 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Histopathology Prototypes into Robust Slide-Level Representations for Cancer Subtyping
Oct 19, 2023Whole-slide image analysis via the means of computational pathology often relies on processing tessellated gigapixel images with only slide-level labels available. Applying multiple instance learning-based methods or transformer models is computationally expensive as, for each image, all instances have to be processed simultaneously. The MLP-Mixer is an under-explored alternative model to common vision transformers, especially for large-scale datasets. Due to the lack of a self-attention mechanism, they have linear computational complexity to the number of input patches but achieve comparable performance on natural image datasets. We propose a combination of feature embedding and clustering to preprocess the full whole-slide image into a reduced prototype representation which can then serve as input to a suitable MLP-Mixer architecture. Our experiments on two public benchmarks and one inhouse malignant lymphoma dataset show comparable performance to current state-of-the-art methods, while achieving lower training costs in terms of computational time and memory load. Code is publicly available at https://github.com/butkej/ProtoMixer.
* The final authenticated publication is available online at https://doi.org/10.1007/978-3-031-45676-3_12
Deep Neural Networks for the Correction of Mie Scattering in Fourier-Transformed Infrared Spectra of Biological Samples
Feb 18, 2020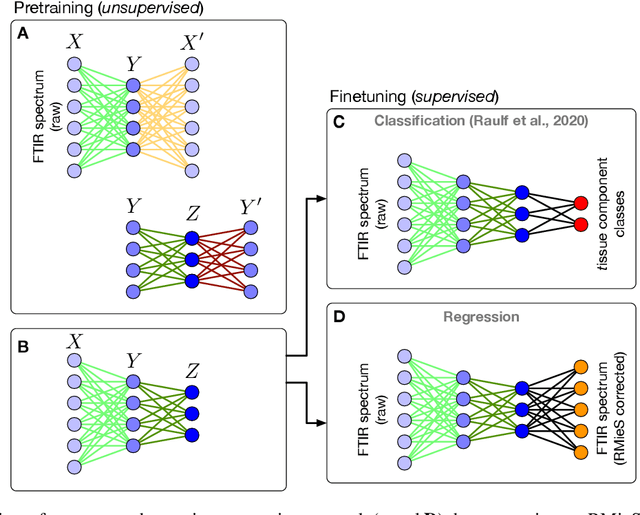


Infrared spectra obtained from cell or tissue specimen have commonly been observed to involve a significant degree of (resonant) Mie scattering, which often overshadows biochemically relevant spectral information by a non-linear, non-additive spectral component in Fourier transformed infrared (FTIR) spectroscopic measurements. Correspondingly, many successful machine learning approaches for FTIR spectra have relied on preprocessing procedures that computationally remove the scattering components from an infrared spectrum. We propose an approach to approximate this complex preprocessing function using deep neural networks. As we demonstrate, the resulting model is not just several orders of magnitudes faster, which is important for real-time clinical applications, but also generalizes strongly across different tissue types. Furthermore, our proposed method overcomes the trade-off between computation time and the corrected spectrum being biased towards an artificial reference spectrum.