 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Discriminate Information for Online Action Detection: Analysis and Application
Sep 09, 2021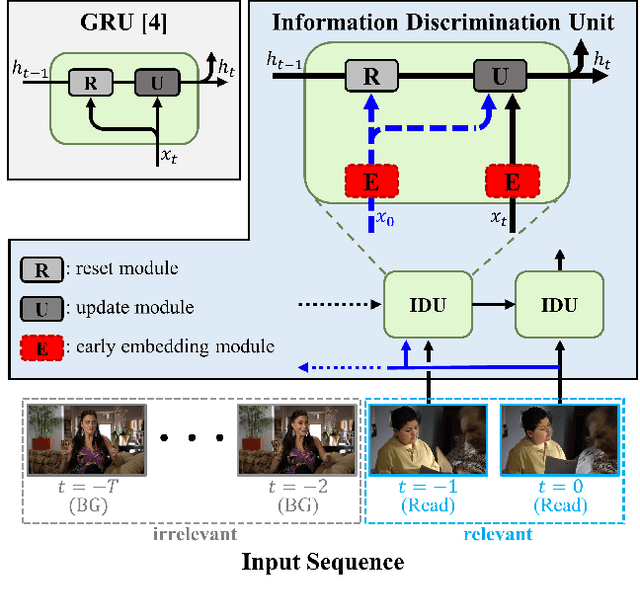
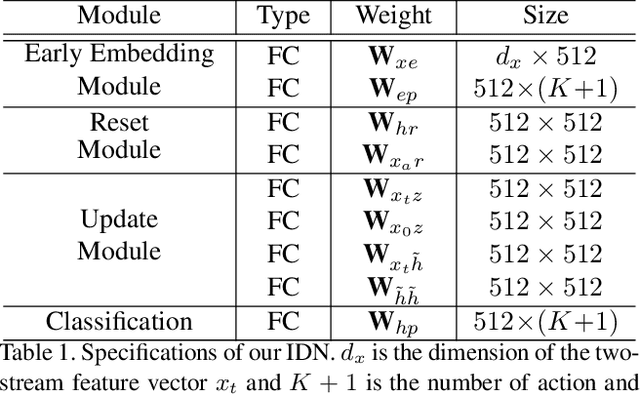
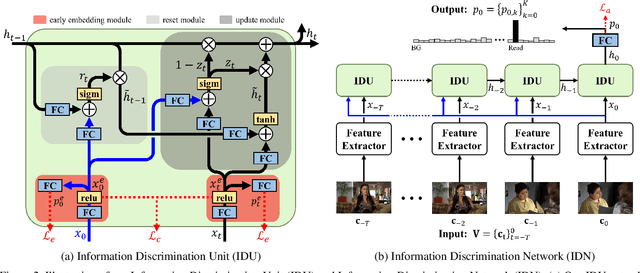
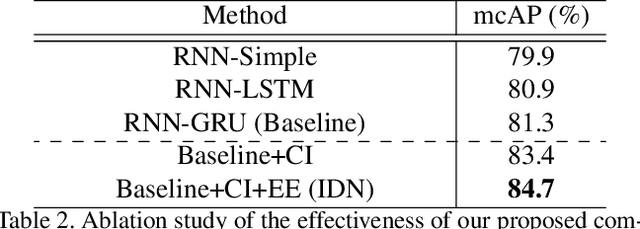
Online action detection, which aims to identify an ongoing action from a streaming video, is an important subject in real-world applications. For this task, previous methods use recurrent neural networks for modeling temporal relations in an input sequence. However, these methods overlook the fact that the input image sequence includes not only the action of interest but background and irrelevant actions. This would induce recurrent units to accumulate unnecessary information for encoding features on the action of interest. To overcome this problem, we propose a novel recurrent unit, named Information Discrimination Unit (IDU), which explicitly discriminates the information relevancy between an ongoing action and others to decide whether to accumulate the input information. This enables learning more discriminative representations for identifying an ongoing action. In this paper, we further present a new recurrent unit, called Information Integration Unit (IIU), for action anticipation. Our IIU exploits the outputs from IDU as pseudo action labels as well as RGB frames to learn enriched features of observed actions effectively. In experiments on TVSeries and THUMOS-14, the proposed methods outperform state-of-the-art methods by a significant margin in online action detection and action anticipation. Moreover, we demonstrate the effectiveness of the proposed units by conducting comprehensive ablation studies.
