 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERTIFAI: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models
Paper and Code
May 20, 2019


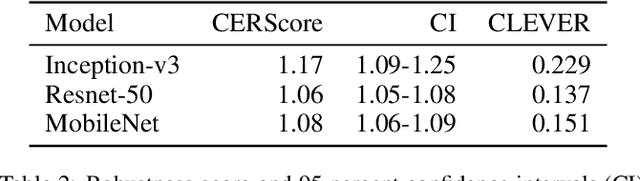
As artificial intelligence plays an increasingly important role in our society, there are ethical and moral obligations for both businesses and researchers to ensure that their machine learning models are designed, deployed, and maintained responsibly. These models need to be rigorously audited for fairness, robustness, transparency, and interpretability. A variety of methods have been developed that focus on these issues in isolation, however, managing these methods in conjunction with model development can be cumbersome and timeconsuming. In this paper, we introduce a unified and model-agnostic approach to address these issues: Counterfactual Explanations for Robustness, Transparency, Interpretability, and Fairness of Artificial Intelligence models (CERTIFAI). Unlike previous methods in this domain, CERTIFAI is a general tool that can be applied to any black-box model and any type of input data. Given a model and an input instance, CERTIFAI uses a custom genetic algorithm to generate counterfactuals: instances close to the input that change the prediction of the model. We demonstrate how these counterfactuals can be used to examine issues of robustness, interpretability, transparency, and fairness. Additionally, we introduce CERScore, the first black-box model robustness score that performs comparably to methods that have access to model internals.