 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Google's SynthID-Text LLM Watermarking System: Theoretical Analysis and Empirical Validation
Mar 03, 2026Google's SynthID-Text, the first ever production-ready generative watermark system for large language model, designs a novel Tournament-based method that achieves the state-of-the-art detectability for identifying AI-generated texts. The system's innovation lies in: 1) a new Tournament sampling algorithm for watermarking embedding, 2) a detection strategy based on the introduced score function (e.g., Bayesian or mean score), and 3) a unified design that supports both distortionary and non-distortionary watermarking methods. This paper presents the first theoretical analysis of SynthID-Text, with a focus on its detection performance and watermark robustness, complemented by empirical validation. For example, we prove that the mean score is inherently vulnerable to increased tournament layers, and design a layer inflation attack to break SynthID-Text. We also prove the Bayesian score offers improved watermark robustness w.r.t. layers and further establish that the optimal Bernoulli distribution for watermark detection is achieved when the parameter is set to 0.5. Together, these theoretical and empirical insights not only deepen our understanding of SynthID-Text, but also open new avenues for analyzing effective watermark removal strategies and designing robust watermarking techniques. Source code is available at https: //github.com/romidi80/Synth-ID-Empirical-Analysis.
Learning Robust and Privacy-Preserving Representations via Information Theory
Dec 15, 2024
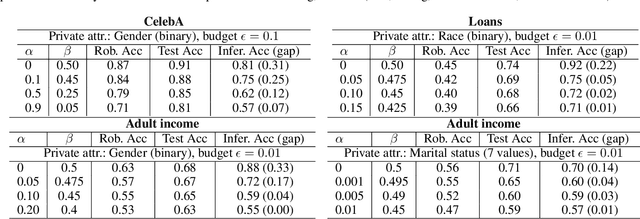
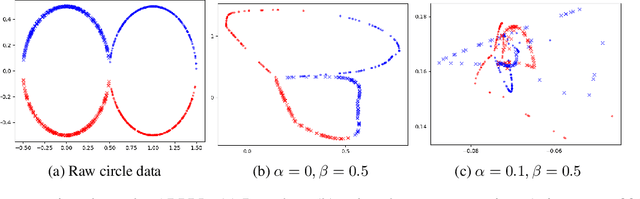
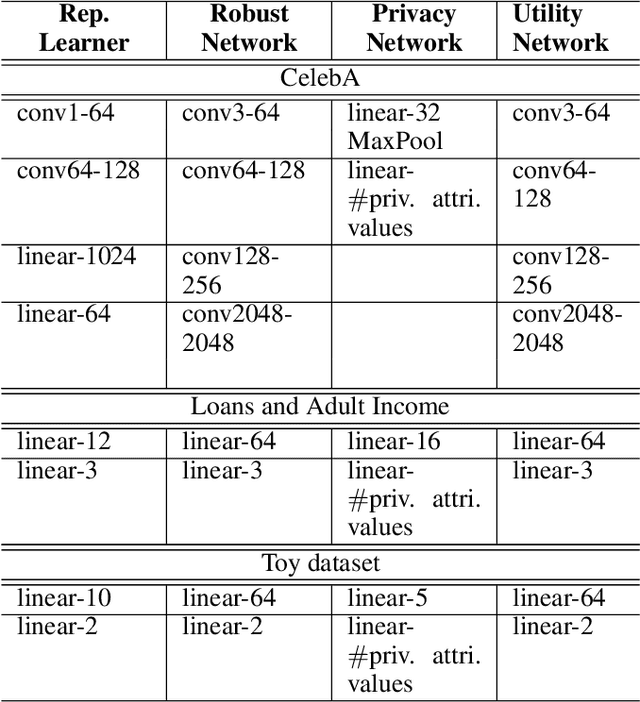
Machine learning models are vulnerable to both security attacks (e.g., adversarial examples) and privacy attacks (e.g., private attribute inference). We take the first step to mitigate both the security and privacy attacks, and maintain task utility as well. Particularly, we propose an information-theoretic framework to achieve the goals through the lens of representation learning, i.e., learning representations that are robust to both adversarial examples and attribute inference adversaries. We also derive novel theoretical results under our framework, e.g., the inherent trade-off between adversarial robustness/utility and attribute privacy, and guaranteed attribute privacy leakage against attribute inference adversaries.
Graph Neural Network Explanations are Fragile
Jun 05, 2024Explainable Graph Neural Network (GNN) has emerged recently to foster the trust of using GNNs. Existing GNN explainers are developed from various perspectives to enhance the explanation performance. We take the first step to study GNN explainers under adversarial attack--We found that an adversary slightly perturbing graph structure can ensure GNN model makes correct predictions, but the GNN explainer yields a drastically different explanation on the perturbed graph. Specifically, we first formulate the attack problem under a practical threat model (i.e., the adversary has limited knowledge about the GNN explainer and a restricted perturbation budget). We then design two methods (i.e., one is loss-based and the other is deduction-based) to realize the attack. We evaluate our attacks on various GNN explainers and the results show these explainers are fragile.