 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee More, Store Less: Memory-Efficient Resolution for Video Moment Retrieval
Jan 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have improved image recognition and reasoning, but video-related tasks remain challenging due to memory constraints from dense frame processing. Existing Video Moment Retrieval (VMR) methodologies rely on sparse frame sampling, risking potential information loss, especially in lengthy videos. We propose SMORE (See MORE, store less), a framework that enhances memory efficiency while maintaining high information resolution. SMORE (1) uses query-guided captions to encode semantics aligned with user intent, (2) applies query-aware importance modulation to highlight relevant segments, and (3) adaptively compresses frames to preserve key content while reducing redundancy. This enables efficient video understanding without exceeding memory budgets. Experimental validation reveals that SMORE achieves state-of-the-art performance on QVHighlights, Charades-STA, and ActivityNet-Captions benchmarks.
GranAlign: Granularity-Aware Alignment Framework for Zero-Shot Video Moment Retrieval
Jan 02, 2026Zero-shot video moment retrieval (ZVMR) is the task of localizing a temporal moment within an untrimmed video using a natural language query without relying on task-specific training data. The primary challenge in this setting lies in the mismatch in semantic granularity between textual queries and visual content. Previous studies in ZVMR have attempted to achieve alignment by leveraging high-quality pre-trained knowledge that represents video and language in a joint space. However, these approaches failed to balance the semantic granularity between the pre-trained knowledge provided by each modality for a given scene. As a result, despite the high quality of each modality's representations, the mismatch in granularity led to inaccurate retrieval. In this paper, we propose a training-free framework, called Granularity-Aware Alignment (GranAlign), that bridges this gap between coarse and fine semantic representations. Our approach introduces two complementary techniques: granularity-based query rewriting to generate varied semantic granularities, and query-aware caption generation to embed query intent into video content. By pairing multi-level queries with both query-agnostic and query-aware captions, we effectively resolve semantic mismatches. As a result, our method sets a new state-of-the-art across all three major benchmarks (QVHighlights, Charades-STA, ActivityNet-Captions), with a notable 3.23% mAP@avg improvement on the challenging QVHighlights dataset.
Point to Span: Zero-Shot Moment Retrieval for Navigating Unseen Hour-Long Videos
Dec 11, 2025



Zero-shot Long Video Moment Retrieval (ZLVMR) is the task of identifying temporal segments in hour-long videos using a natural language query without task-specific training. The core technical challenge of LVMR stems from the computational infeasibility of processing entire lengthy videos in a single pass. This limitation has established a 'Search-then-Refine' approach, where candidates are rapidly narrowed down, and only those portions are analyzed, as the dominant paradigm for LVMR. However, existing approaches to this paradigm face severe limitations. Conventional supervised learning suffers from limited scalability and poor generalization, despite substantial resource consumption. Yet, existing zero-shot methods also fail, facing a dual challenge: (1) their heuristic strategies cause a 'search' phase candidate explosion, and (2) the 'refine' phase, which is vulnerable to semantic discrepancy, requires high-cost VLMs for verification, incurring significant computational overhead. We propose \textbf{P}oint-\textbf{to}-\textbf{S}pan (P2S), a novel training-free framework to overcome this challenge of inefficient 'search' and costly 'refine' phases. P2S overcomes these challenges with two key innovations: an 'Adaptive Span Generator' to prevent the search phase candidate explosion, and 'Query Decomposition' to refine candidates without relying on high-cost VLM verification. To our knowledge, P2S is the first zero-shot framework capable of temporal grounding in hour-long videos, outperforming supervised state-of-the-art methods by a significant margin (e.g., +3.7\% on R5@0.1 on MAD).
Visualizing the loss landscape of Self-supervised Vision Transformer
May 28, 2024

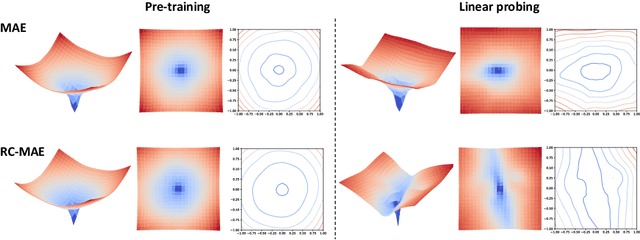
The Masked autoencoder (MAE) has drawn attention as a representative self-supervised approach for masked image modeling with vision transformers. However, even though MAE shows better generalization capability than fully supervised training from scratch, the reason why has not been explored. In another line of work, the Reconstruction Consistent Masked Auto Encoder (RC-MAE), has been proposed which adopts a self-distillation scheme in the form of an exponential moving average (EMA) teacher into MAE, and it has been shown that the EMA-teacher performs a conditional gradient correction during optimization. To further investigate the reason for better generalization of the self-supervised ViT when trained by MAE (MAE-ViT) and the effect of the gradient correction of RC-MAE from the perspective of optimization, we visualize the loss landscapes of the self-supervised vision transformer by both MAE and RC-MAE and compare them with the supervised ViT (Sup-ViT). Unlike previous loss landscape visualizations of neural networks based on classification task loss, we visualize the loss landscape of ViT by computing pre-training task loss. Through the lens of loss landscapes, we find two interesting observations: (1) MAE-ViT has a smoother and wider overall loss curvature than Sup-ViT. (2) The EMA-teacher allows MAE to widen the region of convexity in both pretraining and linear probing, leading to quicker convergence. To the best of our knowledge, this work is the first to investigate the self-supervised ViT through the lens of the loss landscape.
Exploring The Role of Mean Teachers in Self-supervised Masked Auto-Encoders
Oct 05, 2022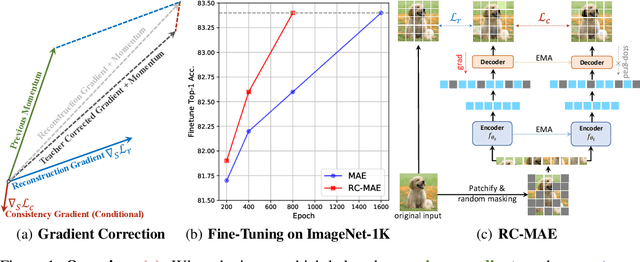
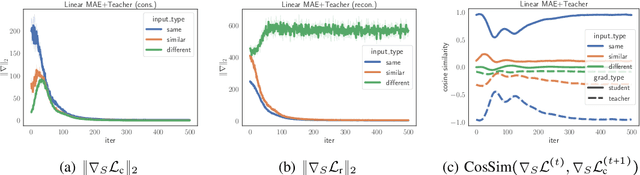

