 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Discriminate Information for Online Action Detection: Analysis and Application
Sep 09, 2021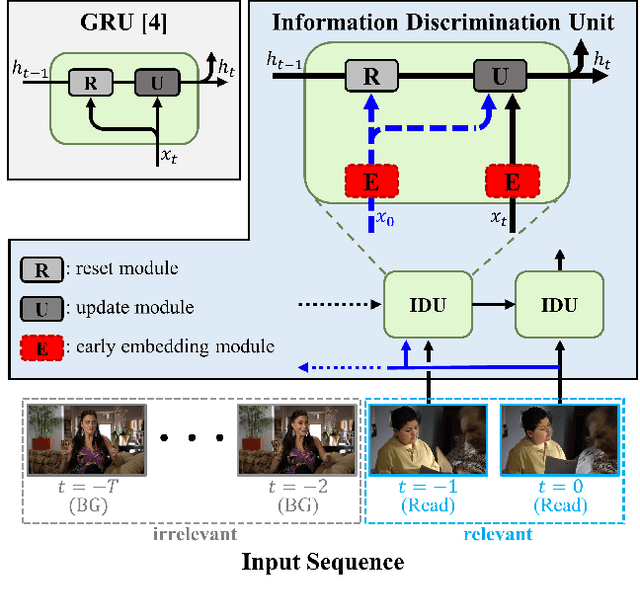
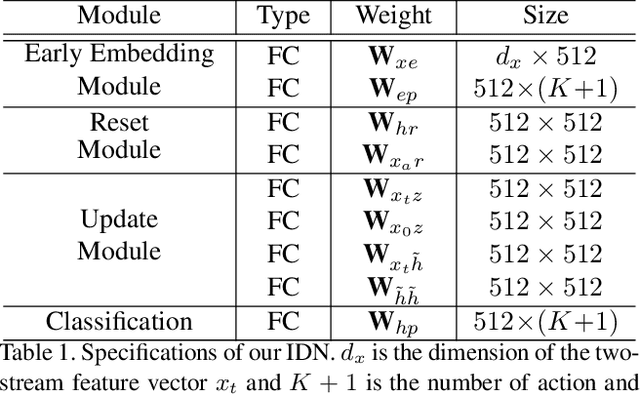
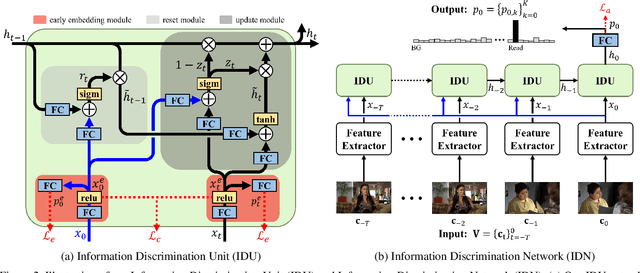
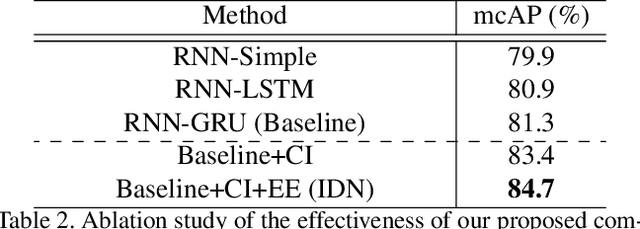
Online action detection, which aims to identify an ongoing action from a streaming video, is an important subject in real-world applications. For this task, previous methods use recurrent neural networks for modeling temporal relations in an input sequence. However, these methods overlook the fact that the input image sequence includes not only the action of interest but background and irrelevant actions. This would induce recurrent units to accumulate unnecessary information for encoding features on the action of interest. To overcome this problem, we propose a novel recurrent unit, named Information Discrimination Unit (IDU), which explicitly discriminates the information relevancy between an ongoing action and others to decide whether to accumulate the input information. This enables learning more discriminative representations for identifying an ongoing action. In this paper, we further present a new recurrent unit, called Information Integration Unit (IIU), for action anticipation. Our IIU exploits the outputs from IDU as pseudo action labels as well as RGB frames to learn enriched features of observed actions effectively. In experiments on TVSeries and THUMOS-14, the proposed methods outperform state-of-the-art methods by a significant margin in online action detection and action anticipation. Moreover, we demonstrate the effectiveness of the proposed units by conducting comprehensive ablation studies.
