 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-exposed jobs deteriorated before ChatGPT
Jan 05, 2026Public debate links worsening job prospects for AI-exposed occupations to the release of ChatGPT in late 2022. Using monthly U.S. unemployment insurance records, we measure occupation- and location-specific unemployment risk and find that risk rose in AI-exposed occupations beginning in early 2022, months before ChatGPT. Analyzing millions of LinkedIn profiles, we show that graduate cohorts from 2021 onward entered AI-exposed jobs at lower rates than earlier cohorts, with gaps opening before late 2022. Finally, from millions of university syllabi, we find that graduates taking more AI-exposed curricula had higher first-job pay and shorter job searches after ChatGPT. Together, these results point to forces pre-dating generative AI and to the ongoing value of LLM-relevant education.
A national longitudinal dataset of skills taught in U.S. higher education curricula
Apr 19, 2024Higher education plays a critical role in driving an innovative economy by equipping students with knowledge and skills demanded by the workforce. While researchers and practitioners have developed data systems to track detailed occupational skills, such as those established by the U.S. Department of Labor (DOL), much less effort has been made to document skill development in higher education at a similar granularity. Here, we fill this gap by presenting a longitudinal dataset of skills inferred from over three million course syllabi taught at nearly three thousand U.S. higher education institutions. To construct this dataset, we apply natural language processing to extract from course descriptions detailed workplace activities (DWAs) used by the DOL to describe occupations. We then aggregate these DWAs to create skill profiles for institutions and academic majors. Our dataset offers a large-scale representation of college-educated workers and their role in the economy. To showcase the utility of this dataset, we use it to 1) compare the similarity of skills taught and skills in the workforce according to the US Bureau of Labor Statistics, 2) estimate gender differences in acquired skills based on enrollment data, 3) depict temporal trends in the skills taught in social science curricula, and 4) connect college majors' skill distinctiveness to salary differences of graduates. Overall, this dataset can enable new research on the source of skills in the context of workforce development and provide actionable insights for shaping the future of higher education to meet evolving labor demands especially in the face of new technologies.
Interpretable Fake News Detection with Topic and Deep Variational Models
Sep 04, 2022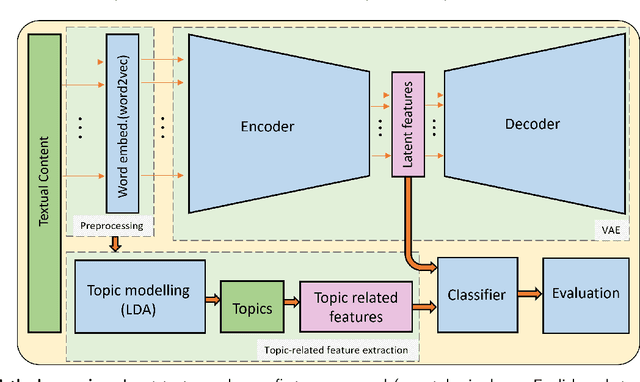
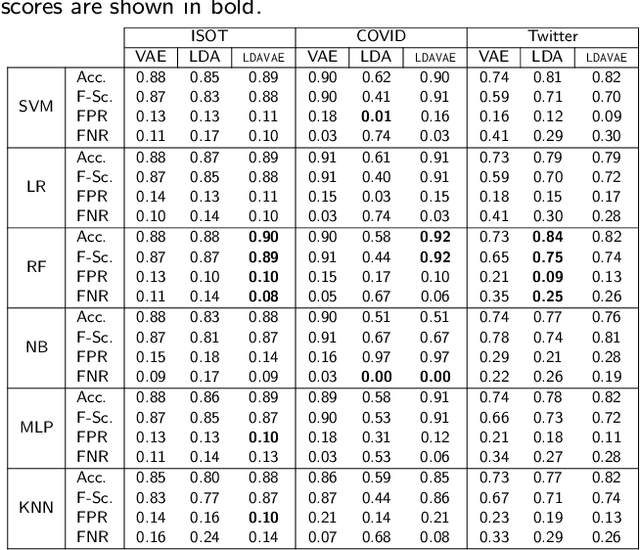
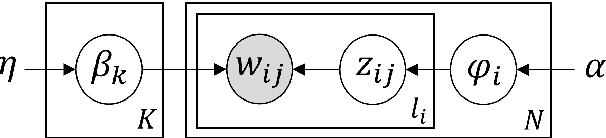
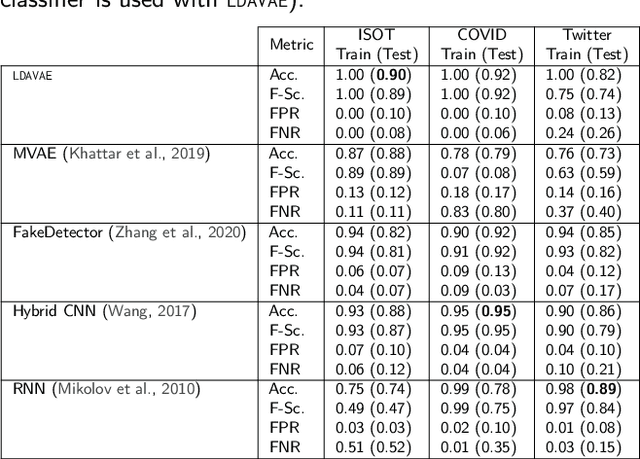
The growing societal dependence on social media and user generated content for news and information has increased the influence of unreliable sources and fake content, which muddles public discourse and lessens trust in the media. Validating the credibility of such information is a difficult task that is susceptible to confirmation bias, leading to the development of algorithmic techniques to distinguish between fake and real news. However, most existing methods are challenging to interpret, making it difficult to establish trust in predictions, and make assumptions that are unrealistic in many real-world scenarios, e.g., the availability of audiovisual features or provenance. In this work, we focus on fake news detection of textual content using interpretable features and methods. In particular, we have developed a deep probabilistic model that integrates a dense representation of textual news using a variational autoencoder and bi-directional Long Short-Term Memory (LSTM) networks with semantic topic-related features inferred from a Bayesian admixture model. Extensive experimental studies with 3 real-world datasets demonstrate that our model achieves comparable performance to state-of-the-art competing models while facilitating model interpretability from the learned topics. Finally, we have conducted model ablation studies to justify the effectiveness and accuracy of integrating neural embeddings and topic features both quantitatively by evaluating performance and qualitatively through separability in lower dimensional embeddings.