 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Unified Framework for Post-Training LLMs Without Verifiable Rewards
Jan 08, 2026Current techniques for post-training Large Language Models (LLMs) rely either on costly human supervision or on external verifiers to boost performance on tasks such as mathematical reasoning and code generation. However, as LLMs improve their problem-solving, any further improvement will potentially require high-quality solutions to difficult problems that are not available to humans. As a result, learning from unlabeled data is becoming increasingly attractive in the research community. Existing methods extract learning signal from a model's consistency, either by majority voting or by converting the model's internal confidence into reward. Although internal consistency metric such as entropy or self-certainty require no human intervention, as we show in this work, these are unreliable signals for large-scale and long-term training. To address the unreliability, we propose PRISM, a unified training framework that uses a Process Reward Model (PRM) to guide learning alongside model's internal confidence in the absence of ground-truth labels. We show that effectively combining PRM with self-certainty can lead to both stable training and better test-time performance, and also keep the model's internal confidence in check.
Parametric Value Approximation for General-sum Differential Games with State Constraints
Mar 10, 2025General-sum differential games can approximate values solved by Hamilton-Jacobi-Isaacs (HJI) equations for efficient inference when information is incomplete. However, solving such games through conventional methods encounters the curse of dimensionality (CoD). Physics-informed neural networks (PINNs) offer a scalable approach to alleviate the CoD and approximate values, but there exist convergence issues for value approximations through vanilla PINNs when state constraints lead to values with large Lipschitz constants, particularly in safety-critical applications. In addition to addressing CoD, it is necessary to learn a generalizable value across a parametric space of games, rather than training multiple ones for each specific player-type configuration. To overcome these challenges, we propose a Hybrid Neural Operator (HNO), which is an operator that can map parameter functions for games to value functions. HNO leverages informative supervised data and samples PDE-driven data across entire spatial-temporal space for model refinement. We evaluate HNO on 9D and 13D scenarios with nonlinear dynamics and state constraints, comparing it against a Supervised Neural Operator (a variant of DeepONet). Under the same computational budget and training data, HNO outperforms SNO for safety performance. This work provides a step toward scalable and generalizable value function approximation, enabling real-time inference for complex human-robot or multi-agent interactions.
State-Constrained Zero-Sum Differential Games with One-Sided Information
Mar 05, 2024



We study zero-sum differential games with state constraints and one-sided information, where the informed player (Player 1) has a categorical payoff type unknown to the uninformed player (Player 2). The goal of Player 1 is to minimize his payoff without violating the constraints, while that of Player 2 is to either violate the state constraints, or otherwise, to maximize the payoff. One example of the game is a man-to-man matchup in football. Without state constraints, Cardaliaguet (2007) showed that the value of such a game exists and is convex to the common belief of players. Our theoretical contribution is an extension of this result to differential games with state constraints and the derivation of the primal and dual subdynamic principles necessary for computing the behavioral strategies. Compared with existing works on imperfect-information dynamic games that focus on scalability and generalization, our focus is instead on revealing the mechanism of belief manipulation behaviors resulted from information asymmetry and state constraints. We use a simplified football game to demonstrate the utility of this work, where we reveal player positions and belief states in which the attacker should (or should not) play specific random fake moves to take advantage of information asymmetry, and compute how the defender should respond.
Pontryagin Neural Operator for Solving Parametric General-Sum Differential Games
Jan 03, 2024The values of two-player general-sum differential games are viscosity solutions to Hamilton-Jacobi-Isaacs (HJI) equations. Value and policy approximations for such games suffer from the curse of dimensionality (CoD). Alleviating CoD through physics-informed neural networks (PINN) encounters convergence issues when value discontinuity is present due to state constraints. On top of these challenges, it is often necessary to learn generalizable values and policies across a parametric space of games, e.g., for game parameter inference when information is incomplete. To address these challenges, we propose in this paper a Pontryagin-mode neural operator that outperforms existing state-of-the-art (SOTA) on safety performance across games with parametric state constraints. Our key contribution is the introduction of a costate loss defined on the discrepancy between forward and backward costate rollouts, which are computationally cheap. We show that the discontinuity of costate dynamics (in the presence of state constraints) effectively enables the learning of discontinuous values, without requiring manually supervised data as suggested by the current SOTA. More importantly, we show that the close relationship between costates and policies makes the former critical in learning feedback control policies with generalizable safety performance.
Value Approximation for Two-Player General-Sum Differential Games with State Constraints
Nov 28, 2023Solving Hamilton-Jacobi-Isaacs (HJI) PDEs enables equilibrial feedback control in two-player differential games, yet faces the curse of dimensionality (CoD). While physics-informed machine learning has been adopted to address CoD in solving PDEs, this method falls short in learning discontinuous solutions due to its sampling nature, leading to poor safety performance of the resulting controllers in robotics applications where values are discontinuous due to state or other temporal logic constraints. In this study, we explore three potential solutions to this problem: (1) a hybrid learning method that uses both equilibrium demonstrations and the HJI PDE, (2) a value-hardening method where a sequence of HJIs are solved with increasing Lipschitz constant on the constraint violation penalty, and (3) the epigraphical technique that lifts the value to a higher dimensional auxiliary state space where the value becomes continuous. Evaluations through 5D and 9D vehicle simulations and 13D drone simulations reveal that the hybrid method outperforms others in terms of generalization and safety performance.
Solving Two-Player General-Sum Games Between Swarms
Oct 02, 2023Hamilton-Jacobi-Isaacs (HJI) PDEs are the governing equations for the two-player general-sum games. Unlike Reinforcement Learning (RL) methods, which are data-intensive methods for learning value function, learning HJ PDEs provide a guaranteed convergence to the Nash Equilibrium value of the game when it exists. However, a caveat is that solving HJ PDEs becomes intractable when the state dimension increases. To circumvent the curse of dimensionality (CoD), physics-informed machine learning methods with supervision can be used and have been shown to be effective in generating equilibrial policies in two-player general-sum games. In this work, we extend the existing work on agent-level two-player games to a two-player swarm-level game, where two sub-swarms play a general-sum game. We consider the \textit{Kolmogorov forward equation} as the dynamic model for the evolution of the densities of the swarms. Results show that policies generated from the physics-informed neural network (PINN) result in a higher payoff than a Nash Double Deep Q-Network (Nash DDQN) agent and have comparable performance with numerical solvers.
Approximating Discontinuous Nash Equilibrial Values of Two-Player General-Sum Differential Games
Jul 05, 2022



