 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Nash Equilibrial Hamiltonian for Two-Player Collision-Avoiding Interactions
Mar 10, 2025We consider the problem of learning Nash equilibrial policies for two-player risk-sensitive collision-avoiding interactions. Solving the Hamilton-Jacobi-Isaacs equations of such general-sum differential games in real time is an open challenge due to the discontinuity of equilibrium values on the state space. A common solution is to learn a neural network that approximates the equilibrium Hamiltonian for given system states and actions. The learning, however, is usually supervised and requires a large amount of sample equilibrium policies from different initial states in order to mitigate the risks of collisions. This paper claims two contributions towards more data-efficient learning of equilibrium policies: First, instead of computing Hamiltonian through a value network, we show that the equilibrium co-states have simple structures when collision avoidance dominates the agents' loss functions and system dynamics is linear, and therefore are more data-efficient to learn. Second, we introduce theory-driven active learning to guide data sampling, where the acquisition function measures the compliance of the predicted co-states to Pontryagin's Maximum Principle. On an uncontrolled intersection case, the proposed method leads to more generalizable approximation of the equilibrium policies, and in turn, lower collision probabilities, than the state-of-the-art under the same data acquisition budget.
When Shall I Be Empathetic? The Utility of Empathetic Parameter Estimation in Multi-Agent Interactions
Nov 03, 2020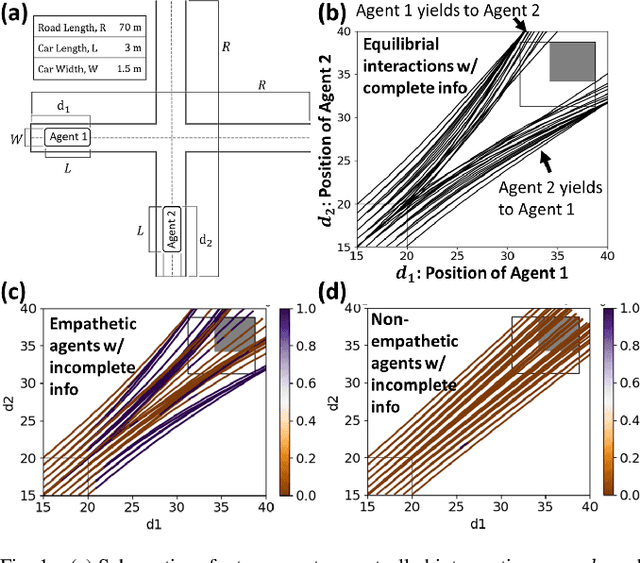
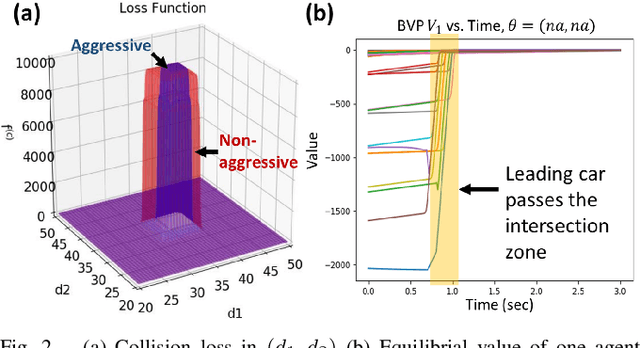
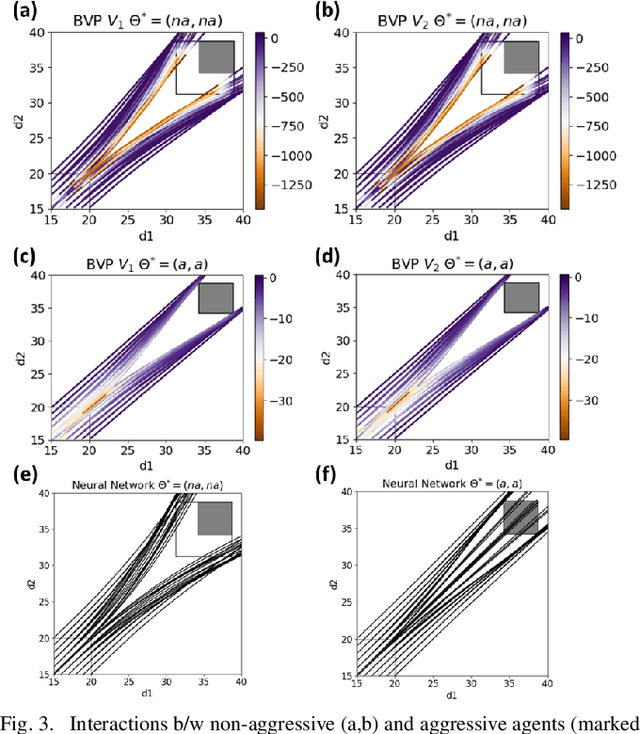
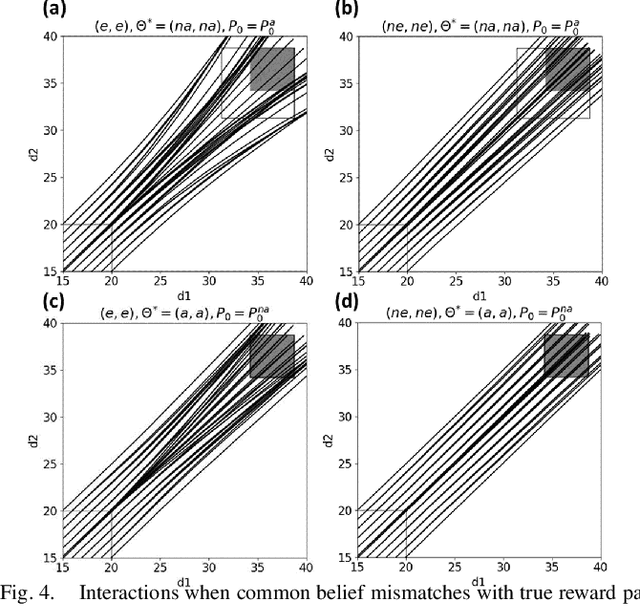
Human-robot interactions (HRI) can be modeled as dynamic or differential games with incomplete information, where each agent holds private reward parameters. Due to the open challenge in finding perfect Bayesian equilibria of such games, existing studies often consider approximated solutions composed of parameter estimation and motion planning steps, in order to decouple the belief and physical dynamics. In parameter estimation, current approaches often assume that the reward parameters of the robot are known by the humans. We argue that by falsely conditioning on this assumption, the robot performs non-empathetic estimation of the humans' parameters, leading to undesirable values even in the simplest interactions. We test this argument by studying a two-vehicle uncontrolled intersection case with short reaction time. Results show that when both agents are unknowingly aggressive (or non-aggressive), empathy leads to more effective parameter estimation and higher reward values, suggesting that empathy is necessary when the true parameters of agents mismatch with their common belief. The proposed estimation and planning algorithms are therefore more robust than the existing approaches, by fully acknowledging the nature of information asymmetry in HRI. Lastly, we introduce value approximation techniques for real-time execution of the proposed algorithms.