 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Aware Embedding Fusion for LLMs in Text Classifications
Apr 08, 2025



Embedding fusion has emerged as an effective approach for enhancing performance across various NLP tasks. However, systematic guidelines for selecting optimal layers and developing effective fusion strategies for the integration of LLMs remain underexplored. In this study, we propose a layer-aware embedding selection method and investigate how to quantitatively evaluate different layers to identify the most important ones for downstream NLP tasks, showing that the critical layers vary depending on the dataset. We also explore how combining embeddings from multiple LLMs, without requiring model fine-tuning, can improve performance. Experiments on four English text classification datasets (SST-2, MR, R8, and R52) demonstrate that different layers in LLMs exhibit varying degrees of representational strength for classification, and that combining embeddings from different models can enhance performance if the models exhibit complementary characteristics. Additionally, we discuss resources overhead (memory and inference time) to provide a balanced perspective on the real world feasibility of embedding fusion. Future work will explore multilingual and domain specific datasets, as well as techniques for automating layer selection, to improve both performance and scalability.
Learning from Synthetic Data: Facial Expression Classification based on Ensemble of Multi-task Networks
Jul 21, 2022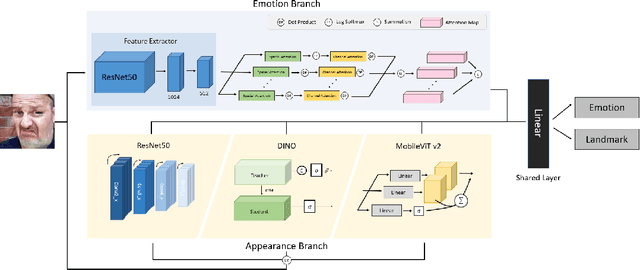


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Learning from Synthetic Data" (LSD) is an important topic in the facial expression recognition task. In this paper, we propose a multi-task learning-based facial expression recognition approach which consists of emotion and appearance learning branches that can share all face information, and present preliminary results for the LSD challenge introduced in the 4th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean F1 score of 0.71.
Facial Expression Recognition based on Multi-head Cross Attention Network
Mar 24, 2022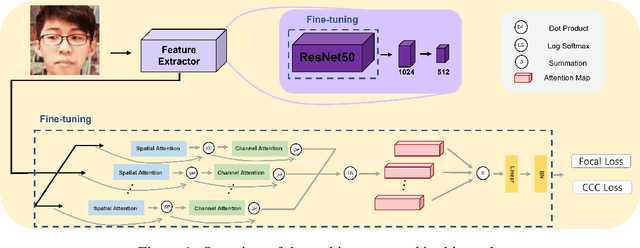


Facial expression in-the-wild is essential for various interactive computing domains. In this paper, we proposed an extended version of DAN model to address the VA estimation and facial expression challenges introduced in ABAW 2022. Our method produced preliminary results of 0.44 of mean CCC value for the VA estimation task, and 0.33 of the average F1 score for the expression classification task.
LAME: Layout Aware Metadata Extraction Approach for Research Articles
Dec 23, 2021



The volume of academic literature, such as academic conference papers and journals, has increased rapidly worldwide, and research on metadata extraction is ongoing. However, high-performing metadata extraction is still challenging due to diverse layout formats according to journal publishers. To accommodate the diversity of the layouts of academic journals, we propose a novel LAyout-aware Metadata Extraction (LAME) framework equipped with the three characteristics (e.g., design of an automatic layout analysis, construction of a large meta-data training set, and construction of Layout-MetaBERT). We designed an automatic layout analysis using PDFMiner. Based on the layout analysis, a large volume of metadata-separated training data, including the title, abstract, author name, author affiliated organization, and keywords, were automatically extracted. Moreover, we constructed Layout-MetaBERT to extract the metadata from academic journals with varying layout formats. The experimental results with Layout-MetaBERT exhibited robust performance (Macro-F1, 93.27%) in metadata extraction for unseen journals with different layout formats.