 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-aware Transformer for Time series Forecasting
Oct 02, 2023Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
SA-GAN: Structure-Aware Generative Adversarial Network for Shape-Preserving Synthetic CT Generation
May 14, 2021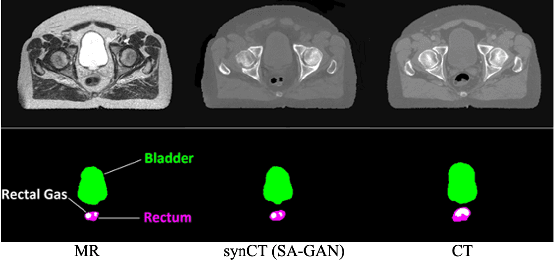

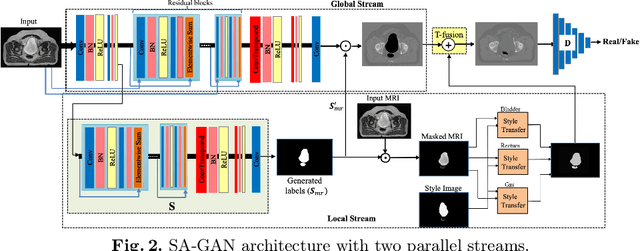
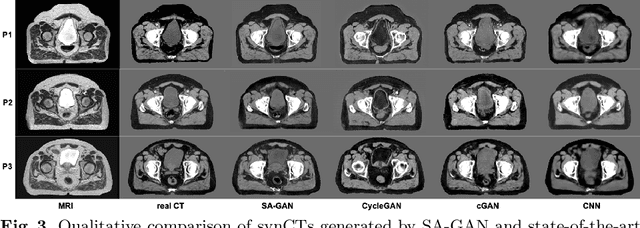
In medical image synthesis, model training could be challenging due to the inconsistencies between images of different modalities even with the same patient, typically caused by internal status/tissue changes as different modalities are usually obtained at a different time. This paper proposes a novel deep learning method, Structure-aware Generative Adversarial Network (SA-GAN), that preserves the shapes and locations of in-consistent structures when generating medical images. SA-GAN is employed to generate synthetic computed tomography (synCT) images from magnetic resonance imaging (MRI) with two parallel streams: the global stream translates the input from the MRI to the CT domain while the local stream automatically segments the inconsistent organs, maintains their locations and shapes in MRI, and translates the organ intensities to CT. Through extensive experiments on a pelvic dataset, we demonstrate that SA-GAN provides clinically acceptable accuracy on both synCTs and organ segmentation and supports MR-only treatment planning in disease sites with internal organ status changes.
FREA-Unet: Frequency-aware U-net for Modality Transfer
Dec 31, 2020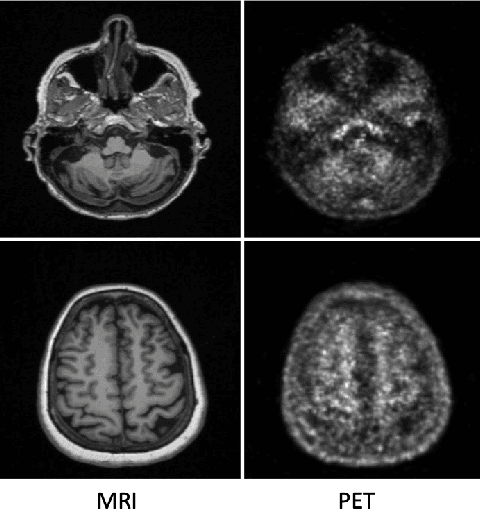
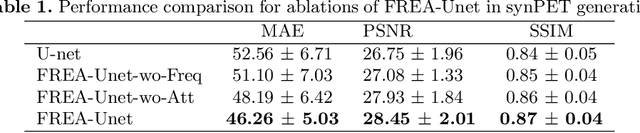
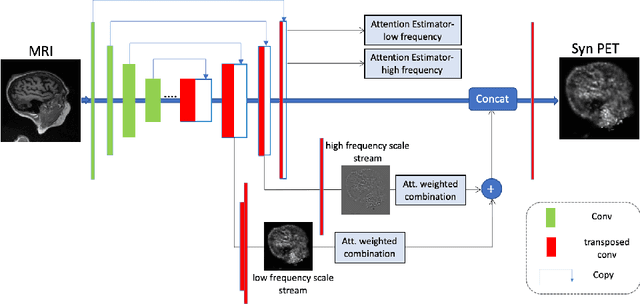

