 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedTilt: Towards Multi-Level Fairness-Preserving and Robust Federated Learning
Mar 15, 2025Federated Learning (FL) is an emerging decentralized learning paradigm that can partly address the privacy concern that cannot be handled by traditional centralized and distributed learning. Further, to make FL practical, it is also necessary to consider constraints such as fairness and robustness. However, existing robust FL methods often produce unfair models, and existing fair FL methods only consider one-level (client) fairness and are not robust to persistent outliers (i.e., injected outliers into each training round) that are common in real-world FL settings. We propose \texttt{FedTilt}, a novel FL that can preserve multi-level fairness and be robust to outliers. In particular, we consider two common levels of fairness, i.e., \emph{client fairness} -- uniformity of performance across clients, and \emph{client data fairness} -- uniformity of performance across different classes of data within a client. \texttt{FedTilt} is inspired by the recently proposed tilted empirical risk minimization, which introduces tilt hyperparameters that can be flexibly tuned. Theoretically, we show how tuning tilt values can achieve the two-level fairness and mitigate the persistent outliers, and derive the convergence condition of \texttt{FedTilt} as well. Empirically, our evaluation results on a suite of realistic federated datasets in diverse settings show the effectiveness and flexibility of the \texttt{FedTilt} framework and the superiority to the state-of-the-arts.
Learning Robust and Privacy-Preserving Representations via Information Theory
Dec 15, 2024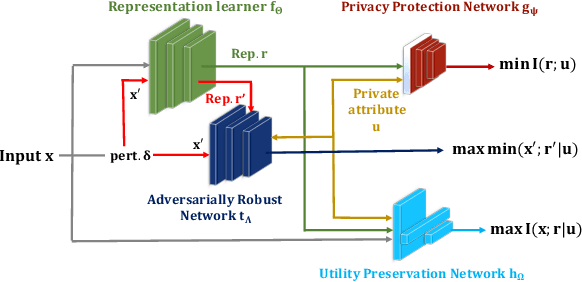
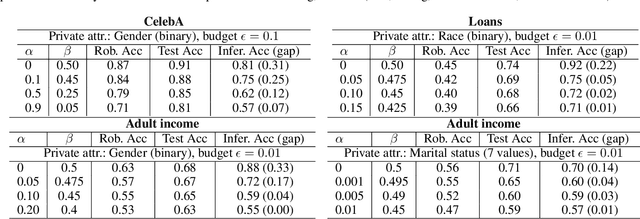
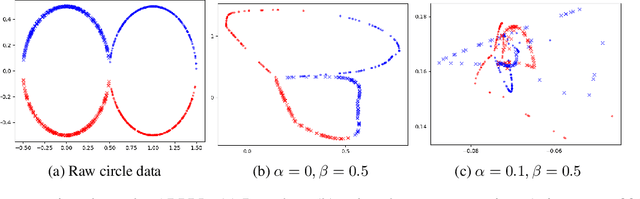
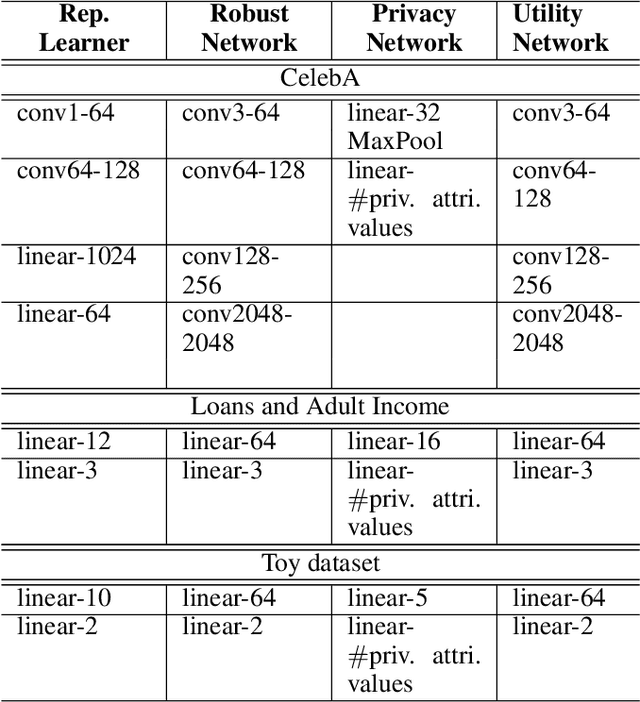
Machine learning models are vulnerable to both security attacks (e.g., adversarial examples) and privacy attacks (e.g., private attribute inference). We take the first step to mitigate both the security and privacy attacks, and maintain task utility as well. Particularly, we propose an information-theoretic framework to achieve the goals through the lens of representation learning, i.e., learning representations that are robust to both adversarial examples and attribute inference adversaries. We also derive novel theoretical results under our framework, e.g., the inherent trade-off between adversarial robustness/utility and attribute privacy, and guaranteed attribute privacy leakage against attribute inference adversaries.
