 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Robotic Assembly Control Reconfiguration Based on Transfer Reinforcement Learning for Objects with Different Geometric Features
Nov 04, 2022



Robotic force-based compliance control is a preferred approach to achieve high-precision assembly tasks. When the geometric features of assembly objects are asymmetric or irregular, reinforcement learning (RL) agents are gradually incorporated into the compliance controller to adapt to complex force-pose mapping which is hard to model analytically. Since force-pose mapping is strongly dependent on geometric features, a compliance controller is only optimal for current geometric features. To reduce the learning cost of assembly objects with different geometric features, this paper is devoted to answering how to reconfigure existing controllers for new assembly objects with different geometric features. In this paper, model-based parameters are first reconfigured based on the proposed Equivalent Theory of Compliance Law (ETCL). Then the RL agent is transferred based on the proposed Weighted Dimensional Policy Distillation (WDPD) method. The experiment results demonstrate that the control reconfiguration method costs less time and achieves better control performance, which confirms the validity of proposed methods.
Local Connection Reinforcement Learning Method for Efficient Control of Robotic Peg-in-Hole Assembly
Oct 24, 2022



Traditional control methods of robotic peg-in-hole assembly rely on complex contact state analysis. Reinforcement learning (RL) is gradually becoming a preferred method of controlling robotic peg-in-hole assembly tasks. However, the training process of RL is quite time-consuming because RL methods are always globally connected, which means all state components are assumed to be the input of policies for all action components, thus increasing action space and state space to be explored. In this paper, we first define continuous space serialized Shapley value (CS3) and construct a connection graph to clarify the correlativity of action components on state components. Then we propose a local connection reinforcement learning (LCRL) method based on the connection graph, which eliminates the influence of irrelevant state components on the selection of action components. The simulation and experiment results demonstrate that the control strategy obtained through LCRL method improves the stability and rapidity of the control process. LCRL method will enhance the data-efficiency and increase the final reward of the training process.
Progressive extension of reinforcement learning action dimension for asymmetric assembly tasks
Apr 06, 2021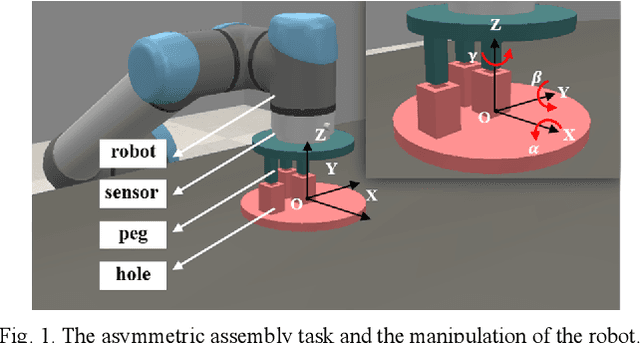
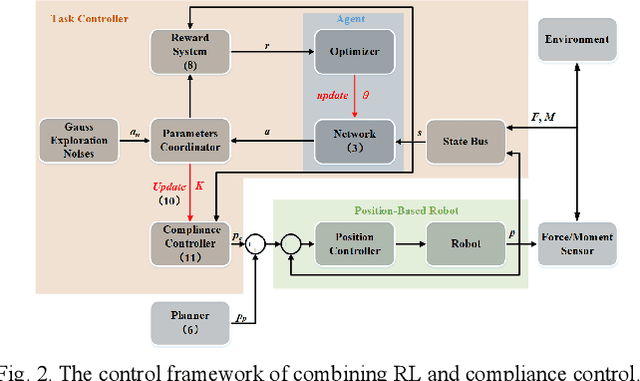
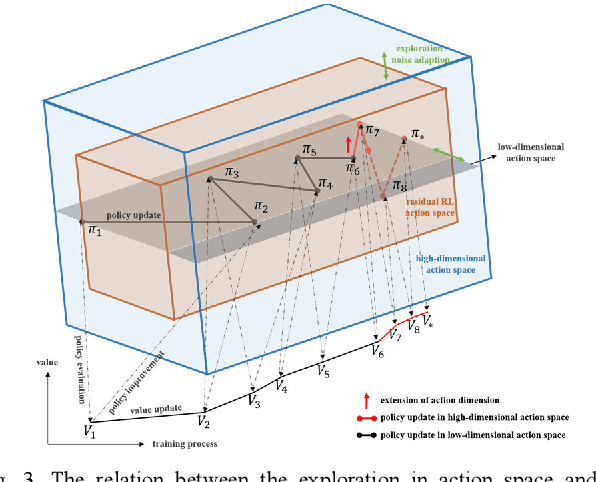
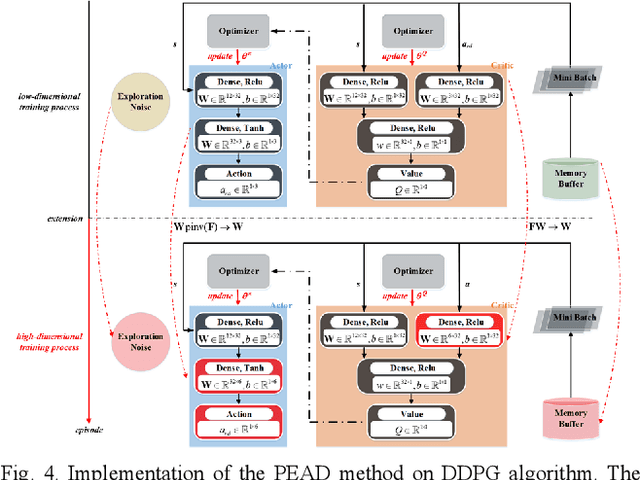
Reinforcement learning (RL) is always the preferred embodiment to construct the control strategy of complex tasks, like asymmetric assembly tasks. However, the convergence speed of reinforcement learning severely restricts its practical application. In this paper, the convergence is first accelerated by combining RL and compliance control. Then a completely innovative progressive extension of action dimension (PEAD) mechanism is proposed to optimize the convergence of RL algorithms. The PEAD method is verified in DDPG and PPO. The results demonstrate the PEAD method will enhance the data-efficiency and time-efficiency of RL algorithms as well as increase the stable reward, which provides more potential for the application of RL.