Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-FEGAN: Face Editing Generative Adversarial Network with User's Sketch and Color
Paper and Code


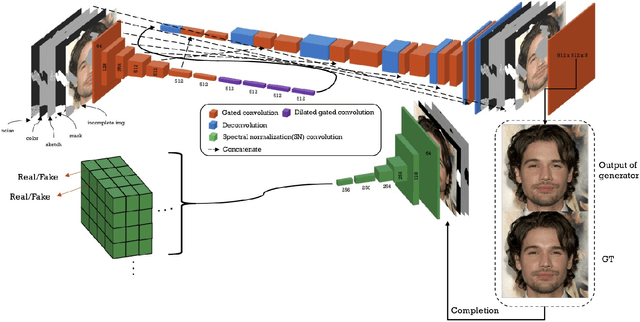

We present a novel image editing system that generates images as the user provides free-form mask, sketch and color as an input. Our system consist of a end-to-end trainable convolutional network. Contrary to the existing methods, our system wholly utilizes free-form user input with color and shape. This allows the system to respond to the user's sketch and color input, using it as a guideline to generate an image. In our particular work, we trained network with additional style loss which made it possible to generate realistic results, despite large portions of the image being removed. Our proposed network architecture SC-FEGAN is well suited to generate high quality synthetic image using intuitive user inputs.
View paper on