Finding Nash equilibrial policies for two-player differential games requires solving Hamilton-Jacobi-Isaacs PDEs. Recent studies achieved success in circumventing the curse of dimensionality in solving such PDEs with underlying applications to human-robot interactions (HRI), by adopting self-supervised (physics-informed) neural networks as universal value approximators. This paper extends from previous SOTA on zero-sum games with continuous values to general-sum games with discontinuous values, where the discontinuity is caused by that of the players' losses. We show that due to its lack of convergence proof and generalization analysis on discontinuous losses, the existing self-supervised learning technique fails to generalize and raises safety concerns in an autonomous driving application. Our solution is to first pre-train the value network on supervised Nash equilibria, and then refine it by minimizing a loss that combines the supervised data with the PDE and boundary conditions. Importantly, the demonstrated advantage of the proposed learning method against purely supervised and self-supervised approaches requires careful choice of the neural activation function: Among $\texttt{relu}$, $\texttt{sin}$, and $\texttt{tanh}$, we show that $\texttt{tanh}$ is the only choice that achieves optimal generalization and safety performance. Our conjecture is that $\texttt{tanh}$ (similar to $\texttt{sin}$) allows continuity of value and its gradient, which is sufficient for the convergence of learning, and at the same time is expressive enough (similar to $\texttt{relu}$) at approximating discontinuous value landscapes. Lastly, we apply our method to approximating control policies for an incomplete-information interaction and demonstrate its contribution to safe interactions.
Lane Change Decision-Making through Deep Reinforcement Learning
Dec 24, 2021

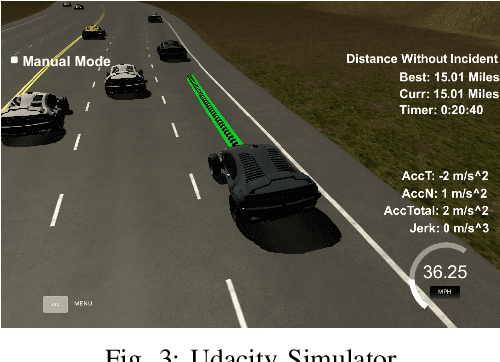
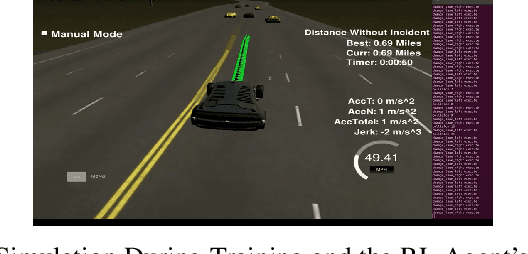
Due to the complexity and volatility of the traffic environment, decision-making in autonomous driving is a significantly hard problem. In this project, we use a Deep Q-Network, along with rule-based constraints to make lane-changing decision. A safe and efficient lane change behavior may be obtained by combining high-level lateral decision-making with low-level rule-based trajectory monitoring. The agent is anticipated to perform appropriate lane-change maneuvers in a real-world-like udacity simulator after training it for a total of 100 episodes. The results shows that the rule-based DQN performs better than the DQN method. The rule-based DQN achieves a safety rate of 0.8 and average speed of 47 MPH