Single-view 2D CNNs with Fully Automatic Non-nodule Categorization for False Positive Reduction in Pulmonary Nodule Detection
Mar 09, 2020



Background and Objective: In pulmonary nodule detection, the first stage, candidate detection, aims to detect suspicious pulmonary nodules. However, detected candidates include many false positives and thus in the following stage, false positive reduction, such false positives are reliably reduced. Note that this task is challenging due to 1) the imbalance between the numbers of nodules and non-nodules and 2) the intra-class diversity of non-nodules. Although techniques using 3D convolutional neural networks (CNNs) have shown promising performance, they suffer from high computational complexity which hinders constructing deep networks. To efficiently address these problems, we propose a novel framework using the ensemble of 2D CNNs using single views, which outperforms existing 3D CNN-based methods. Methods: Our ensemble of 2D CNNs utilizes single-view 2D patches to improve both computational and memory efficiency compared to previous techniques exploiting 3D CNNs. We first categorize non-nodules on the basis of features encoded by an autoencoder. Then, all 2D CNNs are trained by using the same nodule samples, but with different types of non-nodules. By extending the learning capability, this training scheme resolves difficulties of extracting representative features from non-nodules with large appearance variations. Note that, instead of manual categorization requiring the heavy workload of radiologists, we propose to automatically categorize non-nodules based on the autoencoder and k-means clustering.
* 12 pages, 16 figures
Learning to Discriminate Information for Online Action Detection
Dec 10, 2019From a streaming video, online action detection aims to identify actions in the present. For this task, previous methods use recurrent networks to model the temporal sequence of current action frames. However, these methods overlook the fact that an input image sequence includes background and irrelevant actions as well as the action of interest. For online action detection, in this paper, we propose a novel recurrent unit to explicitly discriminate the information relevant to an ongoing action from others. Our unit, named Information Discrimination Unit (IDU), decides whether to accumulate input information based on its relevance to the current action. This enables our recurrent network with IDU to learn a more discriminative representation for identifying ongoing actions. In experiments on two benchmark datasets, TVSeries and THUMOS-14, the proposed method outperforms state-of-the-art methods by a significant margin. Moreover, we demonstrate the effectiveness of our recurrent unit by conducting comprehensive ablation studies.
