 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Reconstruction and Differential Testing of Excised mRNA
Nov 14, 2022



Characterizing the differential excision of mRNA is critical for understanding the functional complexity of a cell or tissue, from normal developmental processes to disease pathogenesis. Most transcript reconstruction methods infer full-length transcripts from high-throughput sequencing data. However, this is a challenging task due to incomplete annotations and the differential expression of transcripts across cell-types, tissues, and experimental conditions. Several recent methods circumvent these difficulties by considering local splicing events, but these methods lose transcript-level splicing information and may conflate transcripts. We develop the first probabilistic model that reconciles the transcript and local splicing perspectives. First, we formalize the sequence of mRNA excisions (SME) reconstruction problem, which aims to assemble variable-length sequences of mRNA excisions from RNA-sequencing data. We then present a novel hierarchical Bayesian admixture model for the Reconstruction of Excised mRNA (BREM). BREM interpolates between local splicing events and full-length transcripts and thus focuses only on SMEs that have high posterior probability. We develop posterior inference algorithms based on Gibbs sampling and local search of independent sets and characterize differential SME usage using generalized linear models based on converged BREM model parameters. We show that BREM achieves higher F1 score for reconstruction tasks and improved accuracy and sensitivity in differential splicing when compared with four state-of-the-art transcript and local splicing methods on simulated data. Lastly, we evaluate BREM on both bulk and scRNA sequencing data based on transcript reconstruction, novelty of transcripts produced, model sensitivity to hyperparameters, and a functional analysis of differentially expressed SMEs, demonstrating that BREM captures relevant biological signal.
Interpretable Fake News Detection with Topic and Deep Variational Models
Sep 04, 2022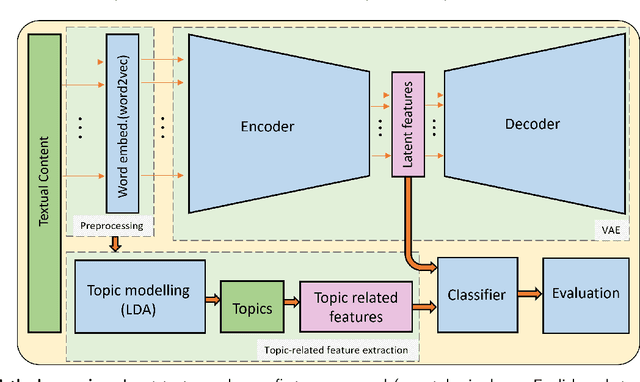
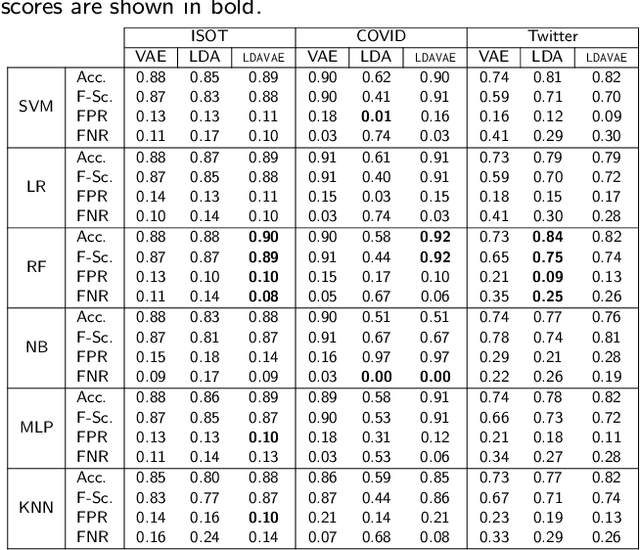
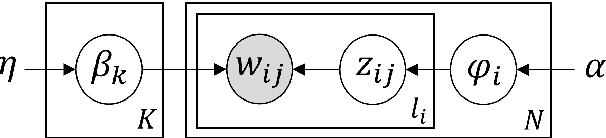
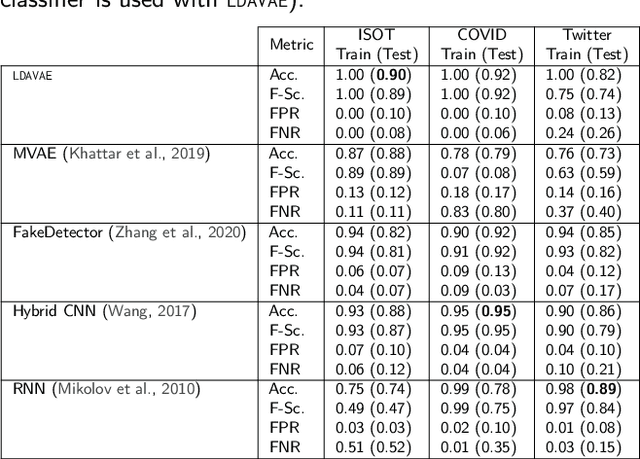
The growing societal dependence on social media and user generated content for news and information has increased the influence of unreliable sources and fake content, which muddles public discourse and lessens trust in the media. Validating the credibility of such information is a difficult task that is susceptible to confirmation bias, leading to the development of algorithmic techniques to distinguish between fake and real news. However, most existing methods are challenging to interpret, making it difficult to establish trust in predictions, and make assumptions that are unrealistic in many real-world scenarios, e.g., the availability of audiovisual features or provenance. In this work, we focus on fake news detection of textual content using interpretable features and methods. In particular, we have developed a deep probabilistic model that integrates a dense representation of textual news using a variational autoencoder and bi-directional Long Short-Term Memory (LSTM) networks with semantic topic-related features inferred from a Bayesian admixture model. Extensive experimental studies with 3 real-world datasets demonstrate that our model achieves comparable performance to state-of-the-art competing models while facilitating model interpretability from the learned topics. Finally, we have conducted model ablation studies to justify the effectiveness and accuracy of integrating neural embeddings and topic features both quantitatively by evaluating performance and qualitatively through separability in lower dimensional embeddings.