 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Semantically Difficult Samples to Improve Text Classification
Feb 13, 2023
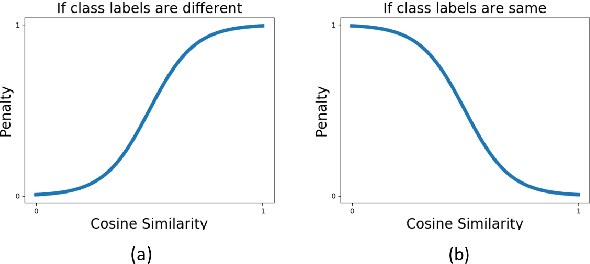
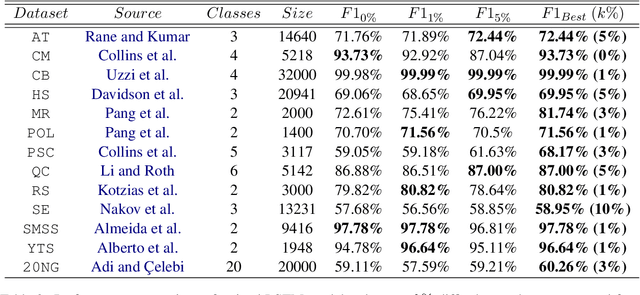

In this paper, we investigate the effect of addressing difficult samples from a given text dataset on the downstream text classification task. We define difficult samples as being non-obvious cases for text classification by analysing them in the semantic embedding space; specifically - (i) semantically similar samples that belong to different classes and (ii) semantically dissimilar samples that belong to the same class. We propose a penalty function to measure the overall difficulty score of every sample in the dataset. We conduct exhaustive experiments on 13 standard datasets to show a consistent improvement of up to 9% and discuss qualitative results to show effectiveness of our approach in identifying difficult samples for a text classification model.
Towards a Multi-modal, Multi-task Learning based Pre-training Framework for Document Representation Learning
Sep 30, 2020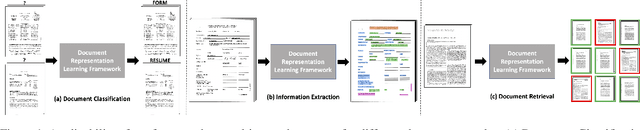

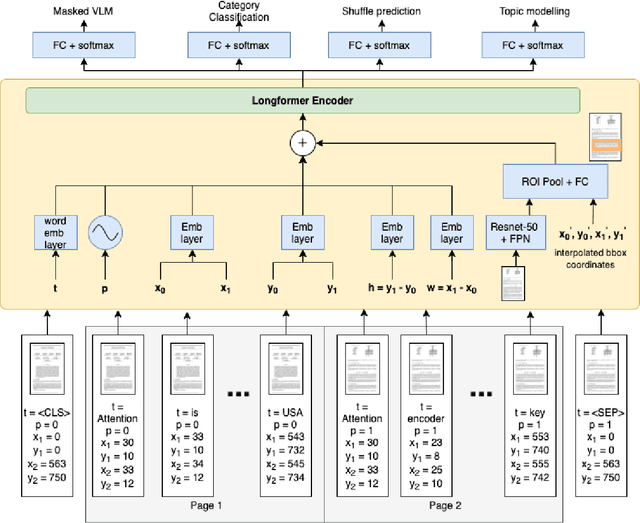

In this paper, we propose a multi-task learning-based framework that utilizes a combination of self-supervised and supervised pre-training tasks to learn a generic document representation. We design the network architecture and the pre-training tasks to incorporate the multi-modal document information across text, layout, and image dimensions and allow the network to work with multi-page documents. We showcase the applicability of our pre-training framework on a variety of different real-world document tasks such as document classification, document information extraction, and document retrieval. We conduct exhaustive experiments to compare performance against different ablations of our framework and state-of-the-art baselines. We discuss the current limitations and next steps for our work.
Small, Sparse, but Substantial: Techniques for Segmenting Small Agricultural Fields Using Sparse Ground Data
May 05, 2020

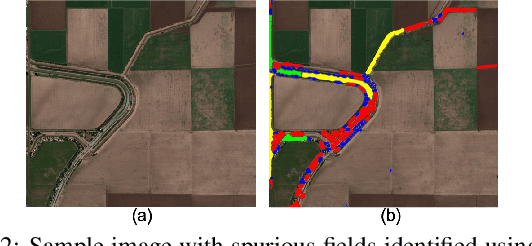

The recent thrust on digital agriculture (DA) has renewed significant research interest in the automated delineation of agricultural fields. Most prior work addressing this problem have focused on detecting medium to large fields, while there is strong evidence that around 40\% of the fields world-wide and 70% of the fields in Asia and Africa are small. The lack of adequate labeled images for small fields, huge variations in their color, texture, and shape, and faint boundary lines separating them make it difficult to develop an end-to-end learning model for detecting such fields. Hence, in this paper, we present a multi-stage approach that uses a combination of machine learning and image processing techniques. In the first stage, we leverage state-of-the-art edge detection algorithms such as holistically-nested edge detection (HED) to extract first-level contours and polygons. In the second stage, we propose image-processing techniques to identify polygons that are non-fields, over-segmentations, or noise and eliminate them. The next stage tackles under-segmentations using a combination of a novel ``cut-point'' based technique and localized second-level edge detection to obtain individual parcels. Since a few small, non-cropped but vegetated or constructed pockets can be interspersed in areas that are predominantly croplands, in the final stage, we train a classifier for identifying each parcel from the previous stage as an agricultural field or not. In an evaluation using high-resolution imagery, we show that our approach has a high F-Score of 0.84 in areas with large fields and reasonable accuracy with an F-Score of 0.73 in areas with small fields, which is encouraging.