 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Free Classifier Guidance for Diffusion Model Sampling
Nov 23, 2024



Image generation using diffusion models have demonstrated outstanding learning capabilities, effectively capturing the full distribution of the training dataset. They are known to generate wide variations in sampled images, albeit with a trade-off in image fidelity. Guided sampling methods, such as classifier guidance (CG) and classifier-free guidance (CFG), focus sampling in well-learned high-probability regions to generate images of high fidelity, but each has its limitations. CG is computationally expensive due to the use of back-propagation for classifier gradient descent, while CFG, being gradient-free, is more efficient but compromises class label alignment compared to CG. In this work, we propose an efficient guidance method that fully utilizes a pre-trained classifier without using gradient descent. By using the classifier solely in inference mode, a time-adaptive reference class label and corresponding guidance scale are determined at each time step for guided sampling. Experiments on both class-conditioned and text-to-image generation diffusion models demonstrate that the proposed Gradient-free Classifier Guidance (GFCG) method consistently improves class prediction accuracy. We also show GFCG to be complementary to other guided sampling methods like CFG. When combined with the state-of-the-art Autoguidance (ATG), without additional computational overhead, it enhances image fidelity while preserving diversity. For ImageNet 512$\times$512, we achieve a record $\text{FD}_{\text{DINOv2}}$ of 23.09, while simultaneously attaining a higher classification Precision (94.3%) compared to ATG (90.2%)
BTranspose: Bottleneck Transformers for Human Pose Estimation with Self-Supervised Pre-Training
Apr 21, 2022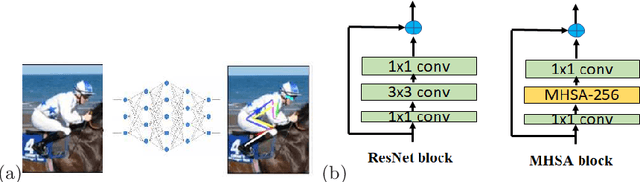
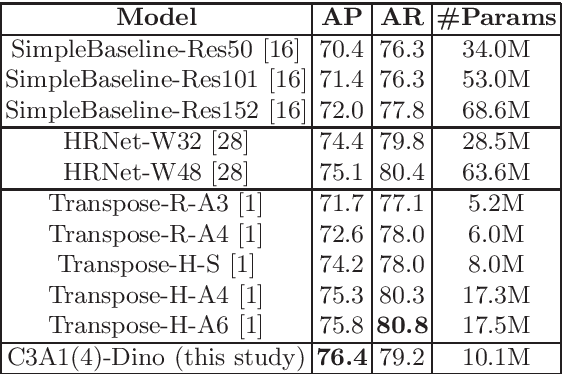

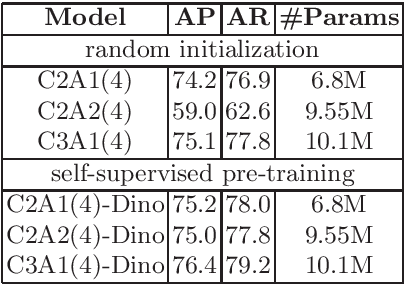
The task of 2D human pose estimation is challenging as the number of keypoints is typically large (~ 17) and this necessitates the use of robust neural network architectures and training pipelines that can capture the relevant features from the input image. These features are then aggregated to make accurate heatmap predictions from which the final keypoints of human body parts can be inferred. Many papers in literature use CNN-based architectures for the backbone, and/or combine it with a transformer, after which the features are aggregated to make the final keypoint predictions [1]. In this paper, we consider the recently proposed Bottleneck Transformers [2], which combine CNN and multi-head self attention (MHSA) layers effectively, and we integrate it with a Transformer encoder and apply it to the task of 2D human pose estimation. We consider different backbone architectures and pre-train them using the DINO self-supervised learning method [3], this pre-training is found to improve the overall prediction accuracy. We call our model BTranspose, and experiments show that on the COCO validation set, our model achieves an AP of 76.4, which is competitive with other methods such as [1] and has fewer network parameters. Furthermore, we also present the dependencies of the final predicted keypoints on both the MHSA block and the Transformer encoder layers, providing clues on the image sub-regions the network attends to at the mid and high levels.
