 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVCOD:A Large-Scale Multi-Scene Dataset for Video Camouflage Object Detection
Feb 19, 2025

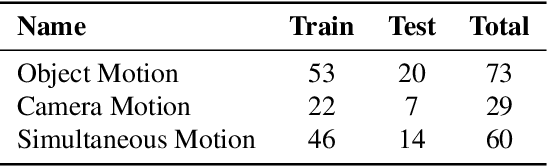
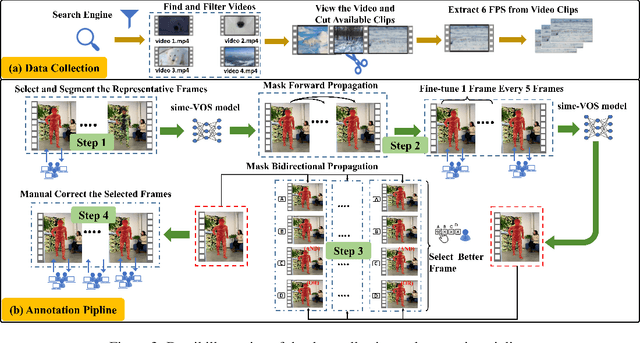
Video Camouflaged Object Detection (VCOD) is a challenging task which aims to identify objects that seamlessly concealed within the background in videos. The dynamic properties of video enable detection of camouflaged objects through motion cues or varied perspectives. Previous VCOD datasets primarily contain animal objects, limiting the scope of research to wildlife scenarios. However, the applications of VCOD extend beyond wildlife and have significant implications in security, art, and medical fields. Addressing this problem, we construct a new large-scale multi-domain VCOD dataset MSVCOD. To achieve high-quality annotations, we design a semi-automatic iterative annotation pipeline that reduces costs while maintaining annotation accuracy. Our MSVCOD is the largest VCOD dataset to date, introducing multiple object categories including human, animal, medical, and vehicle objects for the first time, while also expanding background diversity across various environments. This expanded scope increases the practical applicability of the VCOD task in camouflaged object detection. Alongside this dataset, we introduce a one-steam video camouflage object detection model that performs both feature extraction and information fusion without additional motion feature fusion modules. Our framework achieves state-of-the-art results on the existing VCOD animal dataset and the proposed MSVCOD. The dataset and code will be made publicly available.