 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoPrompt: Information-Theoretic Soft Prompt Tuning for Natural Language Understanding
Paper and Code
Jun 08, 2023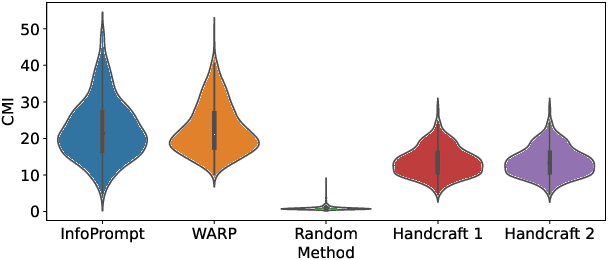


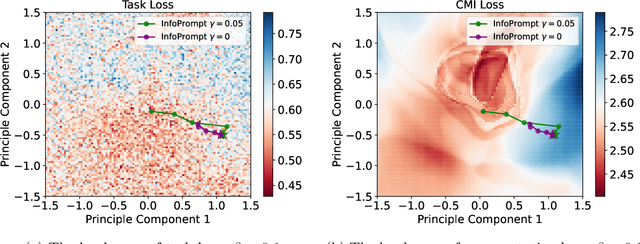
Soft prompt tuning achieves superior performances across a wide range of few-shot tasks. However, the performances of prompt tuning can be highly sensitive to the initialization of the prompts. We also empirically observe that conventional prompt tuning methods cannot encode and learn sufficient task-relevant information from prompt tokens. In this work, we develop an information-theoretic framework that formulates soft prompt tuning as maximizing mutual information between prompts and other model parameters (or encoded representations). This novel view helps us to develop a more efficient, accurate and robust soft prompt tuning method InfoPrompt. With this framework, we develop two novel mutual information based loss functions, to (i) discover proper prompt initialization for the downstream tasks and learn sufficient task-relevant information from prompt tokens and (ii) encourage the output representation from the pretrained language model to be more aware of the task-relevant information captured in the learnt prompt. Extensive experiments validate that InfoPrompt can significantly accelerate the convergence of the prompt tuning and outperform traditional prompt tuning methods. Finally, we provide a formal theoretical result for showing to show that gradient descent type algorithm can be used to train our mutual information loss.