 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Classifier for Malignant Lymphoma Subtyping via Cell Graph and Image Fusion
Mar 02, 2025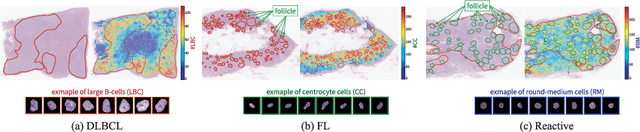
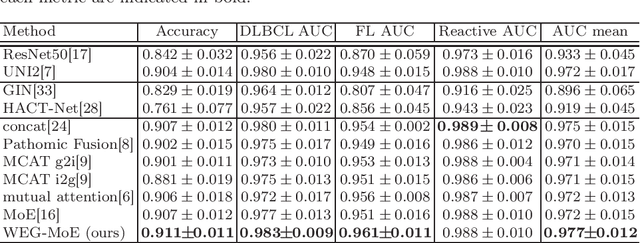
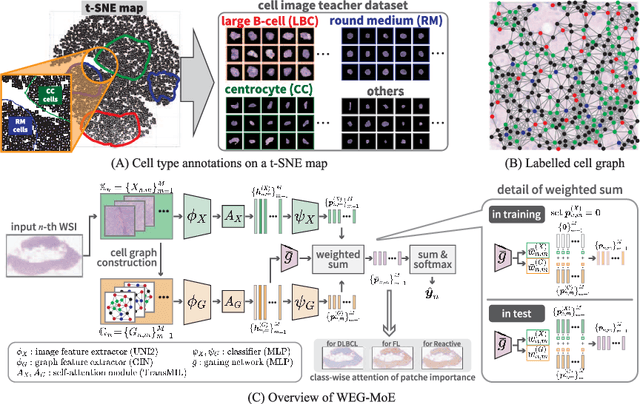
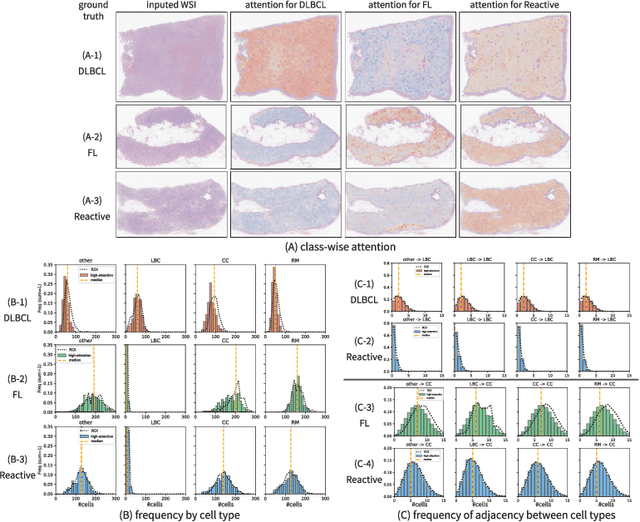
Malignant lymphoma subtype classification directly impacts treatment strategies and patient outcomes, necessitating classification models that achieve both high accuracy and sufficient explainability. This study proposes a novel explainable Multi-Instance Learning (MIL) framework that identifies subtype-specific Regions of Interest (ROIs) from Whole Slide Images (WSIs) while integrating cell distribution characteristics and image information. Our framework simultaneously addresses three objectives: (1) indicating appropriate ROIs for each subtype, (2) explaining the frequency and spatial distribution of characteristic cell types, and (3) achieving high-accuracy subtyping by leveraging both image and cell-distribution modalities. The proposed method fuses cell graph and image features extracted from each patch in the WSI using a Mixture-of-Experts (MoE) approach and classifies subtypes within an MIL framework. Experiments on a dataset of 1,233 WSIs demonstrate that our approach achieves state-of-the-art accuracy among ten comparative methods and provides region-level and cell-level explanations that align with a pathologist's perspectives.
