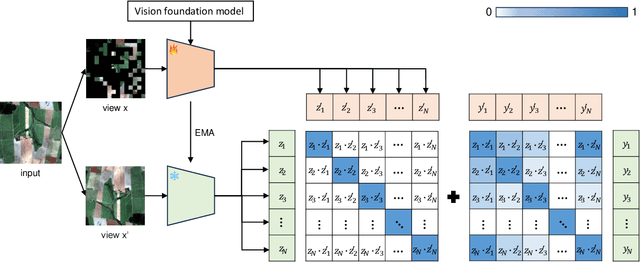
Self-supervised pretraining on large-scale satellite data has raised great interest in building Earth observation (EO) foundation models. However, many important resources beyond pure satellite imagery, such as land-cover-land-use products that provide free global semantic information, as well as vision foundation models that hold strong knowledge of the natural world, tend to be overlooked. In this work, we show these free additional resources not only help resolve common contrastive learning bottlenecks, but also significantly boost the efficiency and effectiveness of EO pretraining. Specifically, we first propose soft contrastive learning that optimizes cross-scene soft similarity based on land-cover-generated multi-label supervision, naturally solving the issue of multiple positive samples and too strict positive matching in complex scenes. Second, we explore cross-domain continual pretraining for both multispectral and SAR imagery, building efficient EO foundation models from strongest vision models such as DINOv2. Integrating simple weight-initialization and Siamese masking strategies into our soft contrastive learning framework, we demonstrate impressive continual pretraining performance even when the input channels and modalities are not aligned. Without prohibitive training, we produce multispectral and SAR foundation models that achieve significantly better results in 9 out of 10 downstream tasks than most existing SOTA models. For example, our ResNet50/ViT-S achieve 84.8/85.0 linear probing mAP scores on BigEarthNet-10\% which are better than most existing ViT-L models; under the same setting, our ViT-B sets a new record of 86.8 in multispectral, and 82.5 in SAR, the latter even better than many multispectral models. Dataset and models are available at https://github.com/zhu-xlab/softcon.
AutoLCZ: Towards Automatized Local Climate Zone Mapping from Rule-Based Remote Sensing
May 22, 2024



Local climate zones (LCZs) established a standard classification system to categorize the landscape universe for improved urban climate studies. Existing LCZ mapping is guided by human interaction with geographic information systems (GIS) or modelled from remote sensing (RS) data. GIS-based methods do not scale to large areas. However, RS-based methods leverage machine learning techniques to automatize LCZ classification from RS. Yet, RS-based methods require huge amounts of manual labels for training. We propose a novel LCZ mapping framework, termed AutoLCZ, to extract the LCZ classification features from high-resolution RS modalities. We study the definition of numerical rules designed to mimic the LCZ definitions. Those rules model geometric and surface cover properties from LiDAR data. Correspondingly, we enable LCZ classification from RS data in a GIS-based scheme. The proposed AutoLCZ method has potential to reduce the human labor to acquire accurate metadata. At the same time, AutoLCZ sheds light on the physical interpretability of RS-based methods. In a proof-of-concept for New York City (NYC) we leverage airborne LiDAR surveys to model 4 LCZ features to distinguish 10 LCZ types. The results indicate the potential of AutoLCZ as promising avenue for large-scale LCZ mapping from RS data.
Climatic & Anthropogenic Hazards to the Nasca World Heritage: Application of Remote Sensing, AI, and Flood Modelling
May 20, 2024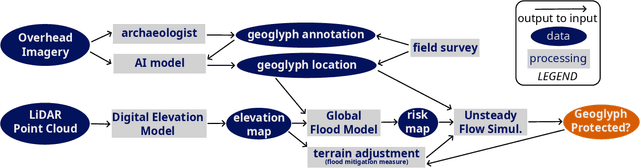
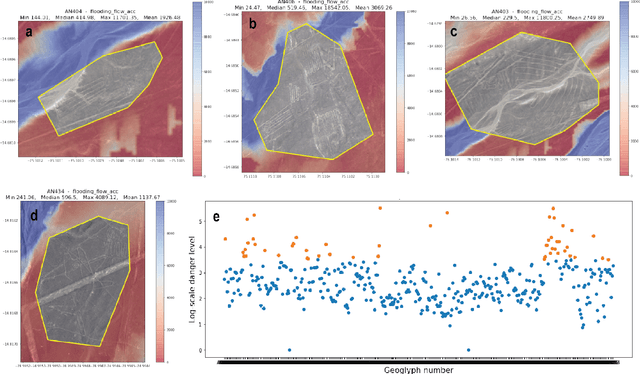
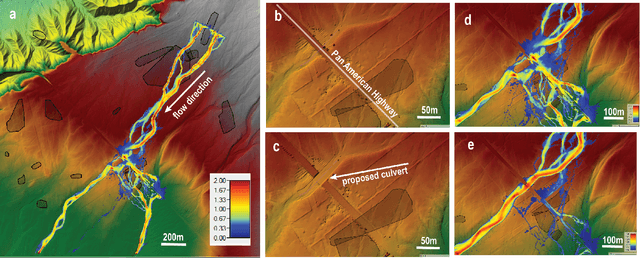
Preservation of the Nasca geoglyphs at the UNESCO World Heritage Site in Peru is urgent as natural and human impact accelerates. More frequent weather extremes such as flashfloods threaten Nasca artifacts. We demonstrate that runoff models based on (sub-)meter scale, LiDAR-derived digital elevation data can highlight AI-detected geoglyphs that are in danger of erosion. We recommend measures of mitigation to protect the famous "lizard", "tree", and "hand" geoglyphs located close by, or even cut by the Pan-American Highway.
AIO2: Online Correction of Object Labels for Deep Learning with Incomplete Annotation in Remote Sensing Image Segmentation
Mar 03, 2024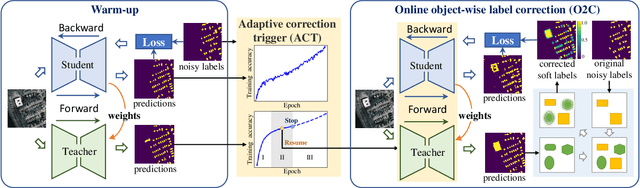
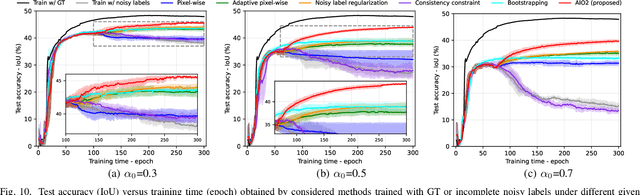