While Positron emission tomography (PET) imaging has been widely used in diagnosis of number of diseases, it has costly acquisition process which involves radiation exposure to patients. However, magnetic resonance imaging (MRI) is a safer imaging modality that does not involve patient's exposure to radiation. Therefore, a need exists for an efficient and automated PET image generation from MRI data. In this paper, we propose a new frequency-aware attention U-net for generating synthetic PET images. Specifically, we incorporate attention mechanism into different U-net layers responsible for estimating low/high frequency scales of the image. Our frequency-aware attention Unet computes the attention scores for feature maps in low/high frequency layers and use it to help the model focus more on the most important regions, leading to more realistic output images. Experimental results on 30 subjects from Alzheimers Disease Neuroimaging Initiative (ADNI) dataset demonstrate good performance of the proposed model in PET image synthesis that achieved superior performance, both qualitative and quantitative, over current state-of-the-arts.
Attention-Guided Generative Adversarial Network to Address Atypical Anatomy in Modality Transfer
Jun 27, 2020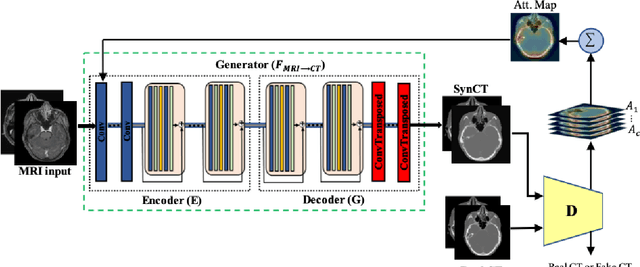
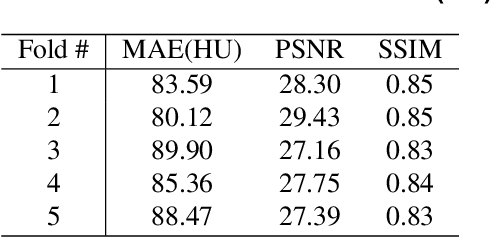
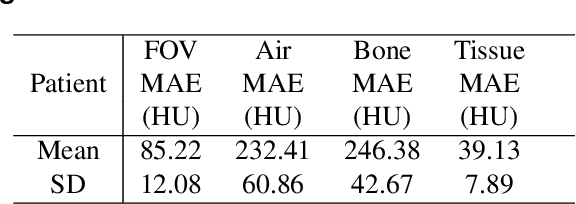
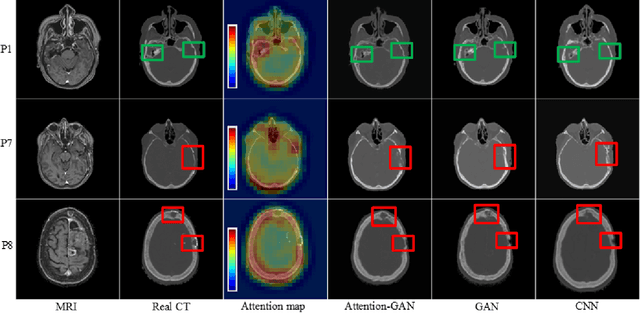
Recently, interest in MR-only treatment planning using synthetic CTs (synCTs) has grown rapidly in radiation therapy. However, developing class solutions for medical images that contain atypical anatomy remains a major limitation. In this paper, we propose a novel spatial attention-guided generative adversarial network (attention-GAN) model to generate accurate synCTs using T1-weighted MRI images as the input to address atypical anatomy. Experimental results on fifteen brain cancer patients show that attention-GAN outperformed existing synCT models and achieved an average MAE of 85.22$\pm$12.08, 232.41$\pm$60.86, 246.38$\pm$42.67 Hounsfield units between synCT and CT-SIM across the entire head, bone and air regions, respectively. Qualitative analysis shows that attention-GAN has the ability to use spatially focused areas to better handle outliers, areas with complex anatomy or post-surgical regions, and thus offer strong potential for supporting near real-time MR-only treatment planning.
SPA-GAN: Spatial Attention GAN for Image-to-Image Translation
Aug 19, 2019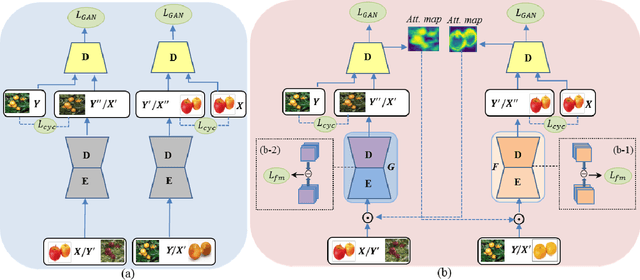



Image-to-image translation is to learn a mapping between images from a source domain and images from a target domain. In this paper, we introduce the attention mechanism directly to the generative adversarial network (GAN) architecture and propose a novel spatial attention GAN model (SPA-GAN) for image-to-image translation tasks. SPA-GAN computes the attention in its discriminator and use it to help the generator focus more on the most discriminative regions between the source and target domains, leading to more realistic output images. We also find it helpful to introduce an additional feature map loss in SPA-GAN training to preserve domain specific features during translation. Compared with existing attention-guided GAN models, SPA-GAN is a lightweight model that does not need additional attention networks or supervision. Qualitative and quantitative comparison against state-of-the-art methods on benchmark datasets demonstrates the superior performance of SPA-GAN.