 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeII-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
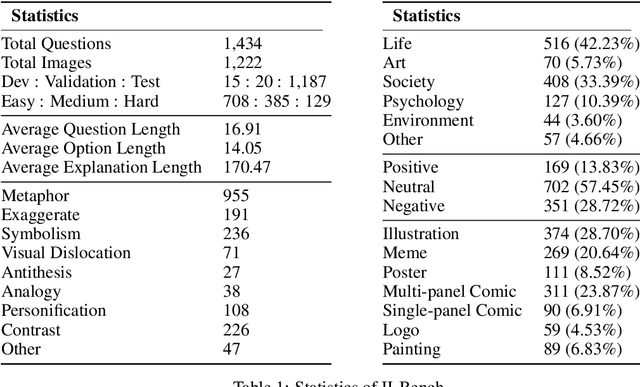
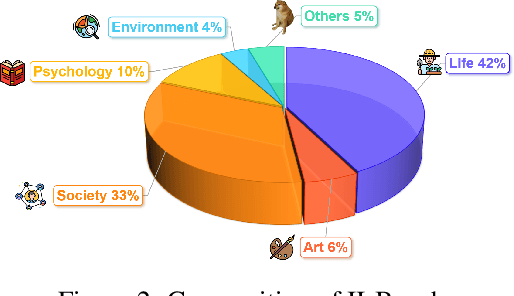
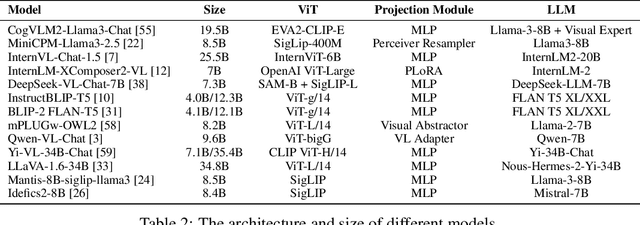
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
E-EVAL: A Comprehensive Chinese K-12 Education Evaluation Benchmark for Large Language Models
Jan 29, 2024



With the accelerating development of Large Language Models (LLMs), many LLMs are beginning to be used in the Chinese K-12 education domain. The integration of LLMs and education is getting closer and closer, however, there is currently no benchmark for evaluating LLMs that focuses on the Chinese K-12 education domain. Therefore, there is an urgent need for a comprehensive natural language processing benchmark to accurately assess the capabilities of various LLMs in the Chinese K-12 education domain. To address this, we introduce the E-EVAL, the first comprehensive evaluation benchmark specifically designed for the Chinese K-12 education field. The E-EVAL consists of 4,351 multiple-choice questions at the primary, middle, and high school levels across a wide range of subjects, including Chinese, English, Politics, History, Ethics, Physics, Chemistry, Mathematics, and Geography. We conducted a comprehensive evaluation of E-EVAL on advanced LLMs, including both English-dominant and Chinese-dominant models. Findings show that Chinese-dominant models perform well compared to English-dominant models, with many scoring even above the GPT 4.0. However, almost all models perform poorly in complex subjects such as mathematics. We also found that most Chinese-dominant LLMs did not achieve higher scores at the primary school level compared to the middle school level. We observe that the mastery of higher-order knowledge by the model does not necessarily imply the mastery of lower-order knowledge as well. Additionally, the experimental results indicate that the Chain of Thought (CoT) technique is effective only for the challenging science subjects, while Few-shot prompting is more beneficial for liberal arts subjects. With E-EVAL, we aim to analyze the strengths and limitations of LLMs in educational applications, and to contribute to the progress and development of Chinese K-12 education and LLMs.