SRG: Snippet Relatedness-based Temporal Action Proposal Generator
Nov 26, 2019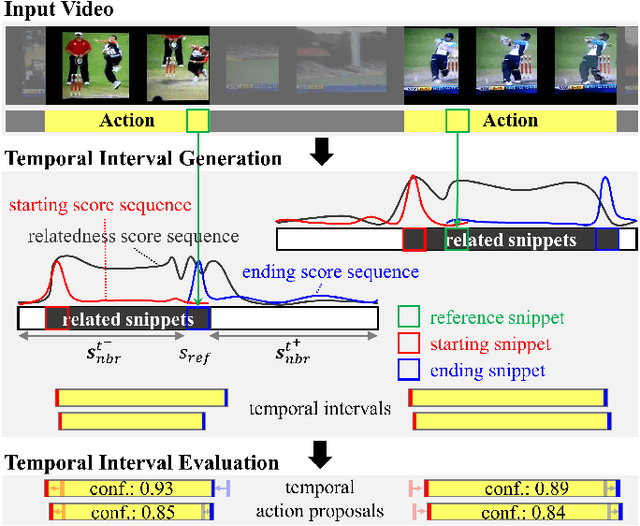
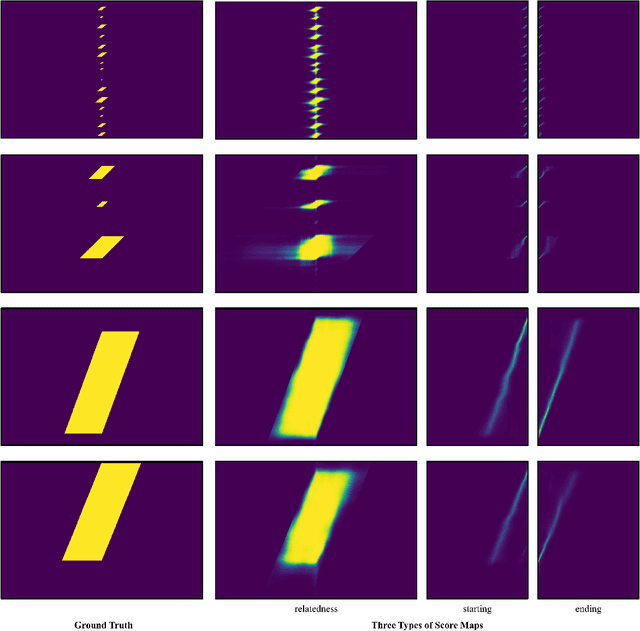
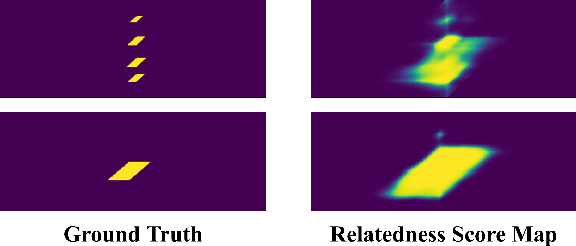
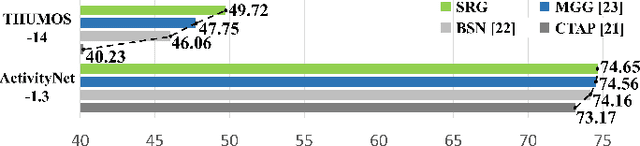
Recent temporal action proposal generation approaches have suggested integrating segment- and snippet score-based methodologies to produce proposals with high recall and accurate boundaries. In this paper, different from such a hybrid strategy, we focus on the potential of the snippet score-based approach. Specifically, we propose a new snippet score-based method, named Snippet Relatedness-based Generator (SRG), with a novel concept of "snippet relatedness". Snippet relatedness represents which snippets are related to a specific action instance. To effectively learn this snippet relatedness, we present ``pyramid non-local operations'' for locally and globally capturing long-range dependencies among snippets. By employing these components, SRG first produces a 2D relatedness score map that enables the generation of various temporal intervals reliably covering most action instances with high overlap. Then, SRG evaluates the action confidence scores of these temporal intervals and refines their boundaries to obtain temporal action proposals. On THUMOS-14 and ActivityNet-1.3 datasets, SRG outperforms state-of-the-art methods for temporal action proposal generation. Furthermore, compared to competing proposal generators, SRG leads to significant improvements in temporal action detection.
A Global-Local Emebdding Module for Fashion Landmark Detection
Aug 28, 2019
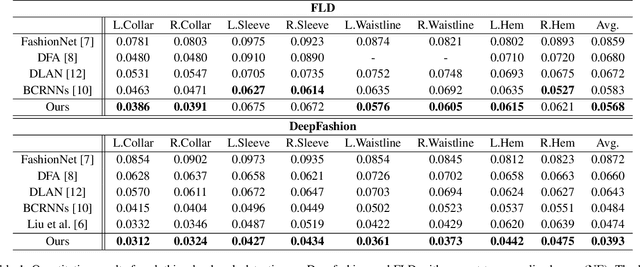
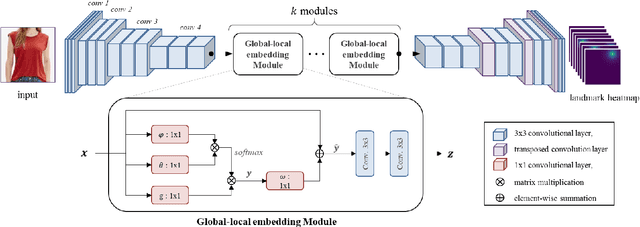

Detecting fashion landmarks is a fundamental technique for visual clothing analysis. Due to the large variation and non-rigid deformation of clothes, localizing fashion landmarks suffers from large spatial variances across poses, scales, and styles. Therefore, understanding contextual knowledge of clothes is required for accurate landmark detection. To that end, in this paper, we propose a fashion landmark detection network with a global-local embedding module. The global-local embedding module is based on a non-local operation for capturing long-range dependencies and a subsequent convolution operation for adopting local neighborhood relations. With this processing, the network can consider both global and local contextual knowledge for a clothing image. We demonstrate that our proposed method has an excellent ability to learn advanced deep feature representations for fashion landmark detection. Experimental results on two benchmark datasets show that the proposed network outperforms the state-of-the-art methods. Our code is available at https://github.com/shumming/GLE_FLD.