 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Orchestration of Multi-LLM Agents for Cost-Aware Sequential Decision-Making
Jan 04, 2026Large language models (LLMs) are increasingly deployed as autonomous decision agents in settings with asymmetric error costs: hiring (missed talent vs wasted interviews), medical triage (missed emergencies vs unnecessary escalation), and fraud detection (approved fraud vs declined legitimate payments). The dominant design queries a single LLM for a posterior over states, thresholds "confidence," and acts; we prove this is inadequate for sequential decisions with costs. We propose a Bayesian, cost-aware multi-LLM orchestration framework that treats LLMs as approximate likelihood models rather than classifiers. For each candidate state, we elicit likelihoods via contrastive prompting, aggregate across diverse models with robust statistics, and update beliefs with Bayes rule under explicit priors as new evidence arrives. This enables coherent belief updating, expected-cost action selection, principled information gathering via value of information, and fairness gains via ensemble bias mitigation. In resume screening with costs of 40000 USD per missed hire, 2500 USD per interview, and 150 USD per phone screen, experiments on 1000 resumes using five LLMs (GPT-4o, Claude 4.5 Sonnet, Gemini Pro, Grok, DeepSeek) reduce total cost by 294000 USD (34 percent) versus the best single-LLM baseline and improve demographic parity by 45 percent (max group gap 22 to 5 percentage points). Ablations attribute 51 percent of savings to multi-LLM aggregation, 43 percent to sequential updating, and 20 percent to disagreement-triggered information gathering, consistent with the theoretical benefits of correct probabilistic foundations.
How Is Generative AI Used for Persona Development?: A Systematic Review of 52 Research Articles
Apr 07, 2025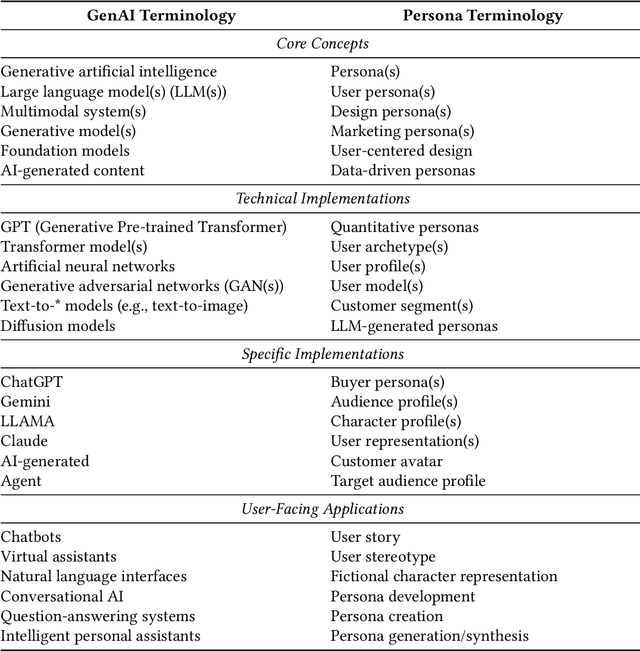

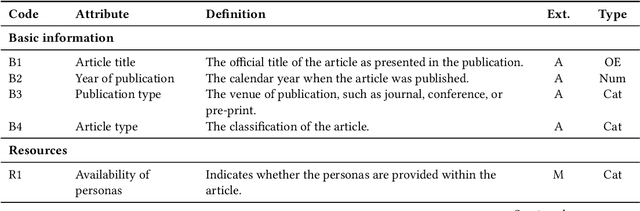
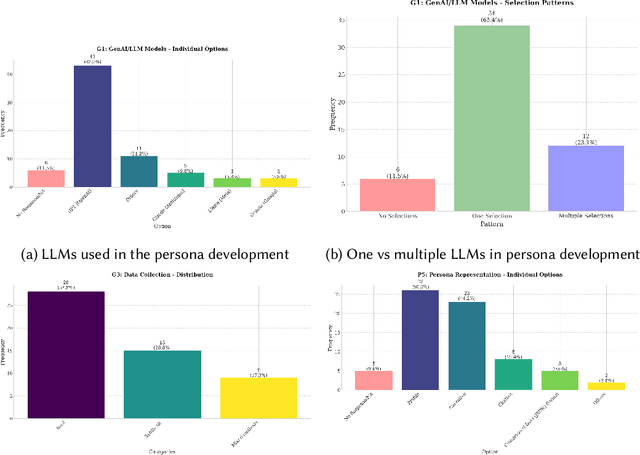
Although Generative AI (GenAI) has the potential for persona development, many challenges must be addressed. This research systematically reviews 52 articles from 2022-2024, with important findings. First, closed commercial models are frequently used in persona development, creating a monoculture Second, GenAI is used in various stages of persona development (data collection, segmentation, enrichment, and evaluation). Third, similar to other quantitative persona development techniques, there are major gaps in persona evaluation for AI generated personas. Fourth, human-AI collaboration models are underdeveloped, despite human oversight being crucial for maintaining ethical standards. These findings imply that realizing the full potential of AI-generated personas will require substantial efforts across academia and industry. To that end, we provide a list of research avenues to inspire future work.