 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Evaluation of Copula-based Survival Metrics: Beyond the Independent Censoring Assumption
Feb 26, 2025



Conventional survival metrics, such as Harrell's concordance index and the Brier Score, rely on the independent censoring assumption for valid inference in the presence of right-censored data. However, when instances are censored for reasons related to the event of interest, this assumption no longer holds, as this kind of dependent censoring biases the marginal survival estimates of popular nonparametric estimators. In this paper, we propose three copula-based metrics to evaluate survival models in the presence of dependent censoring, and design a framework to create realistic, semi-synthetic datasets with dependent censoring to facilitate the evaluation of the metrics. Our empirical analyses in synthetic and semi-synthetic datasets show that our metrics can give error estimates that are closer to the true error, mainly in terms of predictive accuracy.
Toward Conditional Distribution Calibration in Survival Prediction
Oct 27, 2024Survival prediction often involves estimating the time-to-event distribution from censored datasets. Previous approaches have focused on enhancing discrimination and marginal calibration. In this paper, we highlight the significance of conditional calibration for real-world applications -- especially its role in individual decision-making. We propose a method based on conformal prediction that uses the model's predicted individual survival probability at that instance's observed time. This method effectively improves the model's marginal and conditional calibration, without compromising discrimination. We provide asymptotic theoretical guarantees for both marginal and conditional calibration and test it extensively across 15 diverse real-world datasets, demonstrating the method's practical effectiveness and versatility in various settings.
MENSA: A Multi-Event Network for Survival Analysis under Informative Censoring
Sep 10, 2024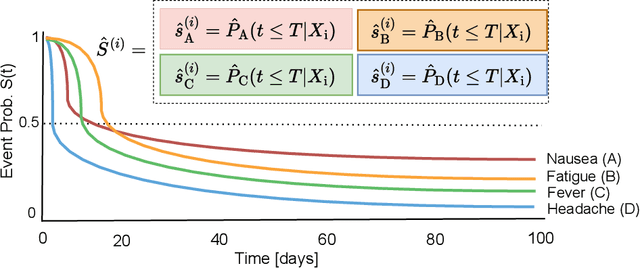

Given an instance, a multi-event survival model predicts the time until that instance experiences each of several different events. These events are not mutually exclusive and there are often statistical dependencies between them. There are relatively few multi-event survival results, most focusing on producing a simple risk score, rather than the time-to-event itself. To overcome these issues, we introduce MENSA, a novel, deep learning approach for multi-event survival analysis that can jointly learn representations of the input covariates and the dependence structure between events. As a practical motivation for multi-event survival analysis, we consider the problem of predicting the time until a patient with amyotrophic lateral sclerosis (ALS) loses various physical functions, i.e., the ability to speak, swallow, write, or walk. When estimating when a patient is no longer able to swallow, our approach achieves an L1-Margin loss of 278.8 days, compared to 355.2 days when modeling each event separately. In addition, we also evaluate our approach in single-event and competing risk scenarios by modeling the censoring and event distributions as equal contributing factors in the optimization process, and show that our approach performs well across multiple benchmark datasets. The source code is available at: https://github.com/thecml/mensa
Conformalized Survival Distributions: A Generic Post-Process to Increase Calibration
May 12, 2024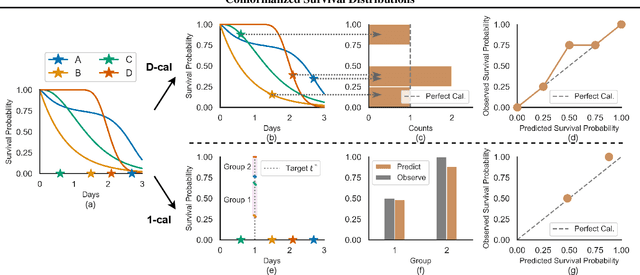
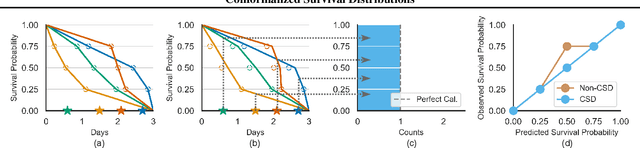

