 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Semi-Supervised Learning
Dec 17, 2025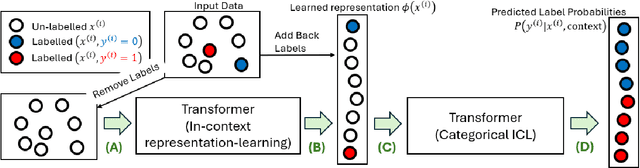

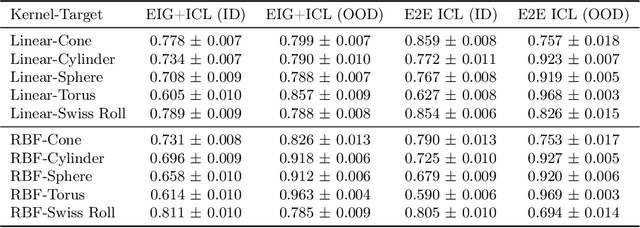
There has been significant recent interest in understanding the capacity of Transformers for in-context learning (ICL), yet most theory focuses on supervised settings with explicitly labeled pairs. In practice, Transformers often perform well even when labels are sparse or absent, suggesting crucial structure within unlabeled contextual demonstrations. We introduce and study in-context semi-supervised learning (IC-SSL), where a small set of labeled examples is accompanied by many unlabeled points, and show that Transformers can leverage the unlabeled context to learn a robust, context-dependent representation. This representation enables accurate predictions and markedly improves performance in low-label regimes, offering foundational insights into how Transformers exploit unlabeled context for representation learning within the ICL framework.
Transformer In-Context Learning for Categorical Data
May 27, 2024



Recent research has sought to understand Transformers through the lens of in-context learning with functional data. We extend that line of work with the goal of moving closer to language models, considering categorical outcomes, nonlinear underlying models, and nonlinear attention. The contextual data are of the form $\textsf{C}=(x_1,c_1,\dots,x_N,c_{N})$ where each $c_i\in\{0,\dots,C-1\}$ is drawn from a categorical distribution that depends on covariates $x_i\in\mathbb{R}^d$. Contextual outcomes in the $m$th set of contextual data, $\textsf{C}_m$, are modeled in terms of latent function $f_m(x)\in\textsf{F}$, where $\textsf{F}$ is a functional class with $(C-1)$-dimensional vector output. The probability of observing class $c\in\{0,\dots,C-1\}$ is modeled in terms of the output components of $f_m(x)$ via the softmax. The Transformer parameters may be trained with $M$ contextual examples, $\{\textsf{C}_m\}_{m=1,M}$, and the trained model is then applied to new contextual data $\textsf{C}_{M+1}$ for new $f_{M+1}(x)\in\textsf{F}$. The goal is for the Transformer to constitute the probability of each category $c\in\{0,\dots,C-1\}$ for a new query $x_{N_{M+1}+1}$. We assume each component of $f_m(x)$ resides in a reproducing kernel Hilbert space (RKHS), specifying $\textsf{F}$. Analysis and an extensive set of experiments suggest that on its forward pass the Transformer (with attention defined by the RKHS kernel) implements a form of gradient descent of the underlying function, connected to the latent vector function associated with the softmax. We present what is believed to be the first real-world demonstration of this few-shot-learning methodology, using the ImageNet dataset.