Stochastic Adversarial Koopman Model for Dynamical Systems
Sep 10, 2021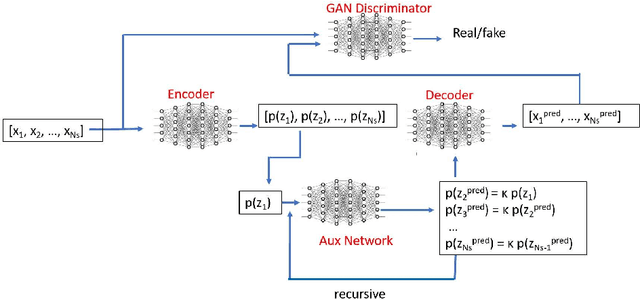
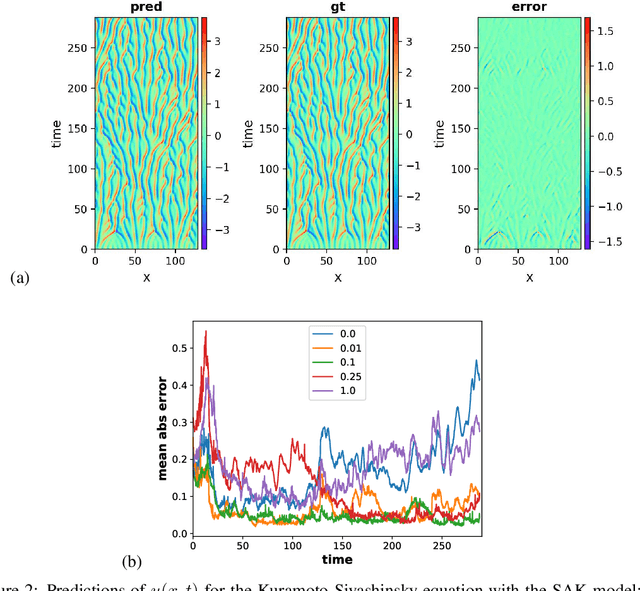
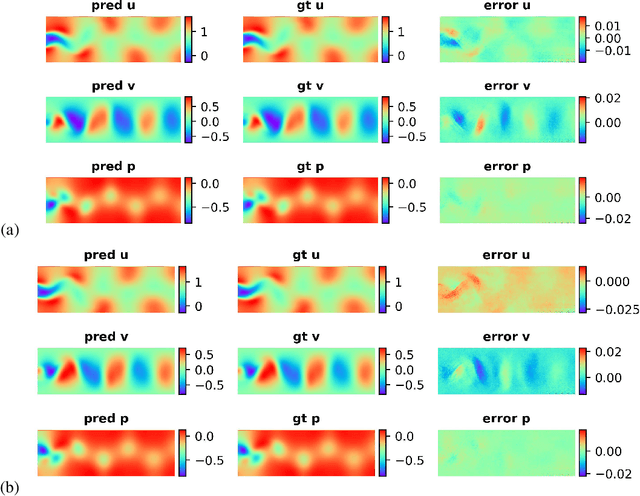
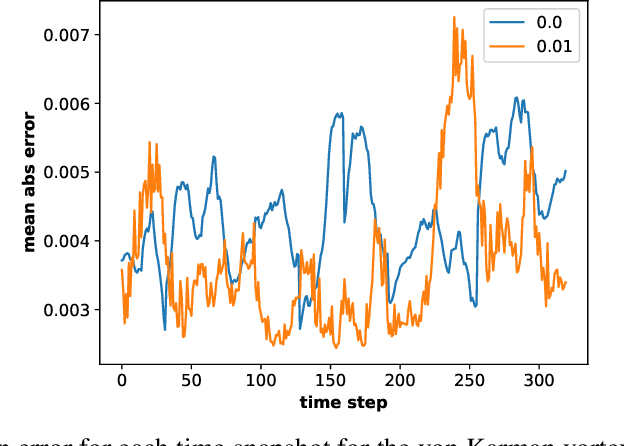
Dynamical systems are ubiquitous and are often modeled using a non-linear system of governing equations. Numerical solution procedures for many dynamical systems have existed for several decades, but can be slow due to high-dimensional state space of the dynamical system. Thus, deep learning-based reduced order models (ROMs) are of interest and one such family of algorithms along these lines are based on the Koopman theory. This paper extends a recently developed adversarial Koopman model (Balakrishnan \& Upadhyay, arXiv:2006.05547) to stochastic space, where the Koopman operator applies on the probability distribution of the latent encoding of an encoder. Specifically, the latent encoding of the system is modeled as a Gaussian, and is advanced in time by using an auxiliary neural network that outputs two Koopman matrices $K_{\mu}$ and $K_{\sigma}$. Adversarial and gradient losses are used and this is found to lower the prediction errors. A reduced Koopman formulation is also undertaken where the Koopman matrices are assumed to have a tridiagonal structure, and this yields predictions comparable to the baseline model with full Koopman matrices. The efficacy of the stochastic Koopman model is demonstrated on different test problems in chaos, fluid dynamics, combustion, and reaction-diffusion models. The proposed model is also applied in a setting where the Koopman matrices are conditioned on other input parameters for generalization and this is applied to simulate the state of a Lithium-ion battery in time. The Koopman models discussed in this study are very promising for the wide range of problems considered.
