 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASTER-CE: Fast, Sparse, Transparent, and Robust Counterfactual Explanations
Oct 12, 2022
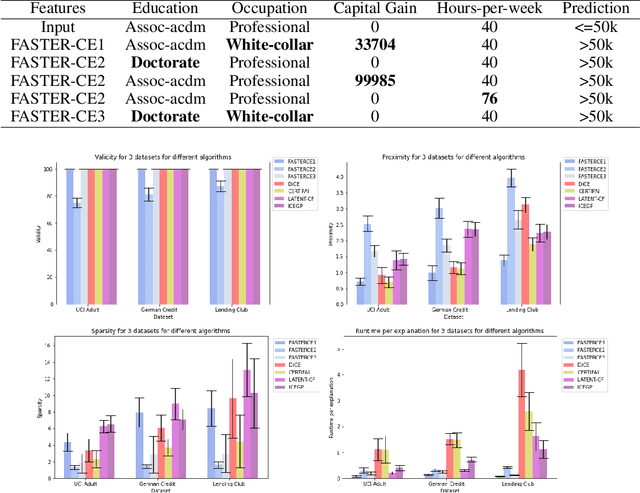


Counterfactual explanations have substantially increased in popularity in the past few years as a useful human-centric way of understanding individual black-box model predictions. While several properties desired of high-quality counterfactuals have been identified in the literature, three crucial concerns: the speed of explanation generation, robustness/sensitivity and succinctness of explanations (sparsity) have been relatively unexplored. In this paper, we present FASTER-CE: a novel set of algorithms to generate fast, sparse, and robust counterfactual explanations. The key idea is to efficiently find promising search directions for counterfactuals in a latent space that is specified via an autoencoder. These directions are determined based on gradients with respect to each of the original input features as well as of the target, as estimated in the latent space. The ability to quickly examine combinations of the most promising gradient directions as well as to incorporate additional user-defined constraints allows us to generate multiple counterfactual explanations that are sparse, realistic, and robust to input manipulations. Through experiments on three datasets of varied complexities, we show that FASTER-CE is not only much faster than other state of the art methods for generating multiple explanations but also is significantly superior when considering a larger set of desirable (and often conflicting) properties. Specifically we present results across multiple performance metrics: sparsity, proximity, validity, speed of generation, and the robustness of explanations, to highlight the capabilities of the FASTER-CE family.
FaiR-N: Fair and Robust Neural Networks for Structured Data
Oct 13, 2020

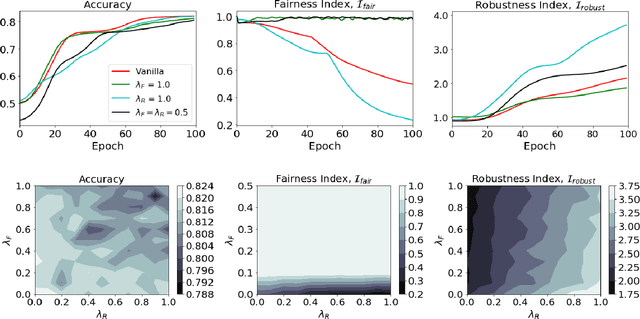
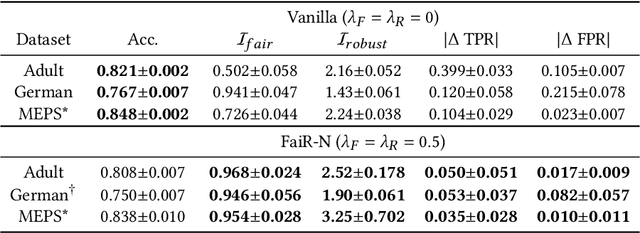
Fairness in machine learning is crucial when individuals are subject to automated decisions made by models in high-stake domains. Organizations that employ these models may also need to satisfy regulations that promote responsible and ethical A.I. While fairness metrics relying on comparing model error rates across subpopulations have been widely investigated for the detection and mitigation of bias, fairness in terms of the equalized ability to achieve recourse for different protected attribute groups has been relatively unexplored. We present a novel formulation for training neural networks that considers the distance of data points to the decision boundary such that the new objective: (1) reduces the average distance to the decision boundary between two groups for individuals subject to a negative outcome in each group, i.e. the network is more fair with respect to the ability to obtain recourse, and (2) increases the average distance of data points to the boundary to promote adversarial robustness. We demonstrate that training with this loss yields more fair and robust neural networks with similar accuracies to models trained without it. Moreover, we qualitatively motivate and empirically show that reducing recourse disparity across groups also improves fairness measures that rely on error rates. To the best of our knowledge, this is the first time that recourse capabilities across groups are considered to train fairer neural networks, and a relation between error rates based fairness and recourse based fairness is investigated.
Explaining Deep Classification of Time-Series Data with Learned Prototypes
Apr 18, 2019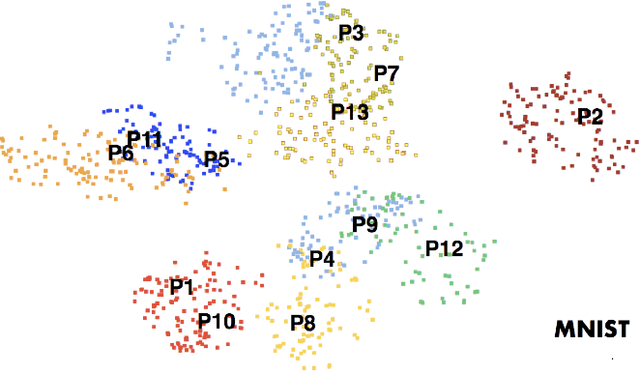

