 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Automatic Self-Talk Detection via Earables
Nov 10, 2025



Self-talk-an internal dialogue that can occur silently or be spoken aloud-plays a crucial role in emotional regulation, cognitive processing, and motivation, yet has remained largely invisible and unmeasurable in everyday life. In this paper, we present MutterMeter, a mobile system that automatically detects vocalized self-talk from audio captured by earable microphones in real-world settings. Detecting self-talk is technically challenging due to its diverse acoustic forms, semantic and grammatical incompleteness, and irregular occurrence patterns, which differ fundamentally from assumptions underlying conventional speech understanding models. To address these challenges, MutterMeter employs a hierarchical classification architecture that progressively integrates acoustic, linguistic, and contextual information through a sequential processing pipeline, adaptively balancing accuracy and computational efficiency. We build and evaluate MutterMeter using a first-of-its-kind dataset comprising 31.1 hours of audio collected from 25 participants. Experimental results demonstrate that MutterMeter achieves robust performance with a macro-averaged F1 score of 0.84, outperforming conventional approaches, including LLM-based and speech emotion recognition models.
TARDiS : Text Augmentation for Refining Diversity and Separability
Jan 06, 2025



Text augmentation (TA) is a critical technique for text classification, especially in few-shot settings. This paper introduces a novel LLM-based TA method, TARDiS, to address challenges inherent in the generation and alignment stages of two-stage TA methods. For the generation stage, we propose two generation processes, SEG and CEG, incorporating multiple class-specific prompts to enhance diversity and separability. For the alignment stage, we introduce a class adaptation (CA) method to ensure that generated examples align with their target classes through verification and modification. Experimental results demonstrate TARDiS's effectiveness, outperforming state-of-the-art LLM-based TA methods in various few-shot text classification tasks. An in-depth analysis confirms the detailed behaviors at each stage.
LidaRefer: Outdoor 3D Visual Grounding for Autonomous Driving with Transformers
Nov 07, 20243D visual grounding (VG) aims to locate relevant objects or regions within 3D scenes based on natural language descriptions. Although recent methods for indoor 3D VG have successfully transformer-based architectures to capture global contextual information and enable fine-grained cross-modal fusion, they are unsuitable for outdoor environments due to differences in the distribution of point clouds between indoor and outdoor settings. Specifically, first, extensive LiDAR point clouds demand unacceptable computational and memory resources within transformers due to the high-dimensional visual features. Second, dominant background points and empty spaces in sparse LiDAR point clouds complicate cross-modal fusion owing to their irrelevant visual information. To address these challenges, we propose LidaRefer, a transformer-based 3D VG framework designed for large-scale outdoor scenes. Moreover, during training, we introduce a simple and effective localization method, which supervises the decoder's queries to localize not only a target object but also ambiguous objects that might be confused as the target due to the exhibition of similar attributes in a scene or the incorrect understanding of a language description. This supervision enhances the model's ability to distinguish ambiguous objects from a target by learning the differences in their spatial relationships and attributes. LidaRefer achieves state-of-the-art performance on Talk2Car-3D, a 3D VG dataset for autonomous driving, with significant improvements under various evaluation settings.
Unified Negative Pair Generation toward Well-discriminative Feature Space for Face Recognition
Mar 22, 2022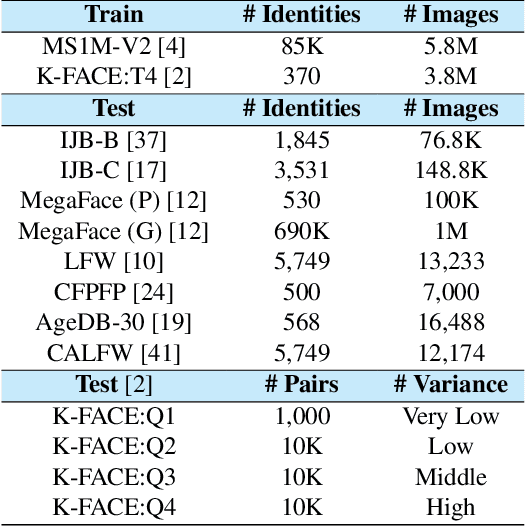