Mixing Histopathology Prototypes into Robust Slide-Level Representations for Cancer Subtyping
Oct 19, 2023Whole-slide image analysis via the means of computational pathology often relies on processing tessellated gigapixel images with only slide-level labels available. Applying multiple instance learning-based methods or transformer models is computationally expensive as, for each image, all instances have to be processed simultaneously. The MLP-Mixer is an under-explored alternative model to common vision transformers, especially for large-scale datasets. Due to the lack of a self-attention mechanism, they have linear computational complexity to the number of input patches but achieve comparable performance on natural image datasets. We propose a combination of feature embedding and clustering to preprocess the full whole-slide image into a reduced prototype representation which can then serve as input to a suitable MLP-Mixer architecture. Our experiments on two public benchmarks and one inhouse malignant lymphoma dataset show comparable performance to current state-of-the-art methods, while achieving lower training costs in terms of computational time and memory load. Code is publicly available at https://github.com/butkej/ProtoMixer.
* The final authenticated publication is available online at https://doi.org/10.1007/978-3-031-45676-3_12
Transformer-based Personalized Attention Mechanism (PersAM) for Medical Images with Clinical Records
Jun 07, 2022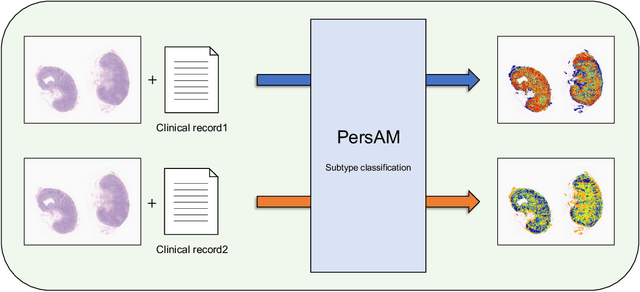
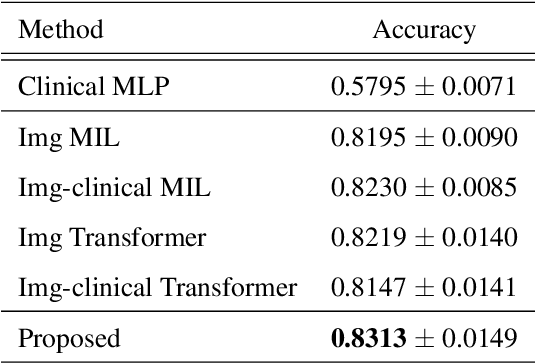
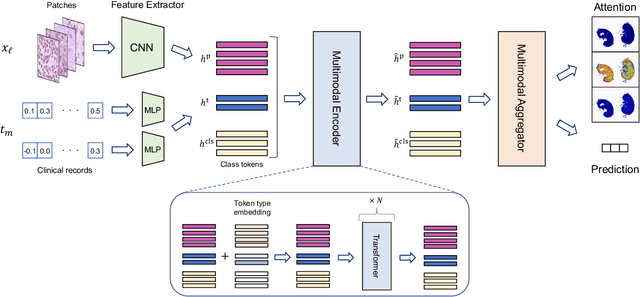
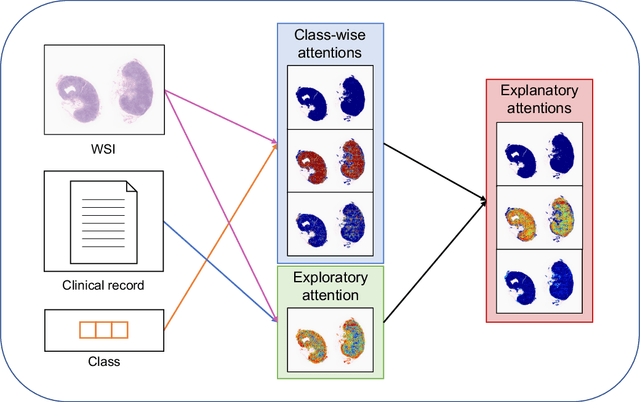
In medical image diagnosis, identifying the attention region, i.e., the region of interest for which the diagnosis is made, is an important task. Various methods have been developed to automatically identify target regions from given medical images. However, in actual medical practice, the diagnosis is made based not only on the images but also on a variety of clinical records. This means that pathologists examine medical images with some prior knowledge of the patients and that the attention regions may change depending on the clinical records. In this study, we propose a method called the Personalized Attention Mechanism (PersAM), by which the attention regions in medical images are adaptively changed according to the clinical records. The primary idea of the PersAM method is to encode the relationships between the medical images and clinical records using a variant of Transformer architecture. To demonstrate the effectiveness of the PersAM method, we applied it to a large-scale digital pathology problem of identifying the subtypes of 842 malignant lymphoma patients based on their gigapixel whole slide images and clinical records.
