 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenterMask : Real-Time Anchor-Free Instance Segmentation
Paper and Code
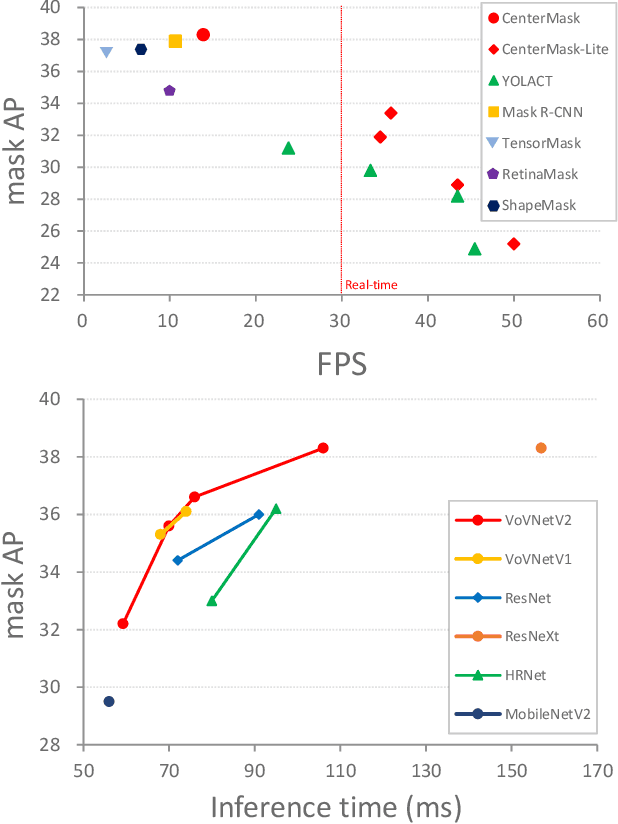
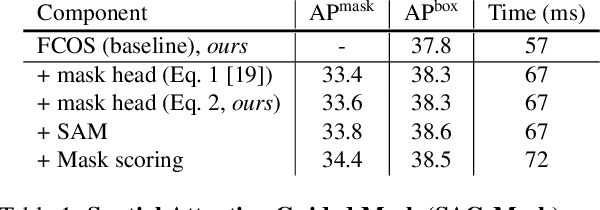
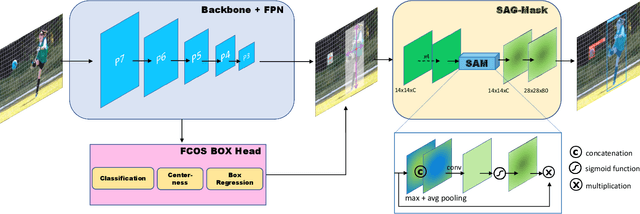
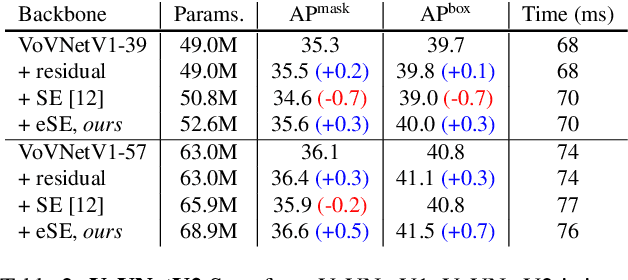
We propose a simple yet efficient anchor-free instance segmentation, called CenterMask, that adds a novel spatial attention-guided mask (SAG-Mask) branch to anchor-free one stage object detector (FCOS) in the same vein with Mask R-CNN. Plugged into the FCOS object detector, the SAG-Mask branch predicts a segmentation mask on each box with the spatial attention map that helps to focus on informative pixels and suppress noise. We also present an improved VoVNetV2 with two effective strategies: adds (1) residual connection for alleviating the saturation problem of larger VoVNet and (2) effective Squeeze-Excitation (eSE) deals with the information loss problem of original SE. With SAG-Mask and VoVNetV2, we deign CenterMask and CenterMask-Lite that are targeted to large and small models, respectively. CenterMask outperforms all previous state-of-the-art models at a much faster speed. CenterMask-Lite also achieves 33.4\% mask AP / 38.0\% box AP, outperforming the state-of-the-art by 2.6 / 7.0 AP gain, respectively, at over 35fps on Titan Xp. We hope that CenterMask and VoVNetV2 can serve as a solid baseline of real-time instance segmentation and backbone network for various vision tasks, respectively. Code will be released.