 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiddenCut: Simple Data Augmentation for Natural Language Understanding with Better Generalization
Paper and Code
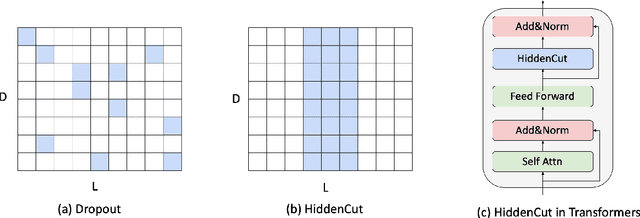
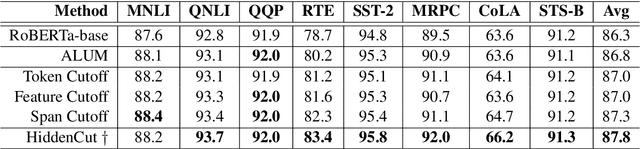

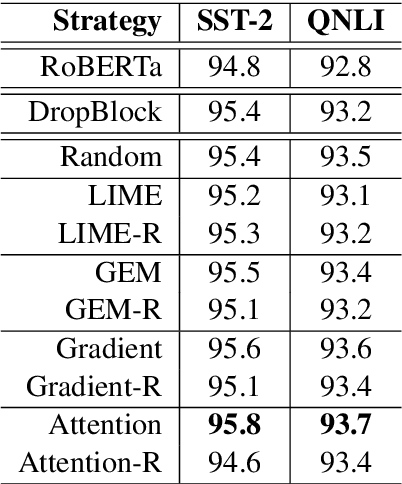
Fine-tuning large pre-trained models with task-specific data has achieved great success in NLP. However, it has been demonstrated that the majority of information within the self-attention networks is redundant and not utilized effectively during the fine-tuning stage. This leads to inferior results when generalizing the obtained models to out-of-domain distributions. To this end, we propose a simple yet effective data augmentation technique, HiddenCut, to better regularize the model and encourage it to learn more generalizable features. Specifically, contiguous spans within the hidden space are dynamically and strategically dropped during training. Experiments show that our HiddenCut method outperforms the state-of-the-art augmentation methods on the GLUE benchmark, and consistently exhibits superior generalization performances on out-of-distribution and challenging counterexamples. We have publicly released our code at https://github.com/GT-SALT/HiddenCut.