 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Negative Pair Generation toward Well-discriminative Feature Space for Face Recognition
Mar 22, 2022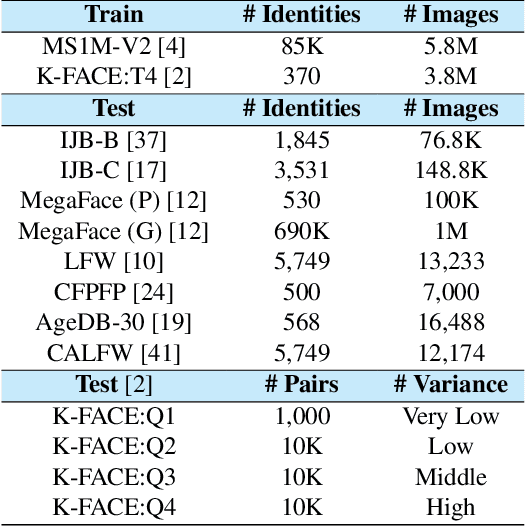



The goal of face recognition (FR) can be viewed as a pair similarity optimization problem, maximizing a similarity set $\mathcal{S}^p$ over positive pairs, while minimizing similarity set $\mathcal{S}^n$ over negative pairs. Ideally, it is expected that FR models form a well-discriminative feature space (WDFS) that satisfies $\inf{\mathcal{S}^p} > \sup{\mathcal{S}^n}$. With regard to WDFS, the existing deep feature learning paradigms (i.e., metric and classification losses) can be expressed as a unified perspective on different pair generation (PG) strategies. Unfortunately, in the metric loss (ML), it is infeasible to generate negative pairs taking all classes into account in each iteration because of the limited mini-batch size. In contrast, in classification loss (CL), it is difficult to generate extremely hard negative pairs owing to the convergence of the class weight vectors to their center. This leads to a mismatch between the two similarity distributions of the sampled pairs and all negative pairs. Thus, this paper proposes a unified negative pair generation (UNPG) by combining two PG strategies (i.e., MLPG and CLPG) from a unified perspective to alleviate the mismatch. UNPG introduces useful information about negative pairs using MLPG to overcome the CLPG deficiency. Moreover, it includes filtering the similarities of noisy negative pairs to guarantee reliable convergence and improved performance. Exhaustive experiments show the superiority of UNPG by achieving state-of-the-art performance across recent loss functions on public benchmark datasets. Our code and pretrained models are publicly available.
MixFace: Improving Face Verification Focusing on Fine-grained Conditions
Nov 19, 2021



The performance of face recognition has become saturated for public benchmark datasets such as LFW, CFP-FP, and AgeDB, owing to the rapid advances in CNNs. However, the effects of faces with various fine-grained conditions on FR models have not been investigated because of the absence of such datasets. This paper analyzes their effects in terms of different conditions and loss functions using K-FACE, a recently introduced FR dataset with fine-grained conditions. We propose a novel loss function, MixFace, that combines classification and metric losses. The superiority of MixFace in terms of effectiveness and robustness is demonstrated experimentally on various benchmark datasets.