 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Human Cognitive Styles with Language: Towards an Experimental Evaluation Paradigm
Feb 18, 2025



While NLP models often seek to capture cognitive states via language, the validity of predicted states is determined by comparing them to annotations created without access the cognitive states of the authors. In behavioral sciences, cognitive states are instead measured via experiments. Here, we introduce an experiment-based framework for evaluating language-based cognitive style models against human behavior. We explore the phenomenon of decision making, and its relationship to the linguistic style of an individual talking about a recent decision they made. The participants then follow a classical decision-making experiment that captures their cognitive style, determined by how preferences change during a decision exercise. We find that language features, intended to capture cognitive style, can predict participants' decision style with moderate-to-high accuracy (AUC ~ 0.8), demonstrating that cognitive style can be partly captured and revealed by discourse patterns.
Transfer and Active Learning for Dissonance Detection: Addressing the Rare-Class Challenge
May 05, 2023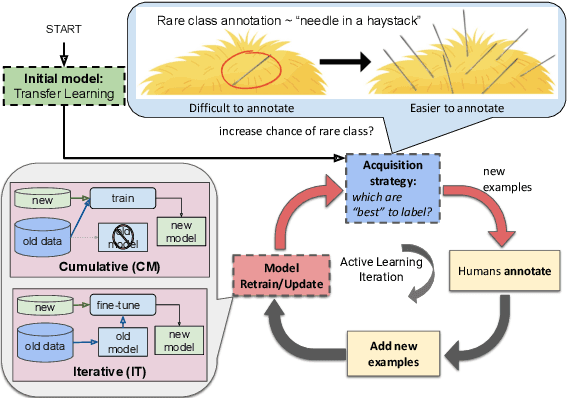
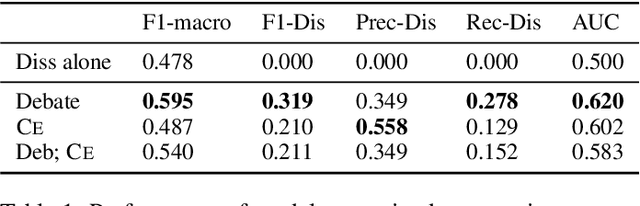
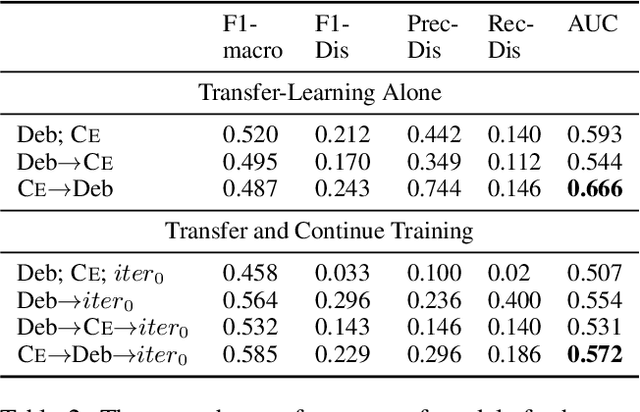
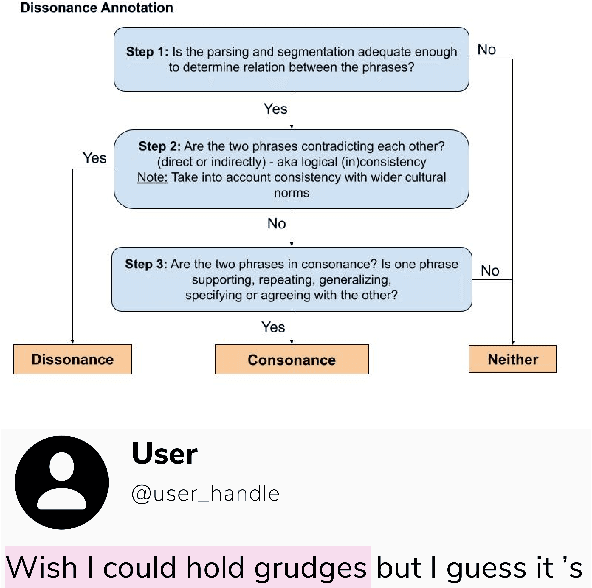
While transformer-based systems have enabled greater accuracies with fewer training examples, data acquisition obstacles still persist for rare-class tasks -- when the class label is very infrequent (e.g. < 5% of samples). Active learning has in general been proposed to alleviate such challenges, but choice of selection strategy, the criteria by which rare-class examples are chosen, has not been systematically evaluated. Further, transformers enable iterative transfer-learning approaches. We propose and investigate transfer- and active learning solutions to the rare class problem of dissonance detection through utilizing models trained on closely related tasks and the evaluation of acquisition strategies, including a proposed probability-of-rare-class (PRC) approach. We perform these experiments for a specific rare class problem: collecting language samples of cognitive dissonance from social media. We find that PRC is a simple and effective strategy to guide annotations and ultimately improve model accuracy while transfer-learning in a specific order can improve the cold-start performance of the learner but does not benefit iterations of active learning.