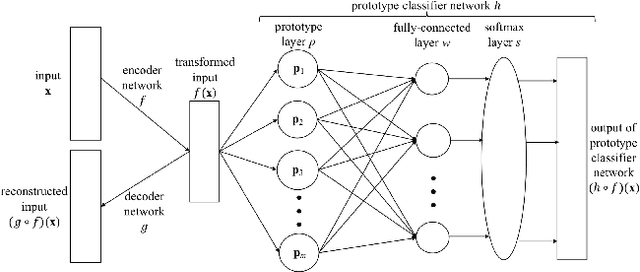
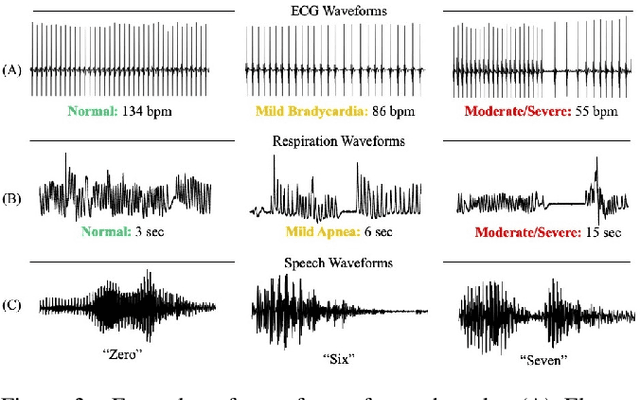
The emergence of deep learning networks raises a need for algorithms to explain their decisions so that users and domain experts can be confident using algorithmic recommendations for high-risk decisions. In this paper we leverage the information-rich latent space induced by such models to learn data representations or prototypes within such networks to elucidate their internal decision-making process. We introduce a novel application of case-based reasoning using prototypes to understand the decisions leading to the classification of time-series data, specifically investigating electrocardiogram (ECG) waveforms for classification of bradycardia, a slowing of heart rate, in infants. We improve upon existing models by explicitly optimizing for increased prototype diversity which in turn improves model accuracy by learning regions of the latent space that highlight features for distinguishing classes. We evaluate the hyperparameter space of our model to show robustness in diversity prototype generation and additionally, explore the resultant latent space of a deep classification network on ECG waveforms via an interactive tool to visualize the learned prototypical waveforms therein. We show that the prototypes are capable of learning real-world features - in our case-study ECG morphology related to bradycardia - as well as features within sub-classes. Our novel work leverages learned prototypical framework on two dimensional time-series data to produce explainable insights during classification tasks.