Case-based similar image retrieval for weakly annotated large histopathological images of malignant lymphoma using deep metric learning
Jul 09, 2021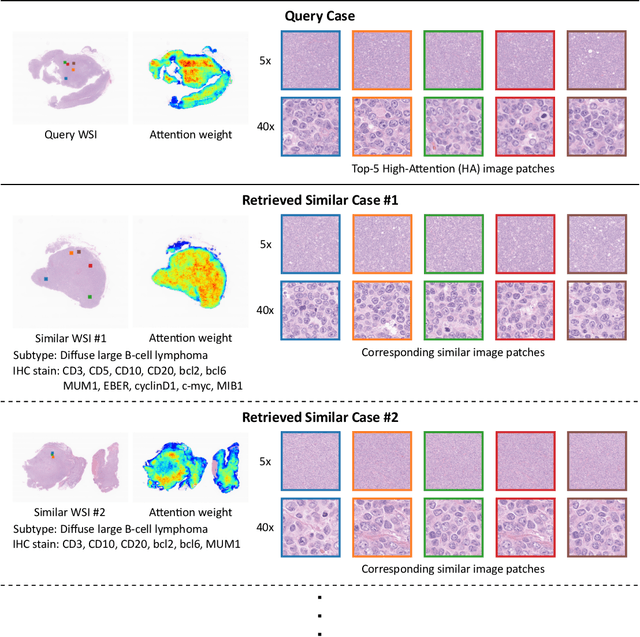
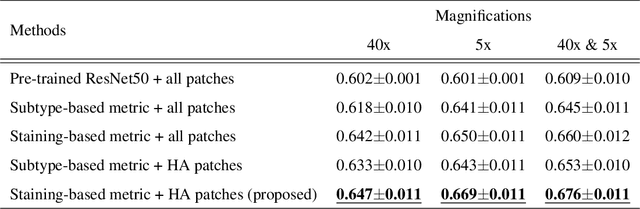
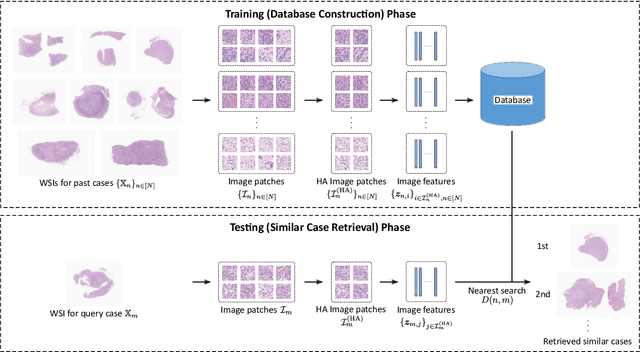
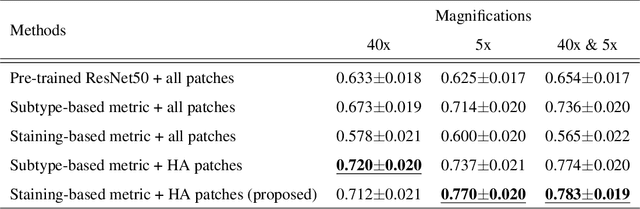
In the present study, we propose a novel case-based similar image retrieval (SIR) method for hematoxylin and eosin (H&E)-stained histopathological images of malignant lymphoma. When a whole slide image (WSI) is used as an input query, it is desirable to be able to retrieve similar cases by focusing on image patches in pathologically important regions such as tumor cells. To address this problem, we employ attention-based multiple instance learning, which enables us to focus on tumor-specific regions when the similarity between cases is computed. Moreover, we employ contrastive distance metric learning to incorporate immunohistochemical (IHC) staining patterns as useful supervised information for defining appropriate similarity between heterogeneous malignant lymphoma cases. In the experiment with 249 malignant lymphoma patients, we confirmed that the proposed method exhibited higher evaluation measures than the baseline case-based SIR methods. Furthermore, the subjective evaluation by pathologists revealed that our similarity measure using IHC staining patterns is appropriate for representing the similarity of H&E-stained tissue images for malignant lymphoma.