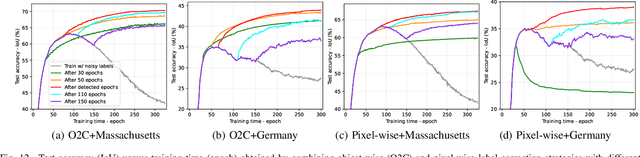
While the volume of remote sensing data is increasing daily, deep learning in Earth Observation faces lack of accurate annotations for supervised optimization. Crowdsourcing projects such as OpenStreetMap distribute the annotation load to their community. However, such annotation inevitably generates noise due to insufficient control of the label quality, lack of annotators, frequent changes of the Earth's surface as a result of natural disasters and urban development, among many other factors. We present Adaptively trIggered Online Object-wise correction (AIO2) to address annotation noise induced by incomplete label sets. AIO2 features an Adaptive Correction Trigger (ACT) module that avoids label correction when the model training under- or overfits, and an Online Object-wise Correction (O2C) methodology that employs spatial information for automated label modification. AIO2 utilizes a mean teacher model to enhance training robustness with noisy labels to both stabilize the training accuracy curve for fitting in ACT and provide pseudo labels for correction in O2C. Moreover, O2C is implemented online without the need to store updated labels every training epoch. We validate our approach on two building footprint segmentation datasets with different spatial resolutions. Experimental results with varying degrees of building label noise demonstrate the robustness of AIO2. Source code will be available at https://github.com/zhu-xlab/AIO2.git.
Feature Guided Masked Autoencoder for Self-supervised Learning in Remote Sensing
Oct 28, 2023
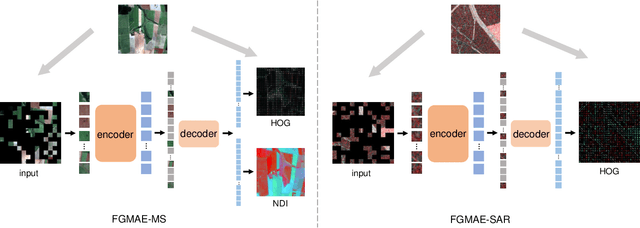


Self-supervised learning guided by masked image modelling, such as Masked AutoEncoder (MAE), has attracted wide attention for pretraining vision transformers in remote sensing. However, MAE tends to excessively focus on pixel details, thereby limiting the model's capacity for semantic understanding, in particular for noisy SAR images. In this paper, we explore spectral and spatial remote sensing image features as improved MAE-reconstruction targets. We first conduct a study on reconstructing various image features, all performing comparably well or better than raw pixels. Based on such observations, we propose Feature Guided Masked Autoencoder (FG-MAE): reconstructing a combination of Histograms of Oriented Graidents (HOG) and Normalized Difference Indices (NDI) for multispectral images, and reconstructing HOG for SAR images. Experimental results on three downstream tasks illustrate the effectiveness of FG-MAE with a particular boost for SAR imagery. Furthermore, we demonstrate the well-inherited scalability of FG-MAE and release a first series of pretrained vision transformers for medium resolution SAR and multispectral images.
DeCUR: decoupling common & unique representations for multimodal self-supervision
Sep 15, 2023The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.