The goal of face recognition (FR) can be viewed as a pair similarity optimization problem, maximizing a similarity set $\mathcal{S}^p$ over positive pairs, while minimizing similarity set $\mathcal{S}^n$ over negative pairs. Ideally, it is expected that FR models form a well-discriminative feature space (WDFS) that satisfies $\inf{\mathcal{S}^p} > \sup{\mathcal{S}^n}$. With regard to WDFS, the existing deep feature learning paradigms (i.e., metric and classification losses) can be expressed as a unified perspective on different pair generation (PG) strategies. Unfortunately, in the metric loss (ML), it is infeasible to generate negative pairs taking all classes into account in each iteration because of the limited mini-batch size. In contrast, in classification loss (CL), it is difficult to generate extremely hard negative pairs owing to the convergence of the class weight vectors to their center. This leads to a mismatch between the two similarity distributions of the sampled pairs and all negative pairs. Thus, this paper proposes a unified negative pair generation (UNPG) by combining two PG strategies (i.e., MLPG and CLPG) from a unified perspective to alleviate the mismatch. UNPG introduces useful information about negative pairs using MLPG to overcome the CLPG deficiency. Moreover, it includes filtering the similarities of noisy negative pairs to guarantee reliable convergence and improved performance. Exhaustive experiments show the superiority of UNPG by achieving state-of-the-art performance across recent loss functions on public benchmark datasets. Our code and pretrained models are publicly available.
LAME: Layout Aware Metadata Extraction Approach for Research Articles
Dec 23, 2021



The volume of academic literature, such as academic conference papers and journals, has increased rapidly worldwide, and research on metadata extraction is ongoing. However, high-performing metadata extraction is still challenging due to diverse layout formats according to journal publishers. To accommodate the diversity of the layouts of academic journals, we propose a novel LAyout-aware Metadata Extraction (LAME) framework equipped with the three characteristics (e.g., design of an automatic layout analysis, construction of a large meta-data training set, and construction of Layout-MetaBERT). We designed an automatic layout analysis using PDFMiner. Based on the layout analysis, a large volume of metadata-separated training data, including the title, abstract, author name, author affiliated organization, and keywords, were automatically extracted. Moreover, we constructed Layout-MetaBERT to extract the metadata from academic journals with varying layout formats. The experimental results with Layout-MetaBERT exhibited robust performance (Macro-F1, 93.27%) in metadata extraction for unseen journals with different layout formats.
Hierarchy Decoder is All You Need To Text Classification
Nov 22, 2021



Hierarchical text classification (HTC) to a taxonomy is essential for various real applications butchallenging since HTC models often need to process a large volume of data that are severelyimbalanced and have hierarchy dependencies. Existing local and global approaches use deep learningto improve HTC by reducing the time complexity and incorporating the hierarchy dependencies.However, it is difficult to satisfy both conditions in a single HTC model. This paper proposes ahierarchy decoder (HiDEC) that uses recursive hierarchy decoding based on an encoder-decoderarchitecture. The key idea of the HiDEC involves decoding a context matrix into a sub-hierarchysequence using recursive hierarchy decoding, while staying aware of hierarchical dependenciesand level information. The HiDEC is a unified model that incorporates the benefits of existingapproaches, thereby alleviating the aforementioned difficulties without any trade-off. In addition, itcan be applied to both single- and multi-label classification with a minor modification. The superiorityof the proposed model was verified on two benchmark datasets (WOS-46985 and RCV1) with anexplanation of the reasons for its success
MixFace: Improving Face Verification Focusing on Fine-grained Conditions
Nov 19, 2021



The performance of face recognition has become saturated for public benchmark datasets such as LFW, CFP-FP, and AgeDB, owing to the rapid advances in CNNs. However, the effects of faces with various fine-grained conditions on FR models have not been investigated because of the absence of such datasets. This paper analyzes their effects in terms of different conditions and loss functions using K-FACE, a recently introduced FR dataset with fine-grained conditions. We propose a novel loss function, MixFace, that combines classification and metric losses. The superiority of MixFace in terms of effectiveness and robustness is demonstrated experimentally on various benchmark datasets.