 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXVir: A Transformer-Based Architecture for Identifying Viral Reads from Cancer Samples
Aug 28, 2023It is estimated that approximately 15% of cancers worldwide can be linked to viral infections. The viruses that can cause or increase the risk of cancer include human papillomavirus, hepatitis B and C viruses, Epstein-Barr virus, and human immunodeficiency virus, to name a few. The computational analysis of the massive amounts of tumor DNA data, whose collection is enabled by the recent advancements in sequencing technologies, have allowed studies of the potential association between cancers and viral pathogens. However, the high diversity of oncoviral families makes reliable detection of viral DNA difficult and thus, renders such analysis challenging. In this paper, we introduce XVir, a data pipeline that relies on a transformer-based deep learning architecture to reliably identify viral DNA present in human tumors. In particular, XVir is trained on genomic sequencing reads from viral and human genomes and may be used with tumor sequence information to find evidence of viral DNA in human cancers. Results on semi-experimental data demonstrate that XVir is capable of achieving high detection accuracy, generally outperforming state-of-the-art competing methods while being more compact and less computationally demanding.
Differentially Private Median Forests for Regression and Classification
Jun 15, 2020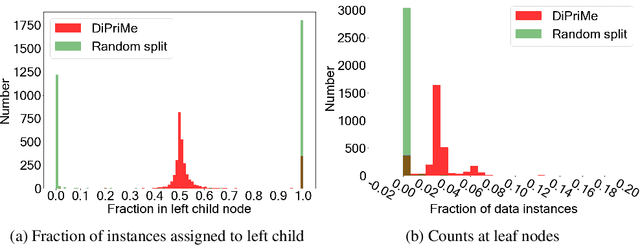

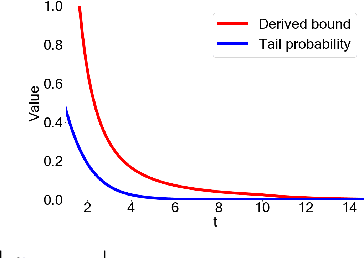

Random forests are a popular method for classification and regression due to their versatility. However, this flexibility can come at the cost of user privacy, since training random forests requires multiple data queries, often on small, identifiable subsets of the training data. Differentially private approaches based on extremely random trees reduce the number of queries, but can lead to low-occupancy leaf nodes which require the addition of large amounts of noise. In this paper, we propose DiPriMe forests, a novel tree-based ensemble method for regression and classification problems, that ensures differential privacy while maintaining high utility. We construct trees based on a privatized version of the median value of attributes, obtained via the exponential mechanism. The use of the noisy median encourages balanced leaf nodes, ensuring that the noise added to the parameter estimate at each leaf is not overly large. The resulting algorithm, which is appropriate for real or categorical covariates, exhibits high utility while ensuring differential privacy.