Discrimination and calibration represent two important properties of survival analysis, with the former assessing the model's ability to accurately rank subjects and the latter evaluating the alignment of predicted outcomes with actual events. With their distinct nature, it is hard for survival models to simultaneously optimize both of them especially as many previous results found improving calibration tends to diminish discrimination performance. This paper introduces a novel approach utilizing conformal regression that can improve a model's calibration without degrading discrimination. We provide theoretical guarantees for the above claim, and rigorously validate the efficiency of our approach across 11 real-world datasets, showcasing its practical applicability and robustness in diverse scenarios.
iHAS: Instance-wise Hierarchical Architecture Search for Deep Learning Recommendation Models
Sep 14, 2023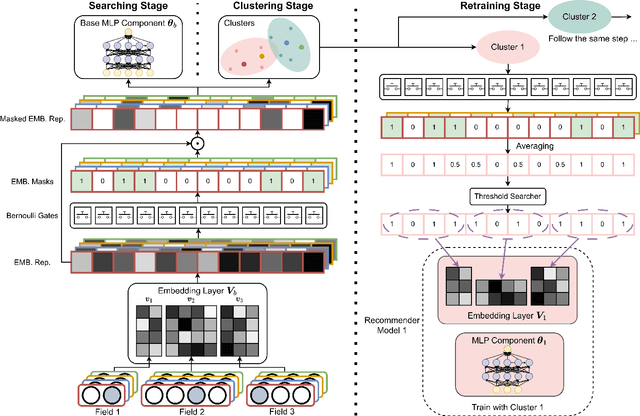
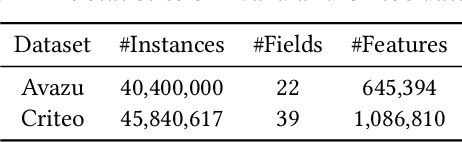
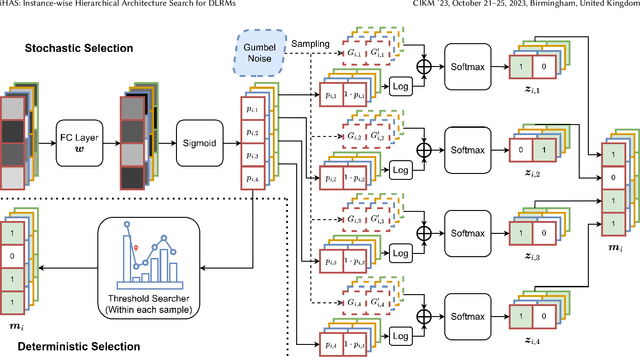
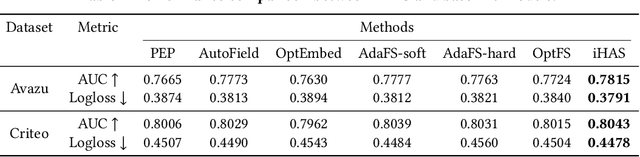
Current recommender systems employ large-sized embedding tables with uniform dimensions for all features, leading to overfitting, high computational cost, and suboptimal generalizing performance. Many techniques aim to solve this issue by feature selection or embedding dimension search. However, these techniques typically select a fixed subset of features or embedding dimensions for all instances and feed all instances into one recommender model without considering heterogeneity between items or users. This paper proposes a novel instance-wise Hierarchical Architecture Search framework, iHAS, which automates neural architecture search at the instance level. Specifically, iHAS incorporates three stages: searching, clustering, and retraining. The searching stage identifies optimal instance-wise embedding dimensions across different field features via carefully designed Bernoulli gates with stochastic selection and regularizers. After obtaining these dimensions, the clustering stage divides samples into distinct groups via a deterministic selection approach of Bernoulli gates. The retraining stage then constructs different recommender models, each one designed with optimal dimensions for the corresponding group. We conduct extensive experiments to evaluate the proposed iHAS on two public benchmark datasets from a real-world recommender system. The experimental results demonstrate the effectiveness of iHAS and its outstanding transferability to widely-used deep recommendation models.
ConKI: Contrastive Knowledge Injection for Multimodal Sentiment Analysis
Jun 27, 2023



Multimodal Sentiment Analysis leverages multimodal signals to detect the sentiment of a speaker. Previous approaches concentrate on performing multimodal fusion and representation learning based on general knowledge obtained from pretrained models, which neglects the effect of domain-specific knowledge. In this paper, we propose Contrastive Knowledge Injection (ConKI) for multimodal sentiment analysis, where specific-knowledge representations for each modality can be learned together with general knowledge representations via knowledge injection based on an adapter architecture. In addition, ConKI uses a hierarchical contrastive learning procedure performed between knowledge types within every single modality, across modalities within each sample, and across samples to facilitate the effective learning of the proposed representations, hence improving multimodal sentiment predictions. The experiments on three popular multimodal sentiment analysis benchmarks show that ConKI outperforms all prior methods on a variety of performance metrics.
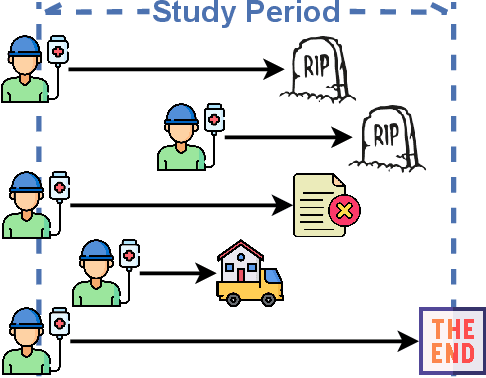
An Effective Meaningful Way to Evaluate Survival Models
Jun 01, 2023One straightforward metric to evaluate a survival prediction model is based on the Mean Absolute Error (MAE) -- the average of the absolute difference between the time predicted by the model and the true event time, over all subjects. Unfortunately, this is challenging because, in practice, the test set includes (right) censored individuals, meaning we do not know when a censored individual actually experienced the event. In this paper, we explore various metrics to estimate MAE for survival datasets that include (many) censored individuals. Moreover, we introduce a novel and effective approach for generating realistic semi-synthetic survival datasets to facilitate the evaluation of metrics. Our findings, based on the analysis of the semi-synthetic datasets, reveal that our proposed metric (MAE using pseudo-observations) is able to rank models accurately based on their performance, and often closely matches the true MAE -- in particular, is better than several alternative methods.