Understanding Data Reconstruction Leakage in Federated Learning from a Theoretical Perspective
Aug 22, 2024Federated learning (FL) is an emerging collaborative learning paradigm that aims to protect data privacy. Unfortunately, recent works show FL algorithms are vulnerable to the serious data reconstruction attacks. However, existing works lack a theoretical foundation on to what extent the devices' data can be reconstructed and the effectiveness of these attacks cannot be compared fairly due to their unstable performance. To address this deficiency, we propose a theoretical framework to understand data reconstruction attacks to FL. Our framework involves bounding the data reconstruction error and an attack's error bound reflects its inherent attack effectiveness. Under the framework, we can theoretically compare the effectiveness of existing attacks. For instance, our results on multiple datasets validate that the iDLG attack inherently outperforms the DLG attack.
Inf2Guard: An Information-Theoretic Framework for Learning Privacy-Preserving Representations against Inference Attacks
Mar 04, 2024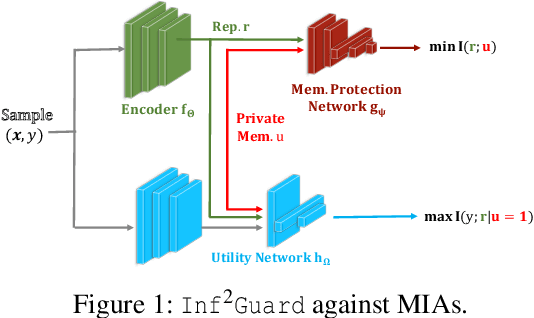
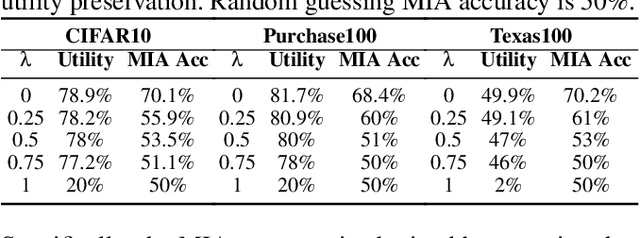
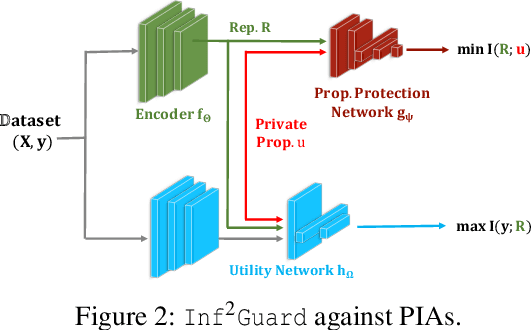
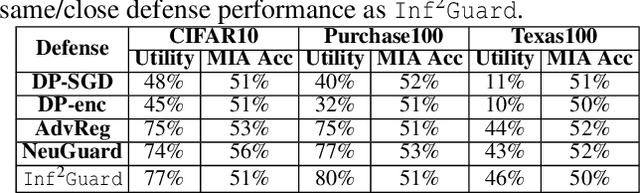
Machine learning (ML) is vulnerable to inference (e.g., membership inference, property inference, and data reconstruction) attacks that aim to infer the private information of training data or dataset. Existing defenses are only designed for one specific type of attack and sacrifice significant utility or are soon broken by adaptive attacks. We address these limitations by proposing an information-theoretic defense framework, called Inf2Guard, against the three major types of inference attacks. Our framework, inspired by the success of representation learning, posits that learning shared representations not only saves time/costs but also benefits numerous downstream tasks. Generally, Inf2Guard involves two mutual information objectives, for privacy protection and utility preservation, respectively. Inf2Guard exhibits many merits: it facilitates the design of customized objectives against the specific inference attack; it provides a general defense framework which can treat certain existing defenses as special cases; and importantly, it aids in deriving theoretical results, e.g., inherent utility-privacy tradeoff and guaranteed privacy leakage. Extensive evaluations validate the effectiveness of Inf2Guard for learning privacy-preserving representations against inference attacks and demonstrate the superiority over the baselines.