An A* Curriculum Approach to Reinforcement Learning for RGBD Indoor Robot Navigation
Jan 05, 2021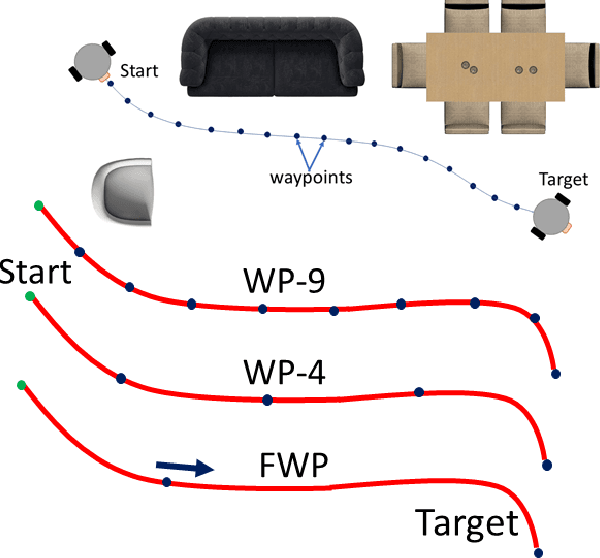
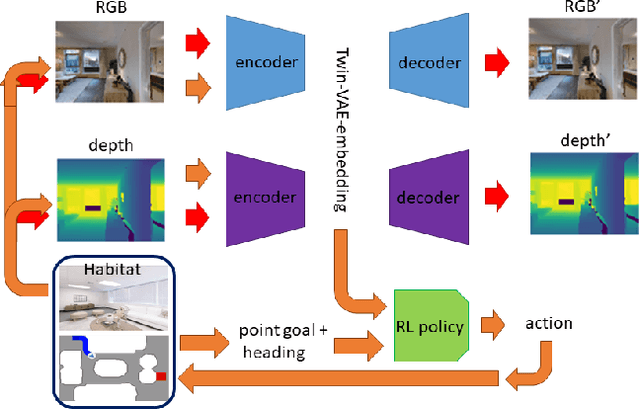
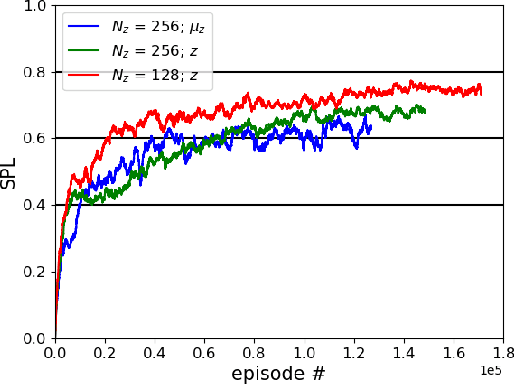
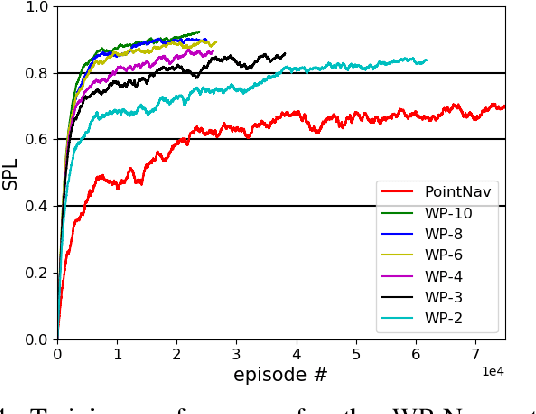
Training robots to navigate diverse environments is a challenging problem as it involves the confluence of several different perception tasks such as mapping and localization, followed by optimal path-planning and control. Recently released photo-realistic simulators such as Habitat allow for the training of networks that output control actions directly from perception: agents use Deep Reinforcement Learning (DRL) to regress directly from the camera image to a control output in an end-to-end fashion. This is data-inefficient and can take several days to train on a GPU. Our paper tries to overcome this problem by separating the training of the perception and control neural nets and increasing the path complexity gradually using a curriculum approach. Specifically, a pre-trained twin Variational AutoEncoder (VAE) is used to compress RGBD (RGB & depth) sensing from an environment into a latent embedding, which is then used to train a DRL-based control policy. A*, a traditional path-planner is used as a guide for the policy and the distance between start and target locations is incrementally increased along the A* route, as training progresses. We demonstrate the efficacy of the proposed approach, both in terms of increased performance and decreased training times for the PointNav task in the Habitat simulation environment. This strategy of improving the training of direct-perception based DRL navigation policies is expected to hasten the deployment of robots of particular interest to industry such as co-bots on the factory floor and last-mile delivery robots.