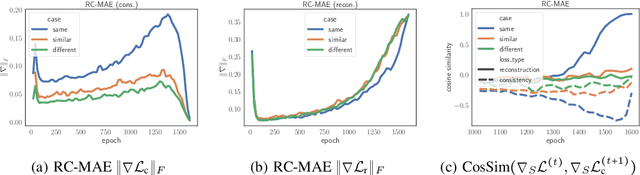
Masked image modeling (MIM) has become a popular strategy for self-supervised learning~(SSL) of visual representations with Vision Transformers. A representative MIM model, the masked auto-encoder (MAE), randomly masks a subset of image patches and reconstructs the masked patches given the unmasked patches. Concurrently, many recent works in self-supervised learning utilize the student/teacher paradigm which provides the student with an additional target based on the output of a teacher composed of an exponential moving average (EMA) of previous students. Although common, relatively little is known about the dynamics of the interaction between the student and teacher. Through analysis on a simple linear model, we find that the teacher conditionally removes previous gradient directions based on feature similarities which effectively acts as a conditional momentum regularizer. From this analysis, we present a simple SSL method, the Reconstruction-Consistent Masked Auto-Encoder (RC-MAE) by adding an EMA teacher to MAE. We find that RC-MAE converges faster and requires less memory usage than state-of-the-art self-distillation methods during pre-training, which may provide a way to enhance the practicality of prohibitively expensive self-supervised learning of Vision Transformer models. Additionally, we show that RC-MAE achieves more robustness and better performance compared to MAE on downstream tasks such as ImageNet-1K classification, object detection, and instance segmentation.
MPViT: Multi-Path Vision Transformer for Dense Prediction
Dec 27, 2021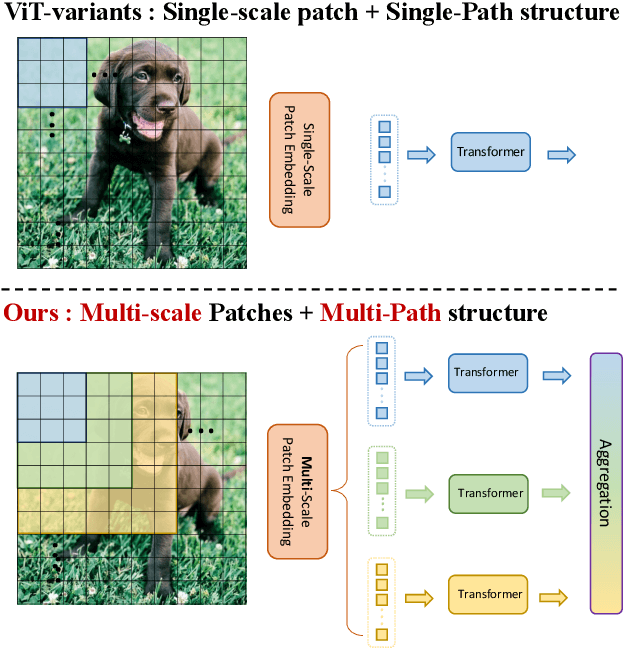



Dense computer vision tasks such as object detection and segmentation require effective multi-scale feature representation for detecting or classifying objects or regions with varying sizes. While Convolutional Neural Networks (CNNs) have been the dominant architectures for such tasks, recently introduced Vision Transformers (ViTs) aim to replace them as a backbone. Similar to CNNs, ViTs build a simple multi-stage structure (i.e., fine-to-coarse) for multi-scale representation with single-scale patches. In this work, with a different perspective from existing Transformers, we explore multi-scale patch embedding and multi-path structure, constructing the Multi-Path Vision Transformer (MPViT). MPViT embeds features of the same size~(i.e., sequence length) with patches of different scales simultaneously by using overlapping convolutional patch embedding. Tokens of different scales are then independently fed into the Transformer encoders via multiple paths and the resulting features are aggregated, enabling both fine and coarse feature representations at the same feature level. Thanks to the diverse, multi-scale feature representations, our MPViTs scaling from tiny~(5M) to base~(73M) consistently achieve superior performance over state-of-the-art Vision Transformers on ImageNet classification, object detection, instance segmentation, and semantic segmentation. These extensive results demonstrate that MPViT can serve as a versatile backbone network for various vision tasks. Code will be made publicly available at \url{https://git.io/MPViT}.