Semi-Supervised Domain Adaptation via Selective Pseudo Labeling and Progressive Self-Training
Apr 01, 2021
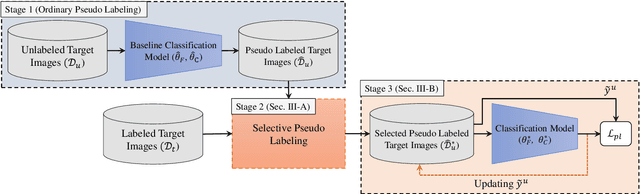
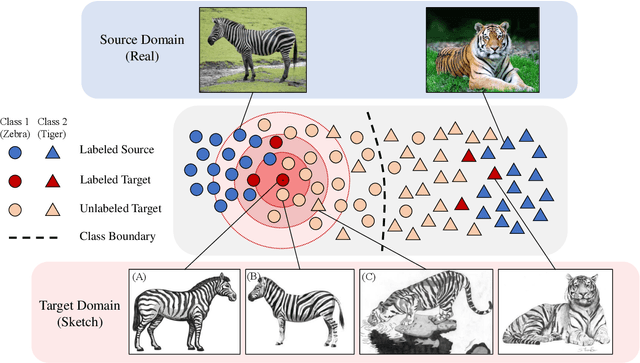
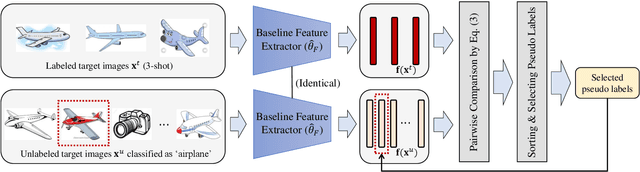
Domain adaptation (DA) is a representation learning methodology that transfers knowledge from a label-sufficient source domain to a label-scarce target domain. While most of early methods are focused on unsupervised DA (UDA), several studies on semi-supervised DA (SSDA) are recently suggested. In SSDA, a small number of labeled target images are given for training, and the effectiveness of those data is demonstrated by the previous studies. However, the previous SSDA approaches solely adopt those data for embedding ordinary supervised losses, overlooking the potential usefulness of the few yet informative clues. Based on this observation, in this paper, we propose a novel method that further exploits the labeled target images for SSDA. Specifically, we utilize labeled target images to selectively generate pseudo labels for unlabeled target images. In addition, based on the observation that pseudo labels are inevitably noisy, we apply a label noise-robust learning scheme, which progressively updates the network and the set of pseudo labels by turns. Extensive experimental results show that our proposed method outperforms other previous state-of-the-art SSDA methods.
Combinational Class Activation Maps for Weakly Supervised Object Localization
Oct 12, 2019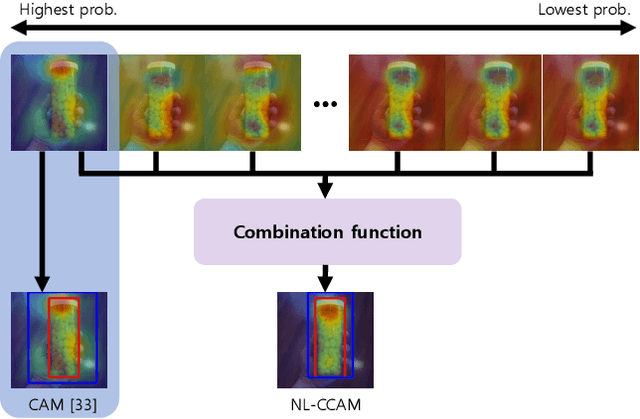
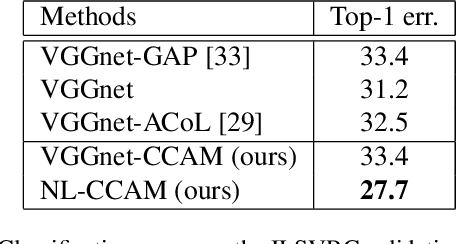
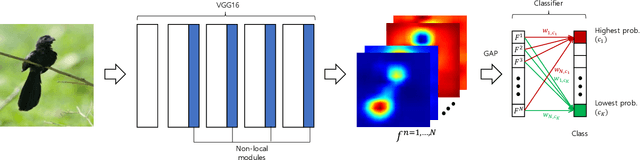

Weakly supervised object localization has recently attracted attention since it aims to identify both class labels and locations of objects by using image-level labels. Most previous methods utilize the activation map corresponding to the highest activation source. Exploiting only one activation map of the highest probability class is often biased into limited regions or sometimes even highlights background regions. To resolve these limitations, we propose to use activation maps, named combinational class activation maps (CCAM), which are linear combinations of activation maps from the highest to the lowest probability class. By using CCAM for localization, we suppress background regions to help highlighting foreground objects more accurately. In addition, we design the network architecture to consider spatial relationships for localizing relevant object regions. Specifically, we integrate non-local modules into an existing base network at both low- and high-level layers. Our final model, named non-local combinational class activation maps (NL-CCAM), obtains superior performance compared to previous methods on representative object localization benchmarks including ILSVRC 2016 and CUB-200-2011. Furthermore, we show that the proposed method has a great capability of generalization by visualizing other datasets.