Deep Adversarial Koopman Model for Reaction-Diffusion systems
Jun 09, 2020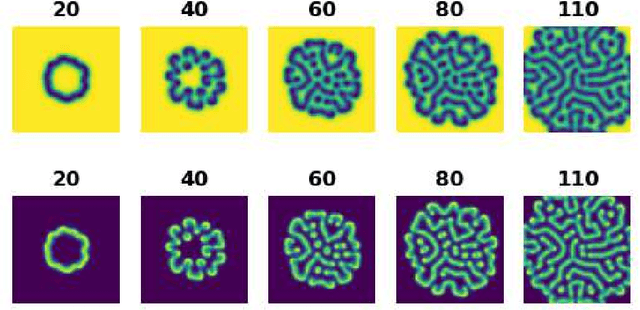
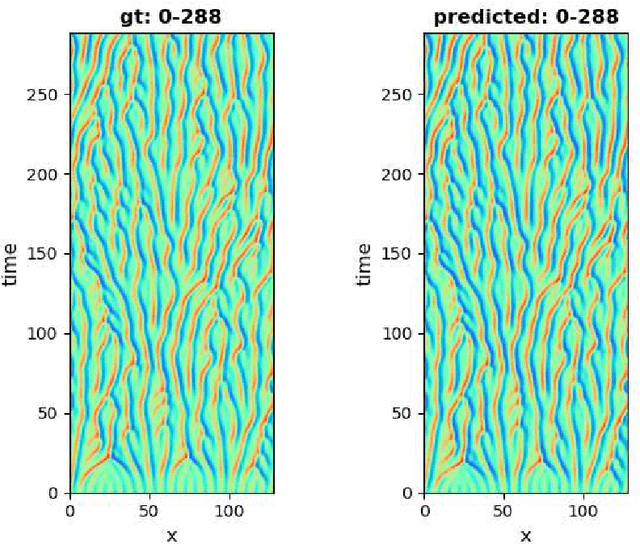
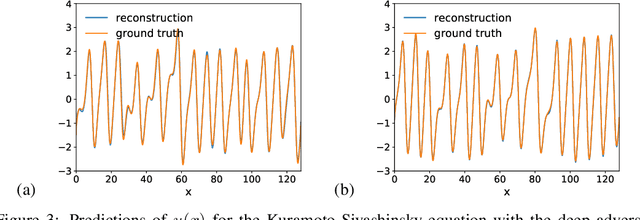

Reaction-diffusion systems are ubiquitous in nature and in engineering applications, and are often modeled using a non-linear system of governing equations. While robust numerical methods exist to solve them, deep learning-based reduced ordermodels (ROMs) are gaining traction as they use linearized dynamical models to advance the solution in time. One such family of algorithms is based on Koopman theory, and this paper applies this numerical simulation strategy to reaction-diffusion systems. Adversarial and gradient losses are introduced, and are found to robustify the predictions. The proposed model is extended to handle missing training data as well as recasting the problem from a control perspective. The efficacy of these developments are demonstrated for two different reaction-diffusion problems: (1) the Kuramoto-Sivashinsky equation of chaos and (2) the Turing